弱标签下视听目标检测-识别、定位、分离(论文解读)
弱标签数据下的视听场景分析是一个很值得研究的问题,今天要说的这篇Identify, locate and separate: Audio-visual object extraction in large video collections using weak supervision是在论文作者已发表的论文Weakly Supervised Representation Learning for Unsynchronized Audio-Visual Events基础上的改进版本。我们将通过本次博客分析这两篇论文是如何在视听场景分析下实现场景识别、声音分离和声源定位的。
论文引入
无论是铃声电话还是来往的车辆,人类都能立即识别出这些事件特征的视听(AV)组件。这种卓越的能力有助于我们理解环境并与之互动。机器去理解这种场景的话,设计用于从真实世界数据学习视听表示的算法是很重要的。从视听信息中提取事件、目标、声音以及场景判断在视频监控,多媒体索引和机器人等多个领域中具有重要的应用。总的来说声视场景的分析需要包含:1)识别事件或对象 2)在空间和时间中定位它们 3)在场景中提取希望得到的音频。
对于算法的实现上,大量的视听场景数据是必要的,在多媒体如此发达的现代,这类数据是庞大的,但是和数据匹配的标注信息是缺乏的。昂贵的信息标注一直是机器学习发展的阻碍物,标注过程不仅容易出错且耗时,而且在一定程度上也是主观的。通常,音频中的事件边界,视频对象的范围甚至它们的存在都是模糊的。因此,论文Weakly Supervised Representation Learning for Unsynchronized Audio-Visual Events选择使用仅具有视频级事件标签的数据的弱监督学习方法,即没有整个视频文档的时间的标签也无具体内容的标注。
Weakly Supervised Representation Learning for Unsynchronized Audio-Visual Events一文将视频分解为图像区域和时间音频片段,在单独对视觉和音频子模块中处理每个视频,最后根据处理得到的视觉分类得分和听觉分类得分最终对场景进行分类。这个过程由下图所示:
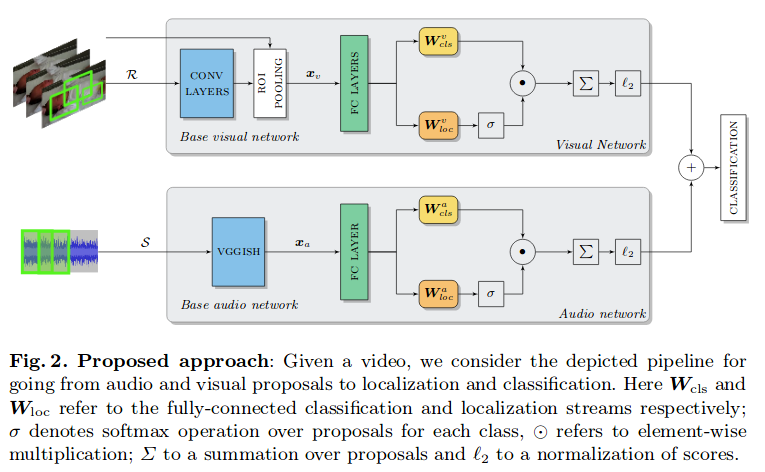
可以看到对于音频处理上,是将音频进行时间上的分段,提取得到$S=\lbrace s_1, s_2,…,s_T \rbrace$再送入音频处理网络。但这种音频方案设计有两个缺点:(i)在噪声声学条件下容易出现错误的分类,(ii)仅限于时间定位,音频事件或对象不允许进行时频分割,无法分离出希望得到的音频源。我们今天要解读的Identify, locate and separate: Audio-visual object extraction in large video collections using weak supervision正是原团队在之前的基础上对音频处理上的改进,其它部分是一样的,所以我们将主要分析后一篇论文。
总结一下论文的优势:
- 通过视听场景分析对事件进行合理分类
- 通过音频处理上对音频的分离处理,增强了原有系统的鲁棒性
- 在视听场景弱标记数据集上定量和定性地验证系统的性能
NMF介绍
后一篇论文正是在音频处理上进行了改进,主要是引入了NMF对音频进行了音频分离。NMF是一种流行的无监督音频分解方法,已成功应用于各种声源分离系统,并作为音频事件检测系统的前端。它将音频频谱图分解为两个非负矩阵,即所谓的频率图及时间表示图。这种基于部分的分解类似于将图像分解成构成对象区域,同时这种思想正是促使论文改进方案的设计。它不仅可以对音频进行去噪,还可以将混合音频适当地组合起来进行分离。
