TequilaGAN论文解读
GAN和GAN的变种已经将图像生成质量达到了以假乱真的效果,虽然生成的一部分图像可以用肉眼去分辨,但是仍然有一部分由GAN生成的图像在视觉上很难和真实图像区分开。 区分真假图像对于分析GAN的生成上具有一定的意义,同时也说明了GAN在生成上与真实图像的不同所在。TequilaGAN: How to easily identify GAN samples 一文将从视觉以外的方面去区分生成样本和真实赝本之间的差距。
论文引入
使用GAN框架生成的假样本在一定程度上骗过了人类和机器,使他们相信生成样本与实际样本无法区分。虽然这可能适用于肉眼和被发生器愚弄的判别器, 但生成样本不可能在数值上与实际样本无法区分。TequilaGAN一文正是通过真实样本和生成样本在数值上的分析可以判断出真假。GAN的生成数据的评判标准 一直没有很好的统一,大部分的评估是在定性的方面作分析,定量上Inception Score一直被广泛使用, 但是A note on the inception score一文也指出了Inception Score未能为GAN模型的评估提供系统指导。
在已验证的人工智能的背景下,很难系统地验证模型的输出是否满足其训练的数据的规范,特别是当验证取决于感知有意义的特征的存在时。例如, 考虑一个生成人类图像的模型,尽管可以比较真实样本和假样本的颜色直方图,但还没有强大的算法来验证图像是否遵循从解剖结构得出的规范。
TequilaGAN涉及假样本的系统验证,重点是比较假样本和真实样本的数值特性。除了比较统计汇总之外,还研究了Generator如何逼近实际分布中的统计模式, 并验证生成的样本是否违反了从实际分布中得出的规范。总结一下TequilaGAN的主要贡献:
- 证明了假样本在视觉上和真实样本具有几乎不会被注意到的属性
- 这些属性可用于识别数据来源(真实或生成)
- 证明了假样本违反了从真实数据中学习的正式规范
研究方法
