Attention增强视听觉同步判断
音频和视频的同步是检验一场多媒体演示质量好坏的关键因素,这就像是没人希望花钱看一场音频和视频不对应的电影。然而多媒体演示的过程中,音频和视频信号通常由独立的工作流程管理 ,分开创作,处理,存储甚至传送到回放系统。这种独立操作增大了音视频同步性的考验,之前博客中分析的语义关联判断的AVC和时序关联的AVTS都是对音视频关联性判断的方法。今天介绍的On Attention Modules for Audio-Visual Synchronization是将Attention应用在音视频时序同步性的判断。
论文引入
在大部分多媒体演示中,音频和视频信号由独立的工作流程管理。在高价制作的优质内容(如电影)的情况下尤其如此。然而从原始音频和视频的拍摄到后期制作上存在大量认为的操作,这里涉及到视频编辑(决定原始素材的哪些部分将用于完成的工作),数字特效(为视频和音频独立创建)以及声音母带制作和混合。这些后期操作很可能带来音视频时序上不同步的问题。此外,用于全球发行的影视材料通常具有对应于不同国际语言的若干音轨。这就需要在视频和主要语言音频已经完成后创建配音音轨。所有这些都开启了音频和视频之间时间错位的可能性。制作电影所涉及的高成本以及目标观众的大小保证了高的多媒体质量,需要音频和视频媒体之间的紧密同步。
人类非常有能力确定多媒体演示的音频和视频信号是否同步,甚至可以无缝地实现视频中何时何地注意,以便能够判断音频和视频之间是否存在错位。人类经常密切关注时空细节,例如观看电影时人类的嘴唇运动,并仅根据这些线索做出同步性的判断。同时,当我们无法在视觉内容(例如,电影场景中的背景音乐)中找到声音的来源时,我们忽略视频大部分时空部分去处理关注重要细节,这使我们能够有更好的判断力。总之,当人类发现音视频不同步时,我们会感觉很难受,看着别扭,这也与我们人类在大量视听觉关联事例上已经建立了强烈的音视频时序关联的意识。
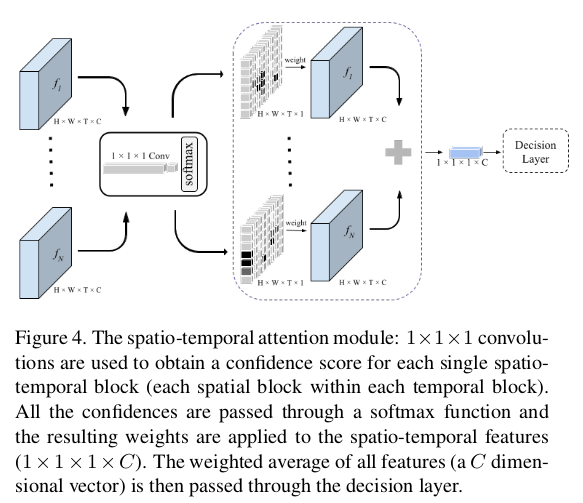
On Attention Modules for Audio-Visual Synchronization将Attention引入到音视频同步性判断上,我们后文简称为Attention AVS。在模型中引入了时间注意模块和时空注意模块,时间注意模块关注的是视觉特征和听觉特征混合后得到的融合特征在时序上权重的分配;时空模块则是关注融合特征在每一个局部块上的权重分配。确定了权重,在决策层按照权重计算进行决策输出。这个过程我们用下图进一步理解,时间注意模块关注的是视频时序上的权重分配,时空模块关注的是视频局部的权重分配:
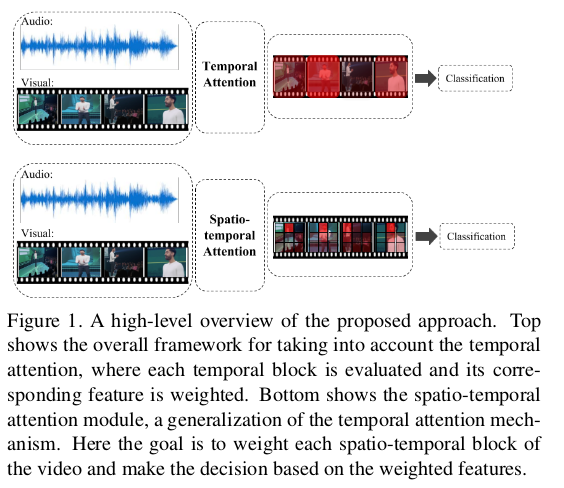
总结一下Attention AVS一文的优势:
- 提出了一种基于注意力的框架,以自我监督的方式训练,用于视听同步判断
- 设计了时间注意模块和时空注意模块,增加了音视频同步性判断的准确率
- 在定量和定性上都展示了优越的实验结果