在The Sound of Pixels一文中,论文利用U-Net在真实掩码的训练下实现了声音的分离,这个方法的源头也是受到NMF的方法启发,这个我们在论文解读的博客中也有所提及。只依赖于弱标签进行声音的分离是Identify, locate and separate: Audio-visual object extraction in large video collections using weak supervision的一个创新点。
利用NMF可将声音的频谱图分解由F频率区和N个短时傅里叶变换(STFT)帧组成的音频幅度谱图$Q \in \mathbb R_{+}^{F \times N}$,即:
\[Q \approx WH\]其中$W \in \mathbb R_{+}^{F \times K}$是分解得到的频率矩阵,是分解得到的频率矩阵,$H \in \mathbb R_{+}^{K \times N}$是分解得到的时间表示矩阵,这里的是分解得到的时间表示矩阵,这里的$K$是指分离出的音轨数量。这个过程可以用下图近似表示:
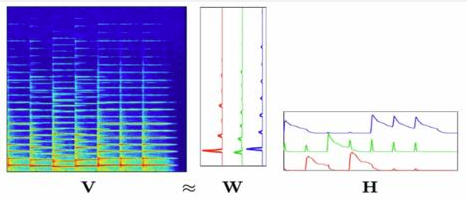
音轨K对应着$W_k$和$H_k$,将每个音轨进行时间段的划分,论文称之为NCP,NCP的集合记为$\mathcal D = \lbrace d_{k ,t} \rbrace$。这里的$k \in [1, K], t \in [1,T]$
模型框架
介绍完NMF后,我们对论文实现的模型框架进行分析:
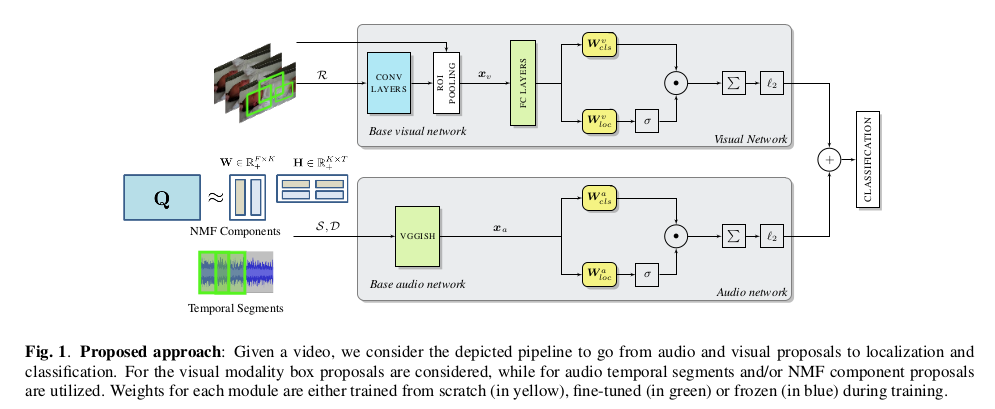
不同于第一篇论文,这个模型的输入端音频有一个NMF的处理过程。整体分析一下这个模型,首先分为上下路对视频进行视觉特征提取和分类得分输出,视觉特征提取和分类得分输出,最后将分类得分进行相加得到最终的分类得分,从而确定场景的最终分类。大模型只代表整体思路,接下来,我们去分析每一块的具体实现。
视觉模块处理
分析图像中的对象是各种视觉目标检测算法的核心,这篇论文的目标是在空间和时间上定位与类相关的最具辨别力的区域,并将该技术应用于子采样视频帧序列。以每秒1帧的速率对每个视频的提取帧进行子采样,使用EdgeBoxes对子采样图像对象进行框注。完全在框内的轮廓表示对象存在的可能性,这也是通过实验证明在大多数竞争技术的速度/精度方面具有好的性能。EdgeBoxes还为每个边界框生成一个置信分数,它反映了框的“对象性”。为了减少计算负荷和冗余,选择置信分数最高的对象将其用于特征提取。因此,给定10秒的视频,上述操作将保留下$M = 10 \times M$图像区域框图,特征提取得到特征向量$x_v$,$x_v$是从V中的每个图像区域$r_m$通过感兴趣区域(RoI)池层的卷积神经网络获得的。
$x_v$再通过两个全连接层,通过双流(twostream)架构,该模块的体系结构包括并行分类和定位流。前者通过使特征通过具有权重$W_{cls}$的线性全连接层来分类每个区域,得到矩阵$A \in \mathbb R^{\vert \mathcal p \vert \times C}$。另一方面,定位层通过权重$W_{loc}$通过另一个全连接层传递相同的输入。然后对定位流中的结果矩阵$B \in \mathbb R^{\vert \mathcal p \vert \times C}$进行softmax操作。
最后,分类流输出$A$通过$\sigma (B)$通过逐元素乘法加权:$D = A \odot \sigma (B)$。通过将$D$中的结果加权分数与类别得分相加来获得视频上的分数。在训练中图像允许区域或段属于多个类,因此不在分类流上选择softmax。
