TGANs-C论文解读
视频生成在计算机视觉上已经是很困难的工作了,按照描述去生成视频是更具有挑战性的工作。To Create What You Tell: Generating Videos from Captions 简称为TGANs-C,在实验上实现了由描述的标题生成相对应的视频,这个工作很有意义,整体思想上采取GAN为主题框架实现,我们一起来读一下。
论文引入
视频生成的困难在于视频是视觉上连贯和语义相关的帧的序列,也就是在时序序列上做生成,一涉及到时序就存在大量的不确定性,这也是语音和视频生成上 的难点所在。视频通常伴随有文本描述,例如标签或字幕,因此学习视频生成模型对文本进行调节从而减少了采样不确定性,这个是具有很大的潜在实际应用。 GAN在实现时序上的生成我们之前博客有写到Temporal GAN论文解读、 VGAN论文解读,整体的思想都是采用3D卷积处理视频序列从而实现视频的生成。
TGANs-C和TGAN的区别在与TGANs-C实现了由描述性文字到 视频的生成,这篇论文的基础上借鉴了文本到图片生成的GAN-CLS都是采用配对的思想,这个我们后续再谈, 如果你对GAN-CLS印象很深的话这篇文章读起来会很轻松。
通常,在采用标题调节的视频生成中存在两个关键问题:跨视频帧的时间一致性以及标题描述与生成的视频之间的语义匹配。前者产生了对生成模型学习的见解, 相邻视频帧通常在视觉上和语义上是连贯的,因此应该随着时间的推移而平滑地连接,这可以被视为产生视频的内在和通用属性。后者追求的模型能够创建 与给定标题描述相关的真实视频。因此,一方面考虑条件处理以创建类似于训练数据的视频,另一方面考虑通过整体利用字幕语义和视频内容之间的关系来规范生成能力, 这正是TGANs-C所考虑的。
总结一下TGANs-C的优势:
- 这是第一个在标题描述下生成视频的工作之一
- 实现了视频/帧内容与给定标题对齐
- 通过一系列广泛的定量和定性实验,验证了TGANs-C模型的有效性
TGANs-C模型结构
我们还是先来看一下模型的网络结构:
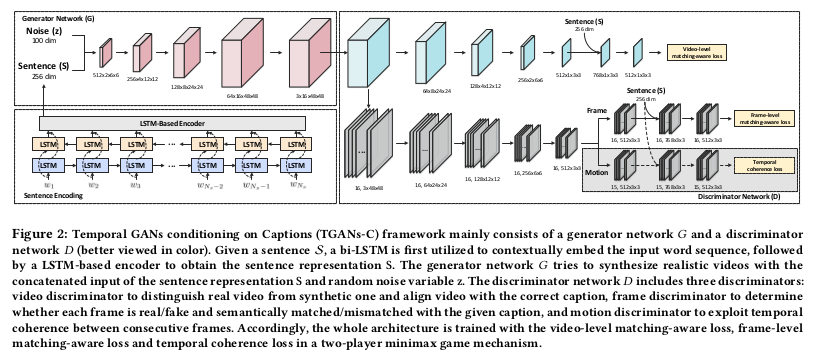
整体上模型分为左右两块,左边是生成器,右边就是判别器,所以说TGANs-C是以GAN为主体框架的模型,我们分开来分析。
生成网络
生成网络下由两块组成,下面是标题描述的文本编码,上面就是在噪声和文本编码特征作为输入的生成器。对于文本编码,文章采用的是双向LSTM做的编码。 文字描述的时序和语义结构是紧密相关的,所以需要保留时序信息,所以RNN的思想是处理的关键。对于文本编码过程中采用逐个单词双向处理, 双向LSTM可以保证文本上更加紧密的时序和语义结构,最终编码到特征维度为$d_s$文中取的是256维。
将文本编码得到的特征向量$S$和先验噪声$z$做concat${ \mathbb R^{d_s}, \mathbb R^{d_z} }$送入3D反卷积网络做视频的生成,整个过成处理上为 ${ \mathbb R^{d_s}, \mathbb R^{d_z} } \to \mathbb R^{d_c \times d_l \times d_h \times d_d}$,这里的$d_c,d_l,d_h,d_d$ 代表的是通道数、帧、高、宽,这里的高和宽对应的是视频一帧图像的长宽,帧代表反卷积下包括多少视频帧,比如最后的输出文中取的是16帧作为视频的输出。
可以看到,经过3D反卷积后,由噪声和文本编码最后生成了彩色的16帧大小为$48 \times 48$的视频输出。整个生成器我们可以将标题描述特征作为条件, 整个生成器是类似于条件生成器,由标题描述特征作为条件生成对应的视频。
判别网络
TGANs-C有着强大的判别网络,文章为了实现判别效果设计了3个判别器,图中对应的是右半边上、中、下。
