Lip Movements Generation at a Glance论文解读
跨模态生成在GAN和VAE的冲击下渐渐的被人关注,高维数据的生成本来就很有挑战,跨模态生成更是困难重重,之前也写过几篇跨模态生成的论文解读, 今天看一下ECCV 2018的一篇跨模态生成的文章Lip Movements Generation at a Glance。文章关注于 人物发声音频到人物唇部运动视频的生成,想象一下让文弱女子朗读豪放派诗词的嘴部动作是不是还蛮有意思的,哈哈。
论文引入
跨模态生成旨在基于不同模态的信息合成一种模态或几种模态数据。文本到图像、文本到视频、音频到图像、音频到视频等这种单向或双向的生成都是跨模态生成的案例。 在我的阅读范畴下,文本到图像的代表作是GAN-CLS这篇文章对于跨模态生成的启发性是很大的, 特别是文章中不同模态在GAN中判别器下配对的思想;文本到视频的代表作有To Create What You Tell(TGANs-C), 这篇文章我写过解读,感兴趣的可以移步这里,文章在不同判别器的设计上让人影响深刻; 音频到图像的代表作有CMAV,文章首次实现音频和图像的模态转换生成,论文解读在这里; 音频到视频的代表作有Visual to Sound,论文解读在这里。
音频到唇部运动视频的生成实现对于听觉障碍者是有用的,听力障碍的人在经过训练后可以通过人物唇部运动来猜测出发言者的言论。唇语的解读全靠人物唇部 运动的观察与分析,所以唇部运动视频是有意义的。唇部运动离不开对应的音频,只有音频和唇部运动结合才是一段有意义的视频。Lip Movements Generation at a Glance 通过输入一段音频和目标人的一张唇部图像生成对应于音频的目标人唇部运动视频。不考虑目标人物性别的话,理论上一段音频可以实现任意唇部图像下的 唇部运动视频。
在已有的唇部运动视频的合成往往是在检索下实现的,这就需要大量的目标身份的唇部发音图像,而这篇论文Lip Movements Generation at a Glance 完全是在做生成,我们先来看一下实验的效果:
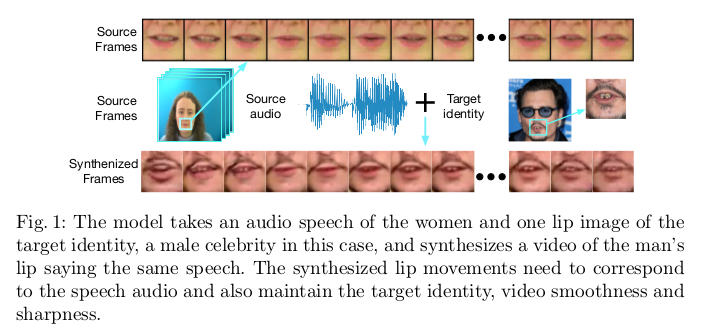
正如文章的题目中用的Glance一样,只需要一张目标身份的唇部图像就可以实现一段唇部运动视频。文章也给了实验展示的视频(Youtube视频需要翻墙):
总结一下文章的优势:
- 第一个考虑语音和唇部运动之间的相关性,一目了然地生成多个唇部图像
- 构建和训练唇部运动发生器网络时探索各种模型和损失函数
- 量化了评估指标,对训练集外的唇部图像依然适用
模型结构
我们还是先来看一下模型结构:
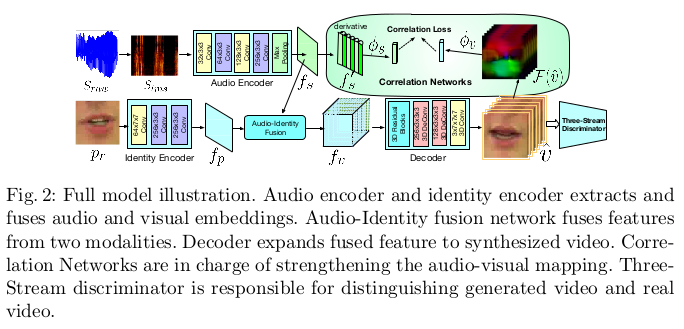
我们从整体上分析一下这个模型。模型的输入是一段音频和目标人物的唇部图像,输入音频记为$S_{raw}$,输入的唇部图像记为$p_r$。音频$S_{raw}$ 先转换为对数幅度Mel频谱(LMS),将原始音频波形转换为时频域, 经过音频编码器提取到音频的特征$f_s$;唇部图像$p_r$经过编码器得到图像特征$f_p$,将音频特征$f_s$和唇部图像特征$f_p$做融合送入解码器下生成 对应音频的唇部动作视频,优化生成的唇部动作视频由GAN来实现,判别器采用“三流判别器”(后面解释)。为了增强音频和视频的关联程度,模型设计了 关联损失Correlation Loss。
模型的整体上是这个流程,我们接下来展开再看一下。
对于音频和图像的编码不需要说明,都是采用卷及神经网络(CNN)提取特征,为了实现音频和视频的一一对应,对提取的音频和图像特征做融合处理。
音频-唇部图像特征融合
对于音频提取的特征$f_s \in \mathbb R^{T \times F}$,其中$T$为时间帧,$F$为频率信道。对于唇部图像提取的特征$f_p \in \mathbb R^{H \times W}$, 其中$H$为高,$W$为宽。融合的过程如下图展示:
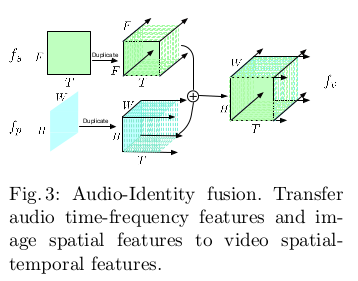