实验主要集中在三点:第一点表明,假样本具有视觉检查难以察觉的特性,此特性与可微分的要求密切相关; 第二个表明,从可用于识别数据的真实和假样本中 提取的特征计算的统计矩之间存在数值差异; 第三个表明假样本违反了从真实数据中学到的正式规范。
数据集
实验使用MNIST,CIFAR10以及从网上下载的389个Bach Chorales的MIDI数据集和NIST 2004电话会话语音数据集的子样本。
特征
特征光谱质心是音频领域常用的特征,它代表光谱的重心。MNIST和Mel-Spectrograms的特征光谱质心如下图所示示例。 对于图像中的每一列,通过对列总和进行归一化,将像素值转换为行概率,然后获取预期的行值,从而获得光谱质心。
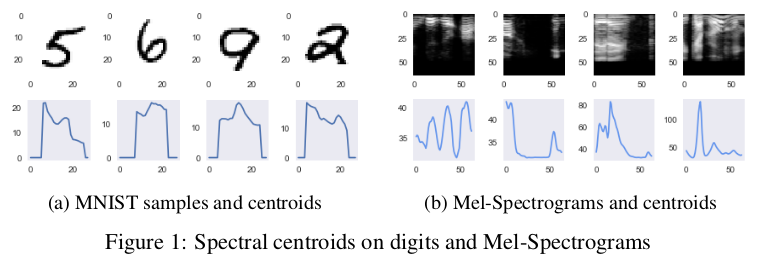
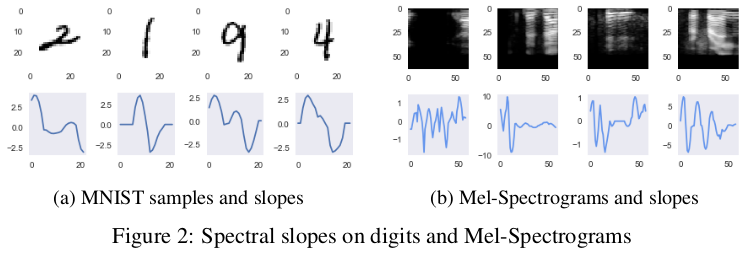
试验中同时表示了谱斜率图:
GAN框架选取
GAN框架使用最小二乘GAN(LSGAN)和改进的Wasserstein GAN(IWGAN / WGAN-GP)网络搭建使用DCGAN架构。还比较了使用快速梯度符号法(FGSM)生成的对抗性MNIST样本。 在生成器的输出和其他变换(例如缩放的tanh和身份)上评估常用的非线性,sigmoid和tanh。
MNIST实验
这部分着重于显示由GAN伪造的MNIST样品的数值特性以及肉眼未知的特征。首先将通过MNIST训练集计算的特征分布与其他数据集进行比较,包括MNIST测试集, 使用GAN生成的样本和使用FGSM计算的对抗样本。将训练数据缩放到[0,1],并且从伯努利分布采样随机基线,概率等于MNIST训练数据中像素强度的平均值0.13。
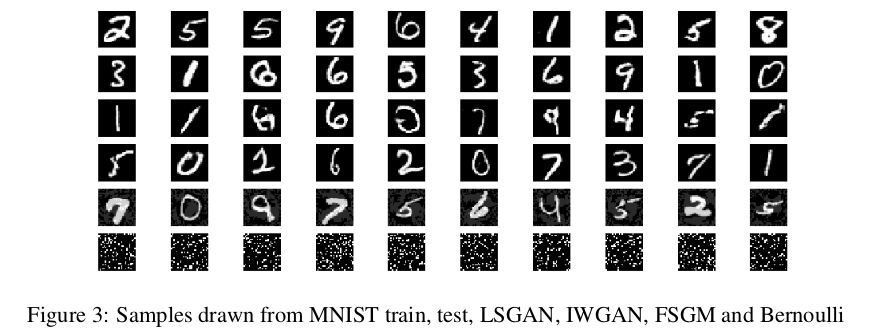
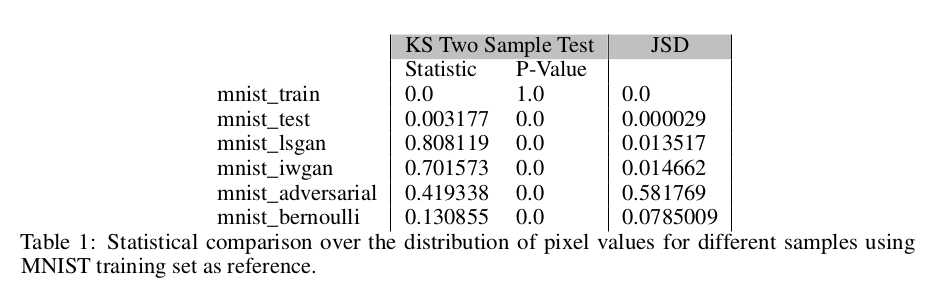