上面一路的判别器命名为$D_0$,它的目的是为了区别生成的视频和真实的视频的真假,为了保证与标题描述对应,在最后嵌入了标题特征做匹配。这个思想在GAN-CLS 最早被应用,为了实现和描述文本的匹配,在判别器的设计上增强了判别器的能力。判别器不仅判断视频的真假还判断视频是否和标题描述对应, 配对就这样产生了,由3组配对关系:真实视频和正确标题描述$(v_{real}^+,S)$、生成视频和真实标题描述$(v_{syn}^+,S)$还有就是真实视频和错误标题描述 $(v_{real}^-,S)$。判别器$D_0$只有在真实视频和正确标题对应上才判断为真,否则为假,即$(v_{real}^+,S)$为真,$(v_{syn}^+,S)$、$(v_{real}^-,S)$ 为假。与之对应的损失函数为:
\[\mathcal L_v = - \frac{1}{3}[log(D_0(v_{real^+},S)) + log(1 - D_0(v_{real^-},S)) + log(1 - D_0(v_{syn^+},S))]\]中间一路的判别器命名为$D_1$,它的目的是为了区分对应的视频帧的真假,同样的加入了与标题描述的匹配,用$f_i$描述视频的第$i$帧对应的图像, 对于整个视频一共有$d_l$帧,这个判别器对应的损失为:
\[\mathcal L_f = - \frac{1}{3d_l}[\sum_{i=1}^{d_l}log(D_1(f_{real^+}^i,S)) + \sum_{i=1}^{d_l}log(1 - D_1(f_{real^-}^i,S)) + \sum_{i=1}^{d_l}log(1- D_1(f_{syn^+}^i,S))]\]下面一路的判别器命名为$D_2$,它的目的是为了在时序上调整前后帧的关系,一般视频中前后帧之间不会有太大的变动,由此思想文章设计了时序关联损失。 它的作用是保证视频的前后帧之间不会有太大的差异,用$\mathcal D$表示:
\[\mathcal D(f^i,f^{i-1}) = \Vert m_{f^i} - m_{f^{i-1}} \Vert_2^2 = \Vert \vec{m_{f^i}} \Vert_2^2\]由于决定生成的视频帧的帧之间的关系的是生成器,对于真实视频没必要再做差异优化,所以这部分主要作用的是生成器,这一块的损失可以写为:
\[\mathcal L_t^{(1)} = \frac{1}{d_l-1} \sum_{i=2}^{d_l} \mathcal D(f_{syn^+}^i,f_{syn^+}^{i-1})\]为什么这里的上标为1呢,因为对应的还有2,这一部分是考虑到生成视频帧之间的关联差异,从动态差异上实现对抗又会怎么样呢?这就是另一种实现时序关联的方法。 这一部分用$\Phi_2$判断真假,此损失表示为:
\[\mathcal L_t^{(2)} = - \frac{1}{3(d_l-1)}[\sum_{i=2}^{d_l}log(\Phi_2(\vec m_{f_{real^+}^i},S)) + \sum_{i=2}^{d_l}log(1 - \Phi_2(\vec m_{f_{real^-}^i},S)) + \sum_{i=2}^{d_l}log(1- \Phi_2(\vec m_{f_{syn^+}^i},S))]\]文中对时序关联上采取的方法(1)时间相干约束损失命名为TGANs-C-C,对于方法(2)时间相干性对抗性损失命名为TGANs-C-A。从后续的实验上验证出 TGANs-C-A的方法效果更好,所以文章的名字TGANs-C其实指的是TGANs-C-A。
整合一下,对于方法(1)TGANs-C-C对应的判别器和生成器最终损失为:
