The Sound of Pixels论文解读
视觉和听觉的同步性和相关性是两者在时空发生时就已经建立的天然联系,人类的认知往往是通过视觉和听觉协同建立的,我们看到溪水流淌,脑中不由自由的就会产生溪水潺潺的声音。视觉信息是可以辅助我们判断声音发生和所在位置,同时声音也能指导视觉关注。The Sound of Pixels便是利用视觉去指导混合音频的分离和定位。
论文引入
在交响乐现场,一段美妙的歌曲是由各种乐器组合演奏出的,不同音色和频率的乐器可以合奏出直击灵魂的乐曲。但是在数字音乐剪辑下,一旦不同音轨的音频被混合成为一段MP3格式的音频,再想分离出不同音轨确是一件十分棘手的问题。
在一些情况下很难录制到独奏的音频,这个时候实现混合音频的声音分离就显得格外的重要了,这种场景也适用于嘈杂环境下人类speech的分离,这方面的论文代表有Deep Audio-Visual Speech Enhancement,我在之前也做过简单的论文解读。这篇论文是利用人类的唇部视觉信息指导混合人声的分离,整体上的思路和The Sound of Pixels很像,都是利用视觉引导听觉信息的分离。
单纯的分析音频信号是复杂的,因为音频信号是高维不可描述的,而且原始音频信号时序性特别强,所以现在越来越多的研究者在分析声音的声谱图来研究音频信息。短时傅里叶变换以及它的逆变换可以很好实现音频的变换和重构,再者把声音换成由频率-时间的声谱图描述可以实现低成本运算下的分析。
在传统的声音分离的技术就是将音频的声谱图分解为两个低维矩阵,时间轴和频率轴的domain basis矩阵,利用Mask方式将原声谱图和掩码点乘得到分离出的音轨信号。The Sound of Pixels论文也是利用了这种掩码和声谱图相乘的方法实现音轨分离,不过这个掩码的计算方式是来自与视觉特征和音频特征的结合。
正是结合了视觉特征,使得论文在实现音频分离的同时实现了声音的定位,声音的位置正是对应听觉特征对应下视觉特征响应最强烈的像素位置。我们用下图去理解,声音发生的位置正是对应着图像上高亮的位置:

由于论文是利用视觉信号和听觉信号的同步性和相关性训练网络,这个关联信息是自身特有的,所以可以说这种训练方式是自监督学习方式。文章将他们实现的声音分离和定位的系统称为PixelPlayer。
总结一下The Sound of Pixels的优势:
- 利用视觉信号引导混合声音的分离
- 视觉信号辅助下可以实现声音的定位
- 视听觉关联性优化网络,实现自监督学习
PixelPlayer
所谓的PixelPlayer就是实现混合声音的分离和定位的系统,我们用图去理解:
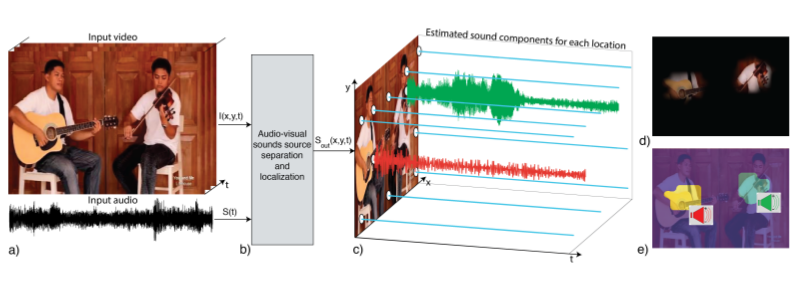