从上图生成的样本表明,IWGAN似乎比LSGAN产生更好的样本。在Kolgomorov-Smirnov(KS)双样本检验和Jensen-Shannon Divergence(JSD)上, LSGAN和IWGAN生成的样本如表一所示与标准数据集还是有一定的不同。
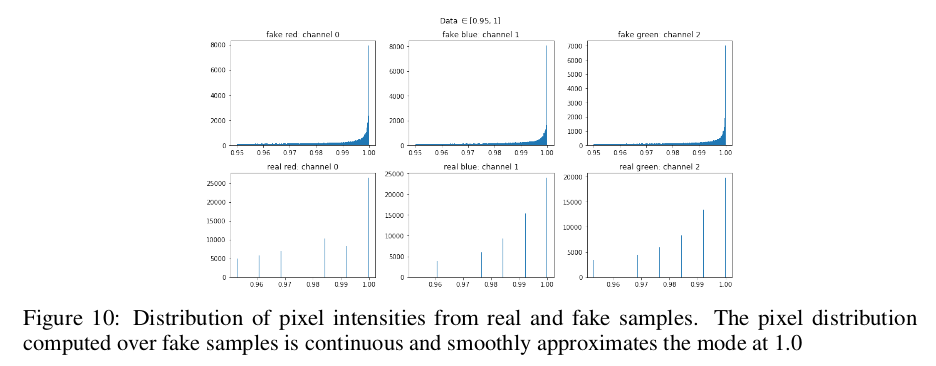
下图中的经验CDF可以理解这些数值现象,使用GAN框架生成的样本的像素值分布主要是双模态的,并且渐近地接近实数据中的分布模式值0和1。
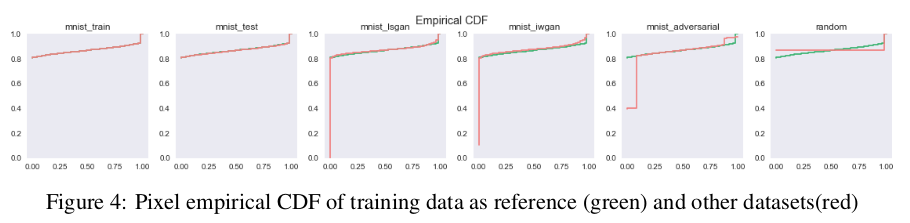
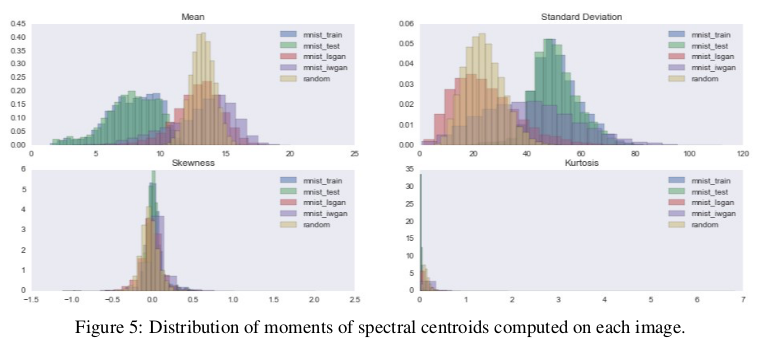
此外,光谱质心的统计矩的分布图表明假图像比真实图像更嘈杂。
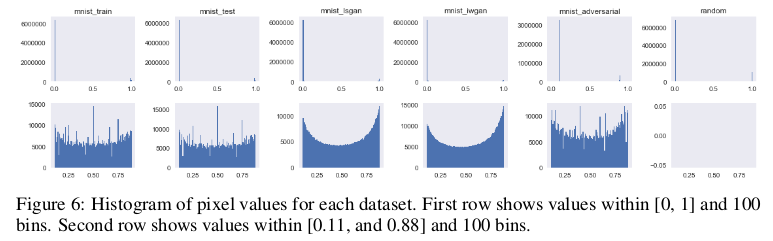
最后,下图显示GAN生成的样本平滑地接近分布模式,这种平滑近似与训练和测试集有很大不同。虽然在感知上没有意义,但这些属性可用于识别数据源。
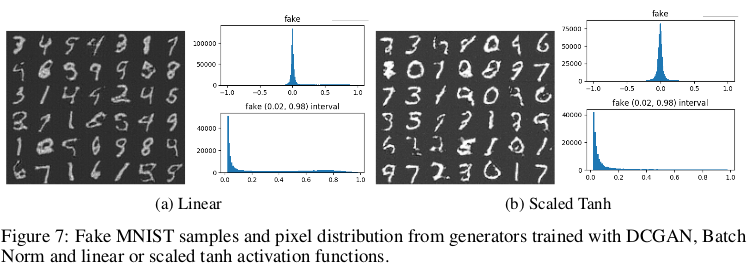
对分布模式的平滑逼近的解释上第一个假设是网络搭建采用随机梯度下降和渐近收敛激活函数(例如sigmoid或tanh),为了验证这一假设,保持判别器固定, 在发生器的输出端采用不同的激活函数,包括线性和缩放的tanh。如下图所示,使用线性或缩放tanh激活训练的模型能够部分地生成类似于MNIST训练数据和像素强度分布的图像, 仍然具有平滑的曲线。
另一个假设是平滑行为是由于训练数据本身的像素强度的平滑性,为了验证这一点,首先通过在[0,1]之间对其进行缩放,然后将其设置为0.5来对实际数据进行二值化。 通过这种改变,实数据的像素强度的分布变为完全双模态,模式为0和1,从下图结果显示假设是合理的。
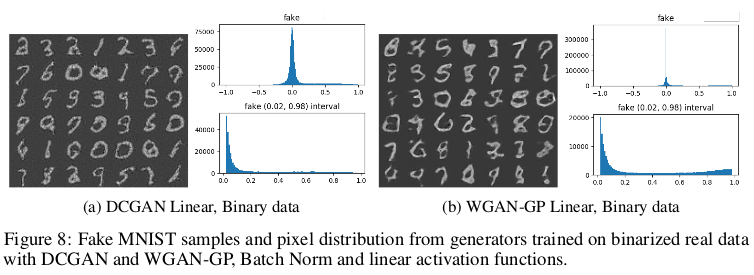
根据上述实验可知,随机梯度下降和方向传播的应用使得生成的图像分布上是平滑的,这是区分真假样本的一个重要依据。
