AVTS论文解读
视觉和听觉存在着紧密的关联,同时空下视觉和听觉不仅在语义上存在着一致性,在时序上也是对齐的。失聪患者可以利用视觉信息做出判断,盲人也可以利用听觉信息做出判断,而一般正常人对事物的决策往往是结合视觉和听觉协同完成的。NIPS2018的Cooperative Learning of Audio and Video Models from Self-Supervised Synchronization正是通过对视觉和听觉信息做同一性判断,在整体上优化视觉特征和听觉特征提取网络,在独立模态下也提高了各自的任务准确率。不同于我们之前说的Look,Listen and Learn,这篇论文不仅仅在语义上判断视觉和听觉的一致性,还在时序上做了严格对齐判断。
论文引入
日常休闲娱乐很多人喜欢看电影,有时看电影的过程中会出现画面和音频对不上的情况,这会大大降低观影体验。为什么我们会察觉到画面和音频对不上呢?这就是人类潜意识里已经建立了视觉和听觉上对应的关系,一旦客观现象中视觉和听觉信息对应不上,我们立马就会发现哪里出现了问题。人类不仅仅可以察觉画面和音频对应不上,结合已有的知识甚至可以推断是画面延迟了还是音频延迟了。
目前机器学习大部分还是停留在单一模态下信息的分析和学习,比如计算机视觉是一个大的研究方向,音频分析和处理又是一个方向。然而,机器如果想更进一步的智能化,必须要像人类一样,利用多模态去分析和学习,结合不同模态下的信息和联系做出判断和决策。已经有越来越多的研究者关注到了多模态信息的学习,跨模态检索、迁移学习、多模态信息联合决策、跨模态转换等。视觉和听觉这两个模态,本身就是严格关联的,只要物体运动了,视觉上的变化势必会带来听觉上声音的产生,如何结合视觉和听觉信息去提高视觉任务和听觉任务的处理,正是我们今天要看的这篇论文的核心。
如何去结合视觉和听觉信息呢?论文采用的方式是“视听觉时间同步”英文缩写为AVTS(Audio-Visual Temporal Synchronization),就是在语义和时序上对视觉和听觉信息做对齐判断,如果视觉信息和听觉信息不仅在语义上是关联的(视频和声音是可以对上的)而且在时序上也是对齐的(视频和声音不存在延迟,是对齐关系的)就判断为同步信息,否则认为是非同步。优化决策结果,则会提高视觉和听觉特征提取网络,特征提取好了自然在独立的任务上可以取得改善。
我们在之前的论文解读中对Look,Listen and Learn一文简称为$L^3Net$做过分析,$L^3Net$也是对视觉和听觉信息做关联性判断,但是判断视觉和听觉关联上仅仅是通过语义上是否关联判断的,而论文AVTS则是在此基础上考虑到视频的时序信息,进一步严格了视觉和听觉的同步性判断。
利用视频和音频之间的相关性作为特征学习的方法,在训练过程中是不引入人为标签的,拿来视频和音频只需要知道是否是同步的不需要任何其它的标签就可以优化整体网络,这种方式符合自监督学习方法,所以论文的标题特意强调文章是在自监督下完成同步性判断的。这对于处理视频这样的大数据集是可观的,一旦利用AVTS自监督方式预训练好特征提取网络可以在微调阶段发挥出更好的效果的同时,不引入额外的标注开销。