上图显示了PixelPlayer的演示,系统已经训练了大量的视频,其中包含人们演奏不同组合的乐器(包括独奏和二重奏)。测试时输入的是几个乐器合奏的视频,其中包括视频帧和对应的混合音频,在系统作用下,对图像的11个像素位置分离对应的音频信号,其中蓝色直线表示静音,非静音信号对应着该乐器下的音频信号,可以看到c)中的吉他和小提琴的音频都被分离了出来,d)显示了声音产生对应在图像上的像素位置,e)显示了像素如何根据其分量声音信号进行聚类,将相同的颜色分配给产生相似声音的像素。
可以看到,PixelPlayer实现了混合音频的声音分离,并且在视觉上给出了声音产生的定位。对于图像背景,是没有产生声音的。接下来,我们一起来看如何去实现PixelPlayer。
模型框架
我们来看一下PixelPlayer模型框架:
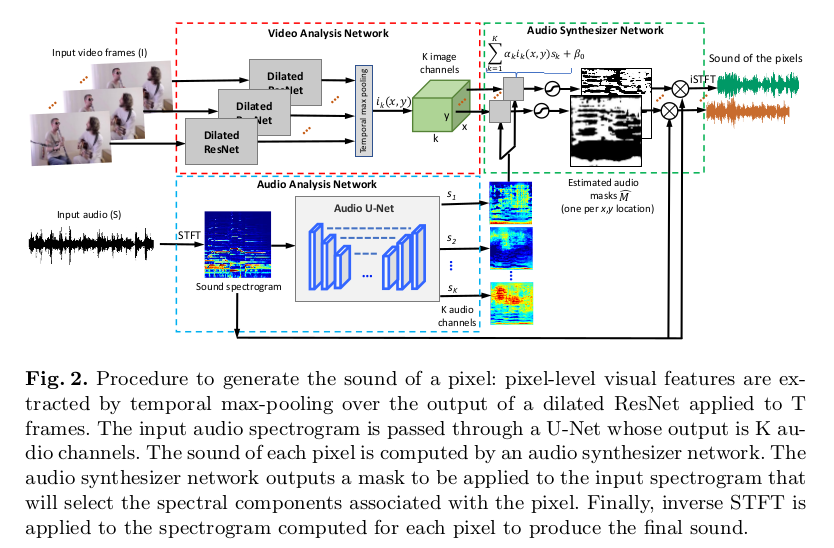
模型整体上可以分为3块,视觉分析网络、音频分析网络和音频合成网络。
视觉分析网络就是利用Dilated ResNet对视频帧进行特征提取,在时空最大池化层下得到视觉特征$i_k(x,y)$,其中有$k-channel$。
音频分析网络将声音的声谱图在Audio U-Net的作用下提取出k个大小和维度与声谱图一致的特征s_k输出,这一块我们后续展开分析。
音频合成网络就是利用视觉特征$i_k(x,y)$和音频特征$s_k$线性组合$\alpha_k i_k(x,y) s_k + \beta_0$得到声谱图的掩码$M(x,y)$,将原始的声谱图和不同特征$k$下的掩码相乘得到最终的分离音频的声谱图,通过结合相位信息和短时傅里叶逆变换得到分离出的音频信号。
Audio U-Net
为了获得Audio Masks,作者采用了U-Net网络结构来提取混合音频声谱图的不同语义分割map。为什么可以用语义分割图来进一步得到Audio Masks呢?语音的混合,在很多时候就是简单的近似相加得到的,这对应在声谱图上也是存在一定层次的叠加。将叠加的声谱图结构分割开来,再进一步与视觉特征组合得到的Audio Masks有理由相信是可以还原出分离音频的,文章的实验结果也证实了这一假设。我们先来了解一下Audio Masks是如何实现声谱图的分割的。
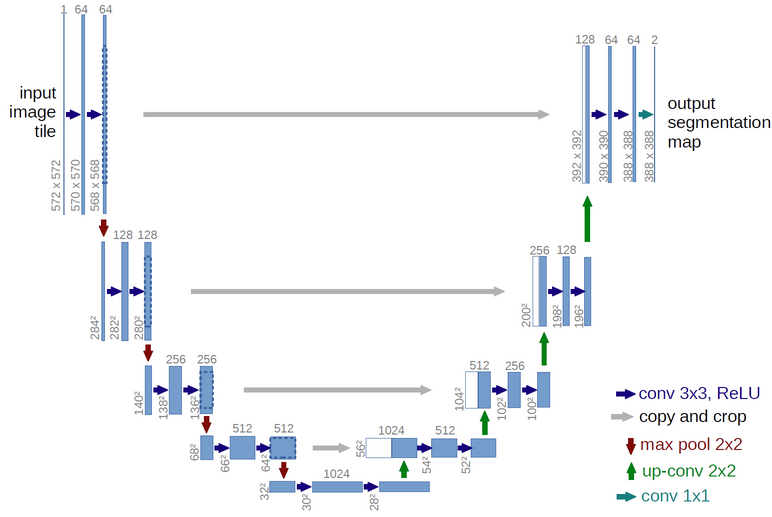
上图是U-Net结构,因为网络是一个U形,所以称为U-Net。最早U-Net提出是为了实现图像的语义分割,所谓的图像分割就是对图像中的物体做准确轮廓分割,可以这样理解,给出一张图像 $I$,这个问题就是求一个函数,从$I$映射到Mask。这要求网络实现输入和输出都是图像级别的,而U-Net网络正好可以实现输入输出需求的同时,满足对声谱图的分离。
可以看到U-Net整体是通过卷积下的下采样和上采样组成的,上采样到一个尺度后和之前下采样的feature map做拼接处理,再进行下一步上采样,直到尺寸满足输出要求。