\[\hat{\mathcal L}_D^{(1)} = \sum_{\mathcal T} \frac{1}{2}(\mathcal L_v + \mathcal L_f)\] \[\hat{\mathcal L}_G^{(1)} = - \sum_{v_{syn} + \epsilon \mathcal T} \frac{1}{3} [log(D_0(v_{syn^+},S)) + \frac{1}{d_l} \sum_{i=1}^{d_l}log(D_1(f_{syn^+}^i,S)) - \frac{1}{d_l-1} \sum_{i=2}^{d_l} \mathcal D(f_{syn^+}^i,f_{syn^+}^{i-1})]\]对于方法(2)TGANs-C-A对应的判别器和生成器最终损失为:
\[\hat{\mathcal L}_D^{(2)} = \sum_{\mathcal T} \frac{1}{3}(\mathcal L_v + \mathcal L_f + \mathcal L_t^{(2)})\] \[\hat{\mathcal L}_G^{(2)} = - \sum_{v_{syn} + \epsilon \mathcal T} \frac{1}{3} [log(D_0(v_{syn^+},S)) + \frac{1}{d_l} \sum_{i=1}^{d_l}log(D_1(f_{syn^+}^i,S)) - \frac{1}{d_l-1} \sum_{i=2}^{d_l}log(\Phi_2(\vec m_{f_{syn^+}^i},S))]\]最后贴上实现整个TGANs-C的伪代码:

TGANs-C实验
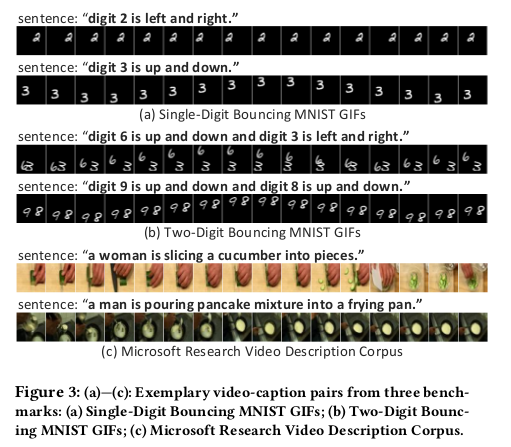
实验的数据集选择了单数字边界MNIST GIF(SBMG),两位数的弹跳MNIST GIF(TBMG)和微软研究视频描述语料库(MSVD)。SBMG是通过在64×64帧内弹出单个手写数字而产生的。 它由12,000个GIF组成,每个GIF长16帧,包含一个28×28左右移动的数字左右或上下。数字的起始位置是随机均匀选择的。每个GIF都附有描述数字及其移动方向的单句。 TBMG是SBMG的扩展合成数据集,包含两个手写数字弹跳,生成过程与SBMG相同,每个GIF中的两个数字分别左右或上下移动。MSVD包含从YouTube收集的1,970个视频片段。 每个视频大约有40个可用的英文描述。在实验中,手动过滤掉有关烹饪的视频,并生成518个烹饪视频的子集。数据集的部分描述如下图:
$TGANs-C_1$为仅考虑视频对抗$D_0$,$TGANs-C_2$为考虑了$D_0,D_1$未考虑$D_3$,TGANs-C-C和TGANs-C-A都已经知道了构成,这几个对比结果为:

定性分析不同模型产生的结果如下图,主要对比了VGAN、Sync-DRAW(基于VAE实现的)、GAN-CLS和TGANs-C。

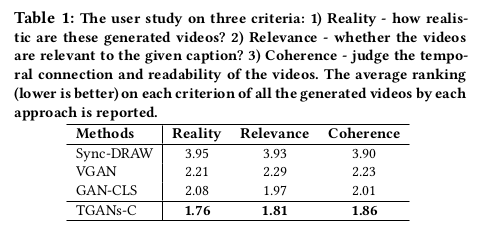
定量上以不同人的选择,给分越低效果越好,TGANs-C也展示了很好的效果:
总结
TGANs-C实现了标题描述到视频的生成,正如文章的题目说的那样To Create What You Tell!虽然这个题目有点大,但是确实在理论上是可以行得通的。 匹配的思想对于严格的固定生成来说是很重要的一个技术环节,可以借鉴在很多地方,正是这种严格的配对关系往往限制了一些发展,因为这种算是全监督式学习了。 无监督下条件生成是最为困难的,这个也是未来大家一起努力的地方!
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