总结一下AVTS的优势:
- 视觉听觉在语义和时序同步性判断
- 视听觉相关性判断,实现了自监督学习特征提取
- 预训练AVTS模型在视觉信息和听觉信息独立任务上取得了提高
AVTS模型
AVTS模型是对视觉信息和听觉信息在语义和时序上同步性的判断,判断结果是二分类问题,要么同步要么不同步,我们先看一下模型框架:
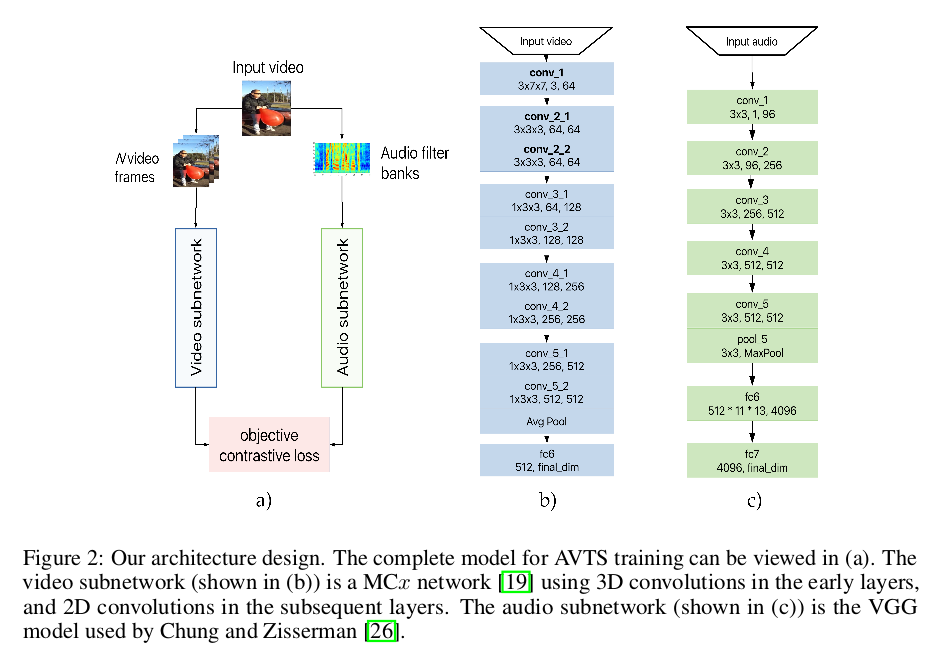
由上图(a)所示,AVTS模型采取的是双流结构,一路是视频特征提取网络,一路是音频特征提取网络,对提取得到的特征利用对比度损失进行优化。整体上看AVTS还是很容易理解的,我们要强调一下具体的实现。
我们先从模型优化的训练集说起。
整体训练集定义为$\mathcal D = \lbrace (a^{(1)},v^{(1)},y^{(1)}),…,(a^{(N)},v^{(N)},y^{(N)}) \rbrace$由$N$个标记的音频视频对组成。其中$a^{(n)}$表示音频第$n$个样本,$v^{(n)}$表示视频第$n$个样本(视频由连续帧组成),标签$y^{(n)} \in \lbrace 0,1\rbrace$表示视频和音频是否同步,0为不同步,1为同步。
训练集选择同一视频下时序对应的视频和音频为同步的正例,对于负例,定义不同视频下视频和音频为简单负例,同一视频下时序不同步的为硬(“hard”)负例,硬负例下时序相差太远的定义为超硬负例,我们由下图可以进一步理解正负例定义原则。
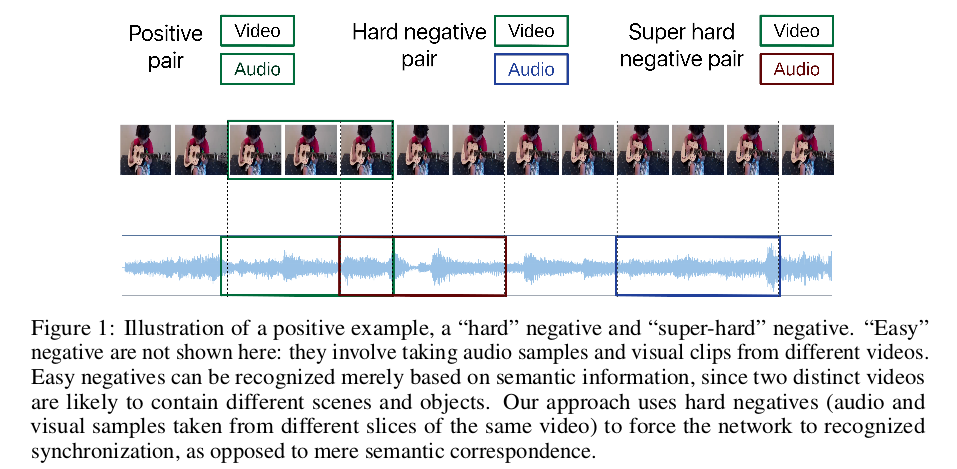
优化AVTS模型中,论文作者一开始直接采用交叉熵损失进行优化,发现从头开始学习时很难在这种损失下实现模态间的融合,通过最小化对比度损失可以获得更一致和稳健的优化,在正对上产生小距离,在负对上产生更大距离:
\[\begin{equation} E = \frac{1}{N} \sum_{n=1}^N (y^{(n)}) \Vert f_v(v^{(n)} - f_a(a^{(n)} \Vert_2^2) + (1-y^{(n)})max(\eta-\Vert f_v(v^{(n)} - f_a(a^{(n)} \Vert_2,0)^2 \end{equation}\]其中$f_v(v^{(n)})$为视频提取的特征表示,$f_a(a^{(n)})$为音频提取的特征表示,对于标签$y^{(n)} = 1$时,此时最小化对比度损失E时需要$f_v(v^{(n)})$与$f_a(a^{(n)})$尽可能相近,也就是希望同步的视频特征和音频特征尽量相近。对于非同步的视频-音频对,即$y^{(n)} = 0$时,对应到公式的后一项,只有当$f_v(v^{(n)})$与$f_a(a^{(n)})$距离越远的时候,$\eta - \Vert f_v(v^{(n)} - f_a(a^{(n)} \Vert_2$才会比0要小,此时max达到最佳值0,其中$\eta$为边际超参数。