我们看PixelPlayer模型的Audio U-Net的输入是混合音频的声谱图,输出是$k$张“分离”开的分割声谱图。虽然文章代码到现在还没有公布,但是可以猜测,由一张输入到$k$张输出这个过程的处理,可能是网络的最后的conv 1x1时候的输出处理。这里的细节,文章并没有说明,一切的解释还是等待作者公布源码再做进一步分析。
模型训练
模型训练主要是计算模型得到的Masks和真实的Masks的误差上进行优化,对于真实的Masks的计算,论文采用二进制或比率计算。对于二进制Masks的Ground Truth,通过观察目标声音(未混合的音频n)是否是每个T-F单元中的混合声音中的主要分量来计算:
\[\begin{equation} M_n(u,v) = [[S_n(u,v) \geq S_m(u,v)]],\forall m=(1,...,N) \end{equation}\]其中$(u,v)$表示$T-F$声谱图中的坐标,$S$表示声谱图,对于这种$0-1$的值,可以采取交叉熵做损失的优化。对于比率计算Masks,可以利用目标声音和混合声音的大小的比率:
\[\begin{equation} M_n(u,v) = \frac{S_n(u,v)}{S_{mix}(u,v)} \end{equation}\]此时,损失函数可以选择$L_1$损失优化。
实验
论文主要实验是在不同混合乐器的声音分离,文章尝试11中乐器的分离,当然每次是对两个乐器分离出(4个以下),文章的$k$定为16,那为啥不是11呢?这个$k$只是表示分离的声谱图数量,很可能一种乐器的高音和低音对应着两个不同$k$下的特征。
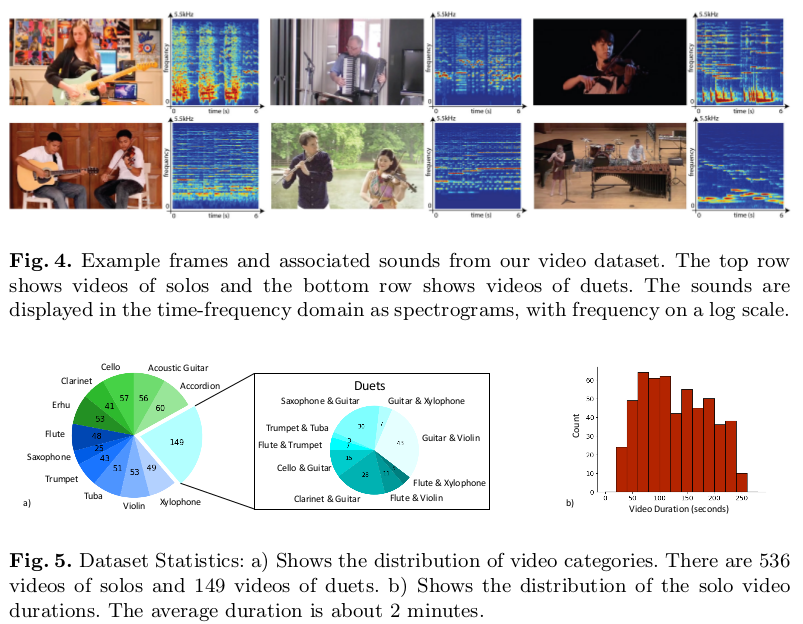
为了扩展实验数据集,文章借助Youtube创建了MUSIC数据集,其中包含685个未经修改的音乐独奏和二重奏视频,数据集涵盖11种乐器,数据集介绍可参看下图:
对于Masks和声谱图的预测结果,文章给出了定性展示:

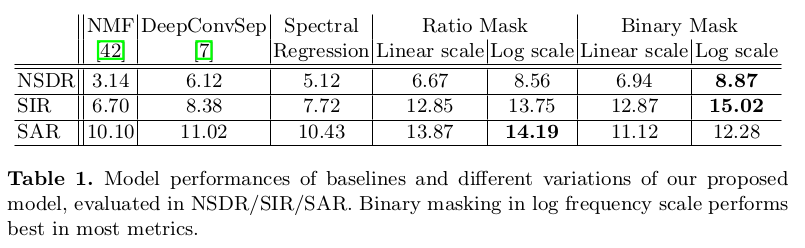
可以看出模型较好的学习到了分离的声谱图和Masks。定量上实验也展示了一定的优势:
为了展示声音的定位效果,文章利用分离声音对应的Mask下在视觉图像上神经网络激活的像素区域做展示,在声音发生的位置上,模型确实实现了声音的定位:

总结
论文设计了PixelPlayer,这是一个从未标记的视频中学习分离输入声音并在视觉输入中定位它们的系统。在一个系统下同时实现声音的分离和定位是一件很有意义的研究,文章的Masks方法还原分离音频很有启发性。文章在实现的细节和网络的具体架构上没有具体展开,希望作者可以早日公开源码。

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







