Generating Videos with Scene Dynamics论文解读
GAN在图片生成上展示了惊人的效果,但是动态的视频生成一直是计算机视觉上的难点。利用GAN可不可以实现动态的视频生成呢?Generating Videos with Scene Dynamics 给出了肯定的答案,虽然文章在16年底就已经发表了,但是这种具有开创意义的研究成果还是很值得研读的。
论文引入
了解物体运动和场景动力学是计算机视觉中的核心问题,可应用在视频识别任务(例如,动作分类)和视频生成任务(例如,未来预测),然而创建动态模型具有挑战性, 因为对象和场景可以通过多种方式进行更改。学习场景如何随时间变换的问题,需要大量标注的数据作为训练,这势必会增加成本和周期。相反,网上存在着大量的短视频, 这些视频虽然没有详细的标注但是可以直接拿来训练。总的来说未标记的视频具有以下优点:可以大规模经济地获得;包含时间信息因为帧在时间上是连贯的。
单帧的静态背景和场景图片生成可以用GAN较好的实现,但是动态的视频就是一个困难的过程因为中间涉及到动力学的学习过程。视频的识别和分类在现在也还是个很艰难的问题。 Generating Videos with Scene Dynamics引入了一个双流生成模型,它明确地将前景与背景分开建模,从而实现了微视频的生成。下文我们简称这种方法为 VGAN。
总结一下VGAN的贡献所在:
- 展示如何利用大量未标记的视频来获得有关场景动态的先验。
- 利用GAN实现了视频的生成。
VGAN模型介绍
我们还是先通过模型框图理解一下Video-GAN,下图为模型框图:
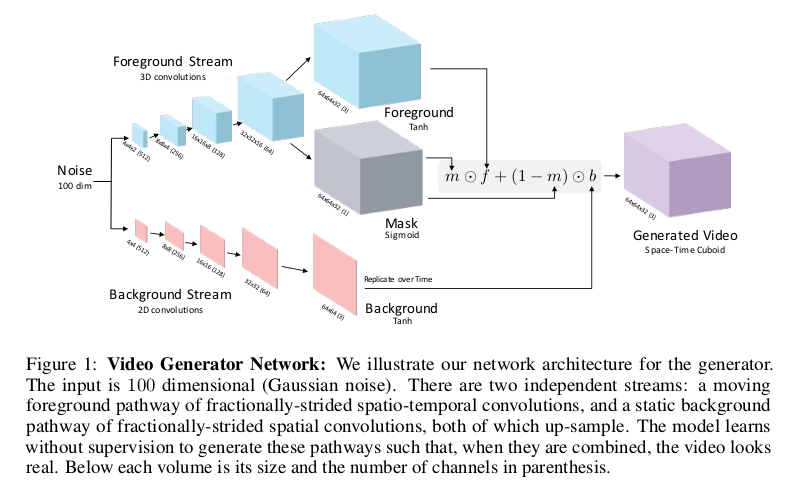
VGAN的一个创新之处就是利用双流去生成视频,我们看到整个生成器由两部分组成,上面一流是前景流生成,下面一流是背景流生成。由于VGAN 仅仅是考虑在固定背景下前景动作的变化,所以背景采用静态图片生成的过程。我们分开来分析上下两个生成流。
背景流
我们先说背景流,这就是图片生成的过程,输入噪声通过普通的反卷积操作就会形成一张图片,这张图片就定为视频的背景图,当然后面还要经过一定的组合变换, 我们后面再细说。背景流的生成不考虑时间,所以不涉及任何时序问题。
前景流
前景流的生成就稍微复杂一点,整个反卷积的过程采用3D时空卷积。3D时空卷积最早在3D Convolutional Neural Networks for Human Action Recognition 一文中提到,整个流程和卷积神经网络很像但是加入了时间维度的卷积进去。在这里不详细展开说明3D时空卷积,如果想深入了解可以查看这篇博客。 我们分析一下,输入噪声\(z\)在3D时空反卷积下不断的扩大空间的尺寸同时在时间维度上也慢慢的扩大(图中4x4x3(512)代表长宽为4x4,时间帧数为3,有512个channel)。 在到达32x32x16(64)的时候分为两路,一路生成前景动态视频,另一路生成Mask(掩模),最后的前景动态视频是32帧输出。
解释一下Mask的作用,它是联系前景和背景之间的纽带,用于对前景背景之间位置和时间点选择合适的组合。这里的前面32x32x16(64)前景视频和Mask是共享参数的。 最后生成器最后的输出就是:
\[G_2(z) = m(z) \cdot f(z) + (1 - m(z)) \cdot b(z)\]通过掩模\(m(z)\)将前景和背景联系起来,最终形成一段微视频作为假样本。对于判别器,整体的结构类似于生成器中前景流的最上面的过程的逆过程。 对于判别器,输入一段微视频,经过3D时空卷积不断地缩小尺寸和时间维度最终输出判别输入为真假的二分类结果,此时最后一层取sigmoid。
至于框架的整体损失函数,和GAN的原始损失函数相似。
VGAN实验
文章的视频来源于Flickr网站,大约200万视频,文中将这些数据大体上分为两大类:
1.未过滤的未标记视频,直接使用这些视频,无需任何过滤,用于表示学习。 2.过滤的未标记视频,使用Places2预训练模型按场景类别自动过滤视频。由于图像/视频生成是一个具有挑战性的问题,标注数据集以更好地诊断方法的优缺点。 文中尝试了四种场景类别:高尔夫球场,医院室(婴儿),海滩和火车站。
实验整体关注的是对物体移动的微视频的生成,所以对于相机的抖动造成的视频质量问题,文中采取了一定的预处理。
在四种场景下生成的微视频截图:

我们观察到a)生成的场景趋于相当清晰,并且b)运动模式通常对于它们各自的场景是正确的。例如,海滩模型往往会产生波涛汹涌的海滩,高尔夫模型会让人们在草地上行走, 而火车站的世代通常会显示火车轨道和火车沿着快速移动的轨道。虽然模型通常学会将动作放在正确的物体上,但一种常见的失效模式是物体缺乏分辨率。 例如,海滩和高尔夫球场的人通常都是斑点。
由于没有衡量生成视频的标准,文章中设计了Autoencoder作为对比的基准,Autoencoder的整体框架和VGAN类似只是没有对抗和判别器。为了说明生成视频的质量, VGAN采取人工评估的方法,通过不同工人给出的对比结果反应模型是否生成了合理的微视频。下表给出了在单流(只保留前景流)和双流以及Autoencoder下工人的对比结果。
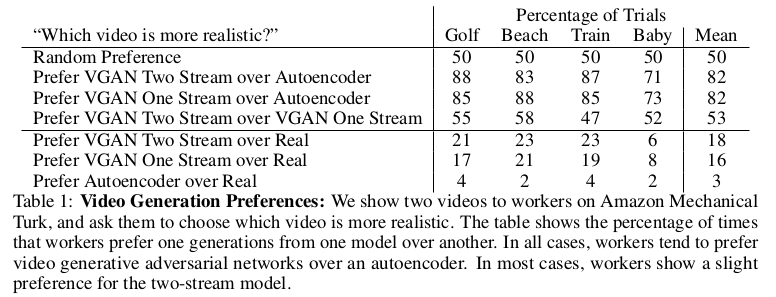
与自动编码器相比,工作人员更喜欢生成对抗网络中的视频。另外,工作人员对双流结构略有偏好,特别是在背景较大的场景(例如,高尔夫球场,海滩)中。 最后,虽然工作人员通常可以将真实视频与生成的视频区分开来,但与基线相比,工作人员对我们的双流模型表现出最大的困惑,这表明双流生成平均可能更加真实。
VGAN还应用在了学习视频的无监督表示上,用于对视频做分类的处理以及性能和数据之间的关系比较上,下图展示了实验结果:
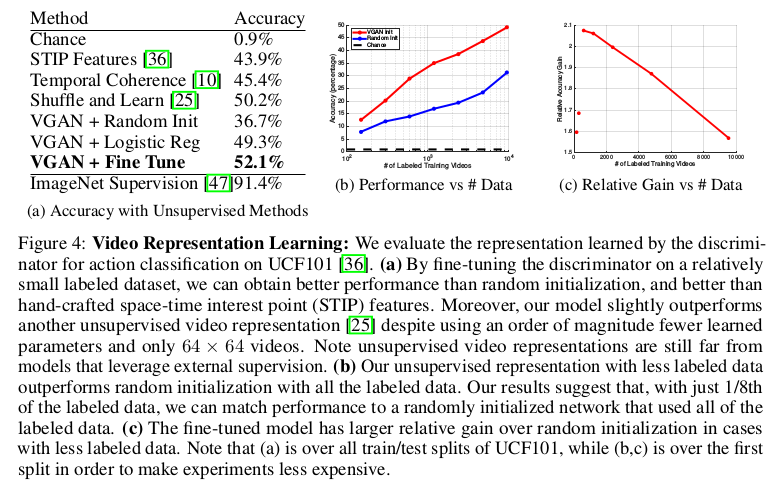
可以看出使用从生成对抗网络获得的权重来初始化网络优于随机初始化的网络,这表明VGAN已经学习了有用的视频内部表示;性能会随着标记数据的增加而展现出上升。 至于VGAN用在输入单张静态图片用于视频预测生成输出上,VGAN虽然可以展示出物体移动的特性但是准确性和合理性有待提高,这也是VGAN一文中提出的自己未来的工作。
总结
VGAN利用3D时空卷积和双流的思想生成了微视频,将GAN应用在视频的生成上对用视频的生成是一个创新,同时分流的思想也值得借鉴。 但是VGAN主要是应用在背景不变的场景视频的生成中,对于场景变化的视频可能又会是一个很大的挑战!
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