模型结构
我们先从整体上看一下Attention AVS的模型设计:
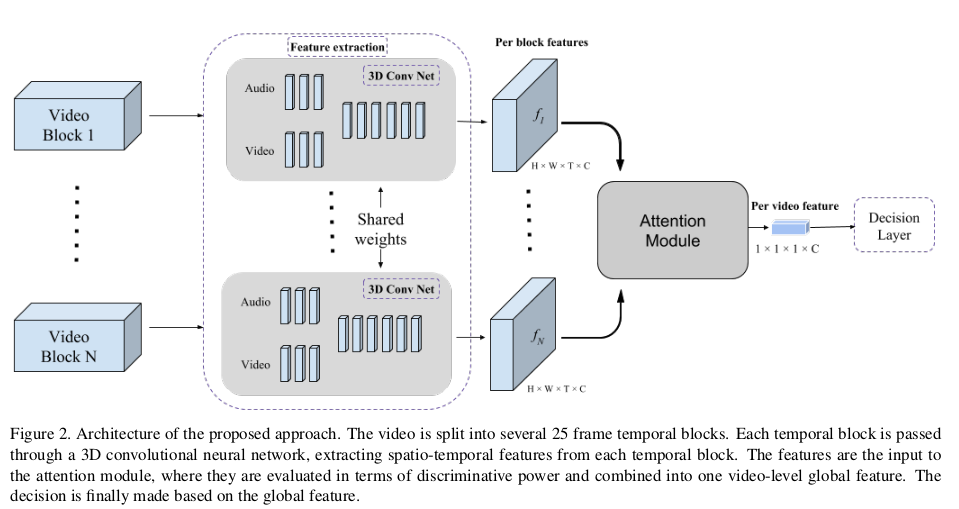
对于输入的视频,将它分为以25帧为一段的N段非重叠视频块(对于原文处理上,帧速率为29.97,大约为0.8秒),这里记为$B_1,B_2,…,B_N$。对每一块视频段做音频和视觉的分离,再分别提取对应的特征(后续展开说),对提取好的特征做视听特征融合进行联合表示,得到联合特征$f_1,f_2,…,f_N$。将联合特征送入到Attention模块做权重分配,最后送至决策层做决策输出。
接下来,我们详细分析模型结构中的每一部分,可以分为:特征提取和联合特征表示、注意力模块。
特征提取和联合特征表示
论文对视频块下音频和视频进行特征提取是参考Audio-Visual Scene Analysis with Self-Supervised Multisensory Features一文中的网络设计,论文也是直接用了这篇论文的预训练权重。
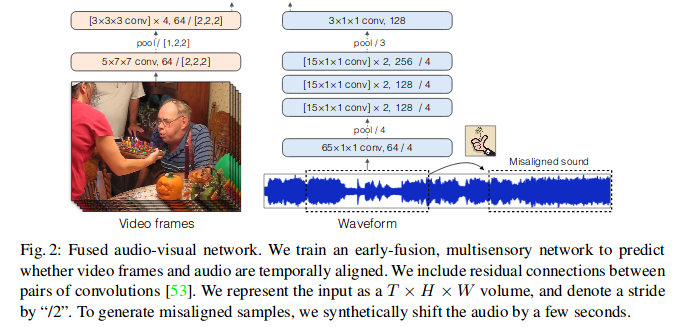
对于视频信息得到特征$H \times W \times T \times C_v$,音频信号得到特征$T \times C_a$,这里值得一说的是对于音频信号特征提取是直接对原始音频进行处理的,而目前很多文章都是将音频转换为声谱图再进行分析的。对于音频特征进行复制$H \times W$次后与视觉特征在channel上进行拼接,即$C=C_v + C_a$,从而得到联合特征表示$H \times W \times T \times (C_v + C_a)$尺寸张量。网络之后是5个卷积层,应用于连接的特征,组合两个模态并产生联合表示。
注意力模块
论文设计了两种注意力模块,分别为时间注意模块和时空注意模块。
时间注意力模块
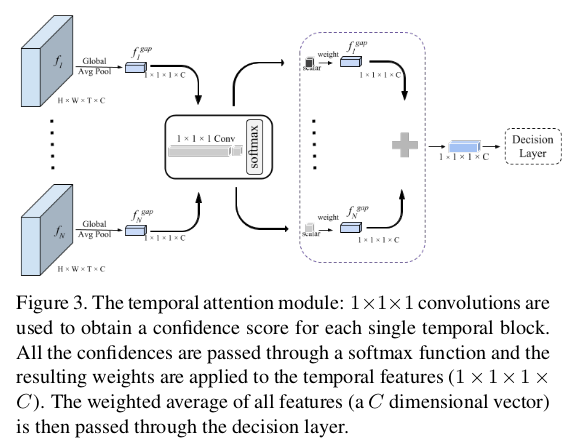
对于联合特征表示得到的$f_1,f_2,…,f_N$中的每一个进行全局平均合并处理,即把特征张量为$H \times W \times T \times C$经过全局平局池化得到$1 \times 1 \times 1 \times C$维度的特征$f_i^{gap}$。使用单个全局特征向量$f_i^{gap}$表示视频的每个块。在全局平均合并特征上应用$1 \times 1 \times 1 \times$卷积,得到每个时间块$B_i$下单个标量置信值$C_i$。$C_i$的置信值直观地捕获了特定时间块的重要性,对同一视频的不同时间块的所有置信值应用softmax归一化函数,我们为每个特征$f_i^{gap}$获得权重$w_i$。特征$\sum_i w_i f_i^{gap}$的加权平均值被传递到决策层,整个过程如下图所示。
时空注意力模块