听觉模块处理
首先将原始音频波形表示为log-Mel谱图,接下来就是处理音频的重要环节了,论文给出了两种处理音频的方法,其中第二种是论文的改进版,也就是我们之前提到的NMF操作。
1.时间段(Temporal Segment Proposals (TSP)):音频被简单地分解为相等长度的T个时间段$S=\lbrace s_1, s_2,…,s_T \rbrace$,log-Mel频谱图通过沿时间轴滑动固定长度窗口来对其进行分块而获得的。
2.NMF分量建议(NMF Component Proposals (NCP)):使用NMF,我们分解由F频率区和N个短时傅里叶变换(STFT)帧组成的音频幅度谱图,具体的细节我们在前面的NMF中有过介绍。
两种方法处理完的音频都在VGGISH下做特征提取得到特征向量$x_a$,接下来的操作和视觉处理模块类似。最后,视觉和听觉分数经过$l2$归一化后相加得到最后的分类分数。
训练和损失
给定一组N个训练视频和标签$\lbrace V(n), y(n) \rbrace$,这里$y \in \mathcal y = \lbrace -1, +1 \rbrace^C$,类的存在由+1表示,缺少由-1表示。对于每个视频$V(n)$,网络将一组图像区域R(n)和音频段TSP下$S(n)$或NCP下$D(n$)作为输入。在分别对每个模态执行所描述的操作之后,添加$l2$归一化分数并由$\phi (V(n);w) \in \mathbb R^C$表示,其中所有网络权重和偏差由w表示。对于两种模态,包括和遵循全连接层处理阶段的所有权重都包括在w中。两个子模块都是联合培训的,并且使用多标签铰链损失训练网络:
\[L(w) = \frac{1}{CN} \sum_{n=1}^N \sum_{c=1}^C max(0,1-y^{(n)} \phi_c(V^{(n)};w))\]论文在处理音频上还进行了源增强操作,感兴趣的可以进一步阅读原文了解。
实验
此处的实验部分主要介绍引入NMF的这篇论文的实验,毕竟是最近的文章。
在数据集的选择上,论文使用了Kinetics-Instruments(KI),这是Kinetics数据集的一个子集,其中包含来自15个乐器类的10s Youtube视频。在总共10,267个视频中,分别创建了包含9199和1023个视频的训练和测试集。对于源增强评估,挑选了45个“干净”的乐器录音,每种3个。由于它们不受约束的性质,音频记录大多是有噪声的,即视频是用伴随的音乐/乐器拍摄的,或者是在包含其他背景事件的声学环境中拍摄的。在这种情况下,“干净”指的是具有最小量这种噪声的独奏乐器样本。
在实验上,论文仅在音频A下的实验记为A,仅在视觉下记为V,视听结合记为V+A。在使用音频处理上,仅仅使用TSP、仅使用NCP以及两者一起使用(TCP,NCP)。
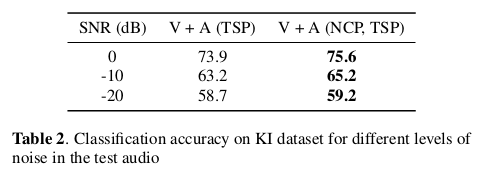
在分类准确率上,NCP展示了更加优越的效果:
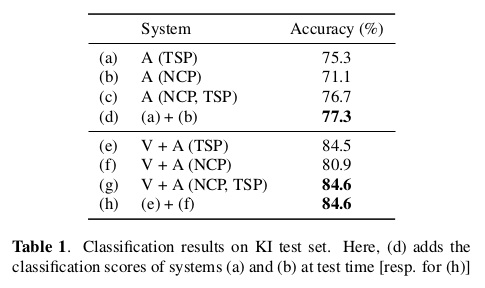
在不同的信噪比下同样展示了NCP的较强的鲁棒性:
对于乐器的视觉定位上,我们定性看一下实验的效果:

总结
论文作者在早期工作的基础上对音频的处理进行了NMF的分离增强处理,不仅实现了音频的分离同时使得视听场景分析更具有鲁棒性。论文如它的标题一样,在理论上是做到了识别、定位和分离,对视听场景分析很有借鉴意义,在弱标签下处理视频的多实例学习也是对数据标注昂贵一种合理的处理方式。

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







