GAIA论文解读
Auencoder是神经网络应用在图像,文本,音频上编码解码的开创性研究,但是Autoencoder在图像编码解码中由于损失函数使用的是像素上的误差, 这就造成了解码重构的图像是迷糊的。AE基础上的改进有VAE,但是VAE依然没有改善生成图像模糊的弊病。GAN引入对抗损失,生成的图像更加清晰。 将GAN的对抗思想应用到Autoencoder中会有什么效果呢?GAIA正是利用这个思想,我们一起来看看。
论文引入
Autoencoder在2006由Hinton等人在science提出的,可谓是神经网络应用在图像编码解码的开创之作, AE由编码器Encoder和解码器Decoder组成,编码器将图像或其它高维复杂的数据编码到低维潜在空降,并且通过解码器重构数据。所以说AE是一个双向的过程。 但是AE只是做数据的编码解码,输入数据重构,VAE在AE的基础上将编码得到的潜在空间强制其服从高斯分布,从而实现了数据的生成。同时,VAE的操作 使得潜在空间属于凸集,这就使得潜在向量之间插值做生成是合理的。然而VAE和AE的共病就是生成的图像是模糊的,造成这个原因是由于重构过程中使用的损失函数是在 图像像素上的误差。
GAN的诞生在生成模型上带来了巨大的贡献,GAN由于使用了对抗的思想, 在图像的生成上是sharp的,GAN是直接由先验分布(高斯分布,均匀分布等)采样生成数据,这个过程是直接由\(Z \to X\)是单向过程,由于直接在先验分布上采样 也满足凸集的假设,但是GAN是不可以直接做插值生成的,当然一系列GAN的衍生也慢慢丰富了这条道路。
VAE和GAN在一定成上是优于AE的,但是AE在编码器上由于是直接从原始数据编码得到,所以直接由AE编码得到的潜在向量保留了数据的高维结构特性。 VAE-GAN将VAE和GAN结合了,将图像编码得到的潜在空间作为输入到GAN中做生成,虽然GAN得到了改进,但是训练的稳定性和生成的合理性仍然存在问题。 将AE和GAN结合是GAIA的创新点,直接由图像Encoder得到的潜在向量保留了数据的高维结构特性,但是由于得到的潜在空间是未知的,所以这个潜在空间不一定分从 凸集的特性,GAIA通过将AE应用在生成器和判别器上,同时在损失函数设计上考虑了潜在空间的插值凸集,通过训练使得潜在空间满足凸集性质从而使得插值生成的图像更加合理。
总结一下GAIA的贡献:
- 提出了一种基于自动编码器(AE)和生成对抗网络(GAN)的神经网络架构
- 通过对潜在空间插值进行对侧训练来促进凸潜在分布
- 使用AE作为GAN的生成器和鉴别器,产生与原始图像的高级和低级特征匹配的非模糊样本
- 可实现插值下图像合理生成
GAIA模型
我们先来看一下GAIA的模型框架:
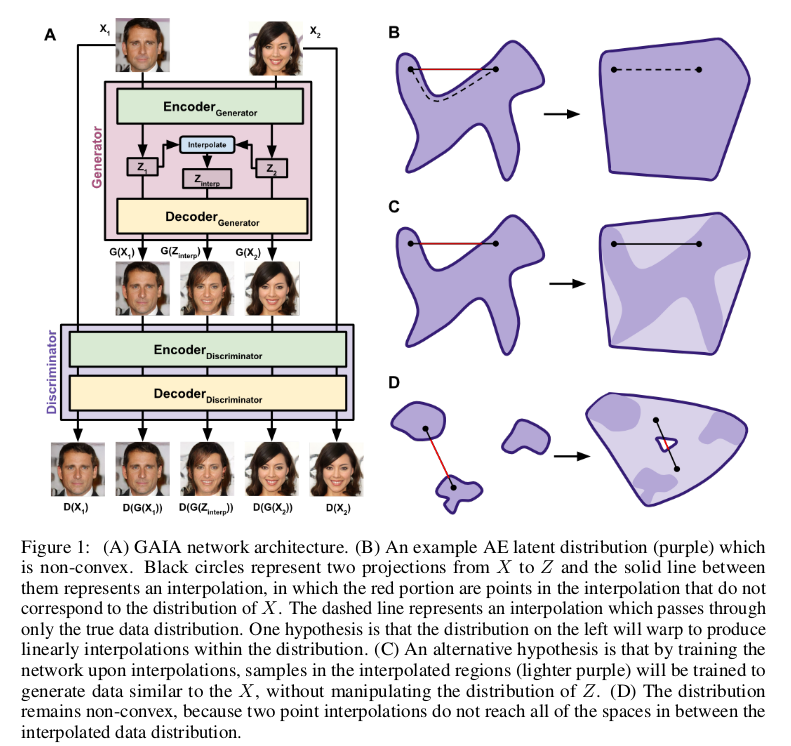
我们一起看一下上图中的A,A中图像经过生成器Generator重构出一张图片,这个生成器的结构是AE框架内部包含了一个编码器Encoder和一个解码器Decoder, 在图像Encoder后得到了潜在空间,并且对两个潜在空间进行插值后再送入Decoder得到由插值得到的图像。也就是输入两幅图像\(X_1,X_2\)经过Encoder 得到潜在向量\(Z_1,Z_2\)在\(Z_1,Z_2\)之间插值得到\(Z_{interp}\)。再将\(Z_1,Z_2,Z_{interp}\)送入Decoder得到重构图像\(G(X_1),G(Z_{interp}),G(Z_2)\) 生成器的目的是为了让生成的图像尽可能与真实图像一样,这样单纯利用像素误差来优化是不够的,这时候就是GAIA的创新之处了。
再额外的添加一个判别器Discriminator,它的目的是为了识别出生成器生成的假图像(通过最大化生成图像像素误差),这个过程我们也一起屡一下。 将真实图像\(X_1,X_2\)和由Generator得到的生成图像\(G(X_1),G(Z_{interp}),G(Z_2)\)一起送到判别器Discriminator中,经过AE的结构又重构出图像 \(D(X_1),D(G(X_1)),D(G(Z_{interp})),D(G(X_2)),D(X_2)\)。判别器的目的是最小化真实图像的像素误差,最大化生成图像的像素误差。这个过程就与 生成器形成了对抗,达到了交替优化共同进步的目的。
上图中的B,C,D解释了AE得到的潜在空间可能不满足凸集的性质,但是将插值后重构的图像优化可以使得插值的过程满足真实数据的潜在空间要求, 从而实现的插值生成的合理性。
GAIA损失函数
接下来讨论的损失函数,我们以GAIA文中给出的伪代码分析(正文把损失函数分开写了)。
对于插值过程采用线性插值,在真实图像编码得到的\(Z_{gen}^1,Z_{gen}^2\)之间插值,即:
\[Z_{interp} = interpolate(Z_{gen}^1,Z_{gen}^2)\]对于生成器的损失要结合判别器一起讨论,因为从实际输入输出来看,输入的是真实图像\(X_1,X_2\),输出的是重构出的\(D(X_1),D(G(X_1)),D(G(Z_interp)),D(G(X_2)),D(X_2)\)。 生成器的目的是最小化输入与生成图像的误差,整体上是最小化:
\[\Vert X - D(G(X)) \Vert_1 + \Vert G(Z_{interp}) - D(G(Z_{interp})) \Vert_1\]对于判别器,则是最小化真实图像的像素误差,最大化生成图像的像素误差,整体上是最小化(注意负号):
\[\Vert X - D(X) \Vert_1 - \Vert X - D(G(X)) \Vert_1 - \Vert G(Z_{interp}) - D(G(Z_{interp})) \Vert_1\]通过网络优化得到的插值过程生成图如下:

GAIA实验
为了在高维数据中保留局部结构,在数据的潜在空间\(Z\)和原始高维数据集\(X\)之间施加正则化,对于一个Batch下,计算了\(X\)和\(Z\)空间中样本的 成对欧几里德距离的对数之间的距离损失:
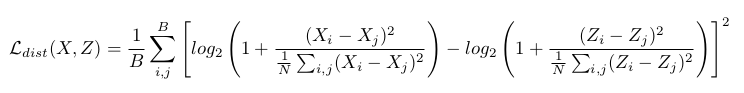
文中将此误差项应用于发生器,以促使潜在空间中的小批量的成对距离类似于原始高维空间中的小批量的成对距离。
对于GAIA整体的设计上,文中也给出了一些Trick,比如稳定训练网络,文中采用以零为中心的sigmoid来平衡GAN的损失:
\[sigmoid(d) = \frac{1}{1+e^{-d*b}}\]其中b是sigmoid斜率的超参数,d是在网络中平衡的两个值之间的差。此时判别器的参数平衡的学习率为:
\[\delta_{Disc} \gets sigmoid(\Vert X - D(X) \Vert_1 - (\Vert X - D(G(X)) \Vert_1 + \Vert G(Z_{interp}) - D(G(Z_{interp})) \Vert_1)/2)\]相对应的生成器的学习率:
\[\delta_{Gen} \gets 1 - \delta_{Disc}\]细节可参看文中给出的伪代码。
为了比较图像的高级特征语义,文中采用了最小二乘回归训练来预测特征属性的Z表示。什么意思呢?以人脸为例,人脸有一个共有的特征, 但是也包含了一些高级的特征,比如金发、白皮肤等。这些高级特征影响整个数据集的数据生成,如果整个数据集的高级特征比例不一致的话, 很可能生成的图片偏向于某一高级特征。一般的高级特征向量的获得是采取平均值相减,即\(Z_{feat} - Z_{nofeat}\)然后将特征向量加到或减去各个面\(Z_i\) 的潜在表示,再通过解码器得到高级特征的图像。
但是,实验发现这些特征经常在CELEBA-HQ数据集中纠缠在一起。例如,在生成old人脸时图像偏向男性,Young人脸时图像偏向女性。 这可能是由于年轻男性与老年男性的比例为0.28:1,而CELEBA-HQ数据集中年轻女性与年长女性的比例大得多,为8.49:1造成的。为了克服这个问题, GAIA使用普通的最小二乘回归训练来预测特征属性的Z表示,并使用模型的系数作为特征向量。下图显示了这些特征与单独减去均值相比不那么交织。

下面是GAIA生成的属性图像和与其它模型对比图像。


总结
GAIA中生成器和判别器都采用Autoencoder结构设计,这样保证了数据经过Encoder得到的潜在空间的高维特性,在损失函数上通过生成器和判别器最大最小像素误差达到对抗, 从而实现生成的图像清晰,文中对潜在向量间插值采用训练优化,生成的结果也很合理。
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