对于时空关注模块,我们将$1 \times 1 \times 1 \times$卷积层直接应用于$H \times W \times T \times C$维度特征,从而为每个块生成一组置信值$C_{H \times W \times T}$。然后,我们在所有块的所有置信值($H \times W \times T$标量值)中执行归一化处理。基于时空特征$\sum_{n=1}^N \sum_{i=1}^T \sum_{j=1}^H \sum_{k=1}^W w_{nijk} f_n^{ijk}$的加权平均值做出决定,其中$f_n^{ijk}$是在时间块n处从单个空间块$i,j,k$提取的特征向量,也就是局部的特征表示,整个过程如下图所示。
实验
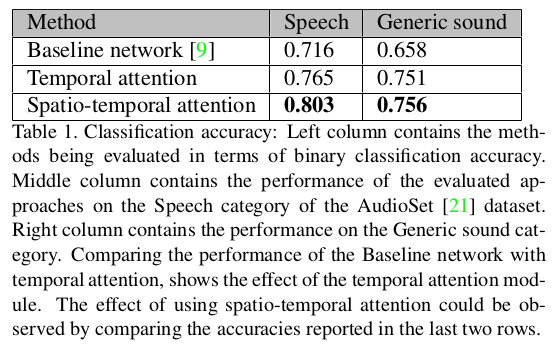
文章对比的基线是上文提到的Audio-Visual Scene Analysis with Self-Supervised Multisensory Features一文。所选用的数据集为公开的 AudioSet,该数据集包含632个音频事件类别的本体。文章在数据集的语音子集的3000个示例上训练时间和时空模块,并在7000个语音数据集示例上测试所提出的方法,并从通用冲击声音类别中测试800个示例,以进一步显示论文的方法对声音的稳健性诸如打破,打击,弹跳等。论文将每个视频用作正面示例,并将视频的未对齐版本作为反面示例。
在定量上通过和基线进行视频同步性判断准确率作为衡量指标,时空注意力模块在语音和通用声音类都取得了最佳的同步性判断准确率。
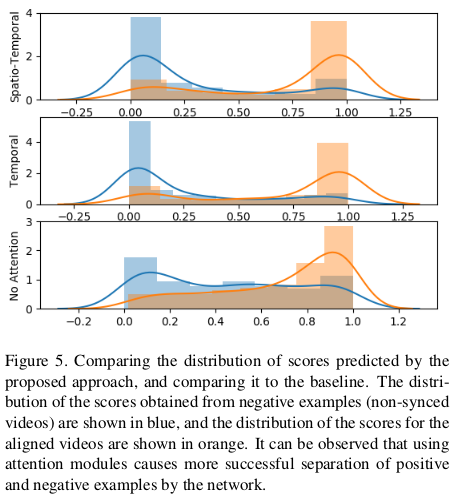
为了进一步说明注意模块的效果,论文绘制并比较了分类网络的输出分数的分布。如下图所示,可以看出,注意模块有助于更好地分离两类同步和非同步数据分布。
在定性评估上,论文可视化网络估计的权重的一些示例。时间注意力的两个例子如下图所示(每类数据集一个)。在每个示例中,每行包含一个时间块。同时还显示每个时间块的分数。正如可以观察到的那样,在左边的例子中,已经为鞋子敲击地面的信息时刻分配了高权重。在右边的示例中,演员发出单词的时刻被选为最具信息性的部分。

在时空注意模块下,下图显示了在相同示例中从时空模块获得的权重。可以观察到,网络正确地将更高的值分配给视频的更多区别区域(例如,鞋子轻敲地板,以及扬声器面对)。

总结
论文研究了将时间和时空关注模块纳入视听同步问题的效果。通过实验表明,简单的时间注意模块可以在视频中对同步音频和非同步音频和视频内容进行分类方面获得实质性收益。此外,更一般的时空关注模块甚至可以实现更高的准确度,因为它还能够关注视频的更具辨别力的空间块。可视化由时间和时空关注模块生成的权重,可以观察到视频的判别部分被正确地赋予更高的权重。注意力机制的引入,在音视频的同步性展示了一定的优势,注意力的引入更像人类去认知音视频同步的方法。

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