CIFAR-10实验
CIFAR-10的实验主要是在MNIST数据集的基础上将像素扩展到3通道的彩色图像上,实验结果如下:
可以看出生成样本仍然是平滑分布。
Bach Chorales和Speech实验
这两种数据集都是在语音数据下比较的,Bach Chorales(巴赫合唱)音乐是复调的音乐作品,通常为4或5种声音编写,遵循一系列规范或规则。例如, 全局规范可以声明只有一组持续时间有效;本地规范可以声明只有状态(音符)之间的某些转换才有效,具体取决于当前的和声。实验中,将Bach Chorales 数据集转换为钢琴卷,钢琴卷是一种表示,其中行表示音符编号,列表示时间步长,单元格值表示音符强度。实验的目的是为了证明生成的样本是否违反了Bach合唱的规范。 下图为真实和生成的样本数据,表2为打破规则的次数:


虽然图11显示的生成样本看起来与实际数据类似,但IWGAN样本有超过5000次违规,比测试集多10倍!违反规范是一个有力的证据,表明假样本不是来自与真实数据相同的分布。
在语音(speech)域中,实验研究了Mel-Spectrogram特性。将NIST 2004数据集划分为训练和测试集,将语音转换为Mel-Spectrogram图,得到的生成样本如下:

经验CDF的对比结果如下:
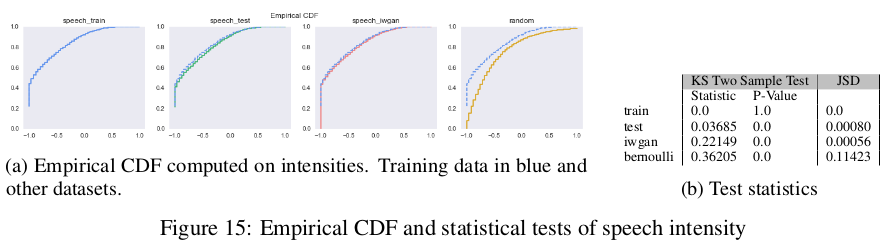
总结
TequilaGAN研究了用对抗方法生成的样本的数值特性,特别是生成对抗网络。实验发现假样本在视觉具有与真实样本几乎无法注意到的特性, 即由于随机梯度下降和可微分性的要求,假样本平滑地接近分布的主导模式。实验还对真实数据与其他数据之间差异的统计度量,结果表明,即使在简单的情况下, 例如像素强度的分布,训练数据和伪数据之间的差异对于测试数据而言是大的,并且假数据严重违反了实际数据的规范。
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