对于视频特征提取网络(b),文章采用2D和3D卷积网络结合实现,我们简单分析一下3D卷积网络,对于(b)图中对应的是前2个卷积块,后3个卷积块为2D卷积网络,最后一层为全连接层。3D卷积网络下视频输入是包含帧的,这里输入的视频帧为3,长宽为$7 \times 7$,通道数为3,batchsize为64。论文解释为在特征提取的后半部分将不再依靠时间轴,这时候可以直接利用2D卷积网络,论文称这种方法为混合卷积架构(MC),实验也验证了混合架构性能要好些。
对于音频信息,先要对音频信息提取对应的声谱图然后再对其利用2D卷积网络做特征提取,网络结构为(c)图展示。
课程方式训练
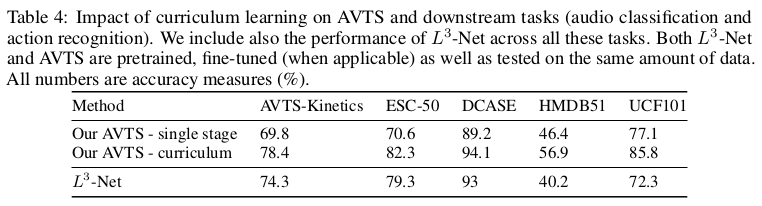
论文在训练模型的时候发现,如果一开始对负例的选择上简单负例和硬负例按3:1训练时,训练效果很一般。论文认为一开始让模型去区分硬负例有些太难了,文章采用循序渐进增进难度的方式。论文实验发现在前50个epoch下负例只选择简单负例,在51-90epoch下简单负例和硬负例按3:1训练时,模型效果最佳。这个也符合人类的学习方式,一上来就做难题不仅打击自信,基础也不能打扎实,只有掌握了充分的基础知识后,再做些难题才能锦上添花。论文对比了设置课程的效果:

实验
训练上边际超参$\eta$为0.99,训练在四块GPU机器上完成,每个GPU有一个小批量的16个样本。每次损失值在超过5个时期内没有减少时,学习率将缩放0.1。
在验证视觉信号和听觉信号同步性问题,论文做了与$L^3Net$的对比,:
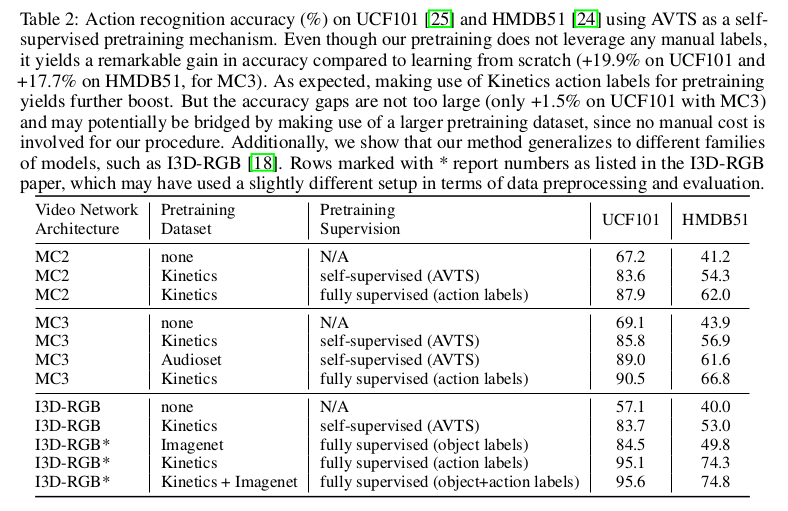
在评估视觉特征性能时,正如预期的那样,使用动作类标签对Kinetics数据集进行预训练可以提高UCF101和HDMB51的准确度。但是,这会占用500K视频剪辑上手动标记的巨大成本。相反,AVTS预训练是自监督的,因此它可以应用于更大的数据集而无需额外的人工成本。
在评估听觉特征性能时,直接在音频特征提取的conv_5 AVTS功能上训练多类一对一线性SVM,以对音频事件进行分类。通过对样本中的分数求平均来计算每个音频样本的分类分数,然后预测具有较高分数的类。
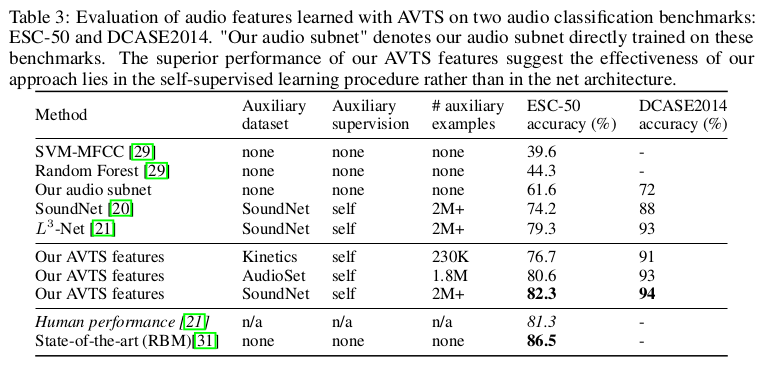
可以看到,AVTS在音频分类任务上取得了比人工稍好的效果。
更多实验,可以进一步阅读原文。
总结
视听觉时间同步(AVTS)的自监督机制可用于学习音频和视觉领域的模型,通过视觉和听觉上的相关性实现视觉和听觉上性能的提高,视觉和听觉上的关联,对于视觉下运动分析可以很好的结合听觉上的特征信息进一步提高判别和识别的准确。可以想象。视听觉结合对于提高分类和识别任务上还有进一步提升空间。

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