需要对音频特征$f_s$通过复制将形状变换为$T \times F \times F$,对于唇部图像特征$f_p$将形状变换为$T \times H \times W$。在处理中要保证 $H = W = F$,融合就是把改变过的音频和唇部图像特征做连接即可。
音频视频关联损失
音频语音的声学信息与唇部运动相关,因为它们共享高级别的表达。两个模态之间沿时间轴的变化更可能是相关的,换句话说,与唇形本身的声学特征和视觉特征相比, 音频特征的变化(例如,提高到更高音高的声音)和视觉特征的变化(例如,嘴巴张开)具有更高的相关性。音视频在时间对齐上不是一一对应的,通常唇形的改变比声音更早出现。 例如,当我们说“bed”这个词时,上嘴唇和下嘴唇在说出单词之前会相遇。在实验上也得到了这个唇形和音频的延迟是非固定的:
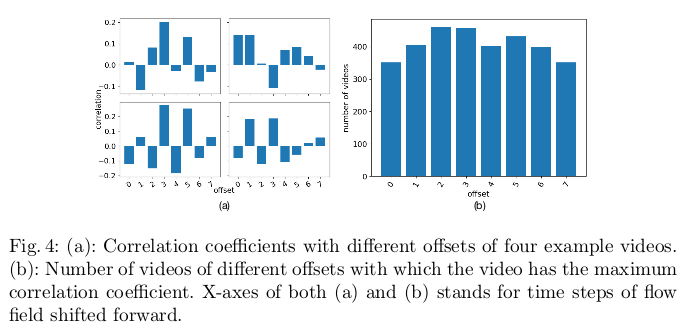
优化特征空间中两种模态的相关性是实现音频视频生成的必要,文章通过关联损失来优化生成。$\phi_s$是音频导数编码网络,$\phi_v$是视频的光流编码网络, 之所以采用音频导数编码网络就是考虑唇形和音频时间上不对齐的问题,关联损失设计为:
\[\mathcal L_{corr} = 1 - \frac{\phi_s(f_s^,) \cdot \phi_v(\mathcal F(v))}{\Vert \phi_s(f_s^,) \Vert_2 \cdot \Vert \phi_v(\mathcal F(v)) \Vert_2}\]像素损失
这部分就是在像素层面上做重构误差,主要是对生成唇形视频上。
\[\mathcal L_{pix}(\hat{v},v) = \Vert v - \hat{v} \Vert\]特征匹配损失
特征匹配损失在GAN下的生成上已经得到了很多的使用,文章定义为感知损失,就是在判别器的中间特征层做优化损失:
\[\mathcal L_{perc}(\hat{v},v) = \Vert \varphi (v) - \varphi (\hat{v}) \Vert_2^2\]这里的$\varphi$为判别器的中间特征层的输出口。
三流判别GAN
文章说三流判别,其实就是利用了匹配的思想,这个在之前的解读的跨模态生成的论文中也被使用,对于判别器只有真实音频和真实唇形视频判为真, 真实音频和生成唇形视频为假,真实音频和不对应的唇形视频为假。(这个思想最早是来自文本到图像的GAN-CLS一文中)
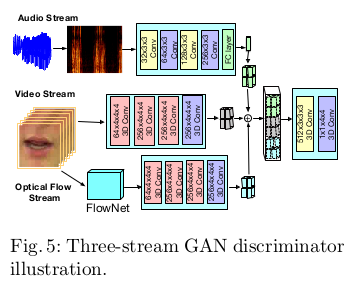
对应的目标损失为:
\[\mathcal L_{dis} = -log D([s^j,v^j]) - \lambda_p log(1 - D([s^j,\hat{v}])) - \lambda_u log(1 - D([s^j,v^k])), k \neq j\]其中$v_k$就是和音频不对应的唇形视频,定$\lambda_p$和$\lambda_u$为0.5。
最后整体的损失就是上面损失的优化:
\[\mathcal L = \mathcal L_{corr} + \lambda_1 \mathcal L_{pix} + \lambda_2 \mathcal L_{perc} + \lambda_3 \mathcal L_{gen}\]其中$\lambda_1, \lambda_2,\lambda_3$为控制比重的超参,文中设置为0.5,1.0,1.0。
实验
文章在GRID,LRW和LDC 数据集上进行实验。GRID中有33个不同的发声人,每位演讲者都有1000个短片;LRW数据集包含数百个不同发言者所说的500个不同的单词;在LDC数据集中有14个发言者, 其中每个发言者阅读238个不同的单词和166个不同的句子。GRID和LDC中的视频是实验室录制的,而LRW中的视频是从新闻中收集的。数据集信息如下:
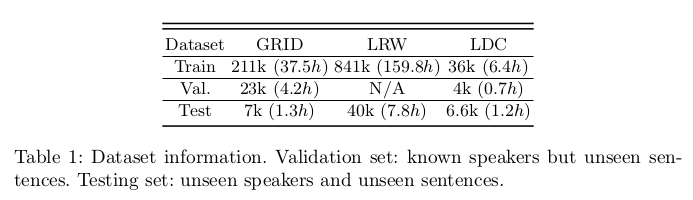
实验上数据由两部分组成:音频和图像帧。网络可以输出不同数量的帧,文章只考虑生成16个图像帧。当视频以25fps采样时,合成图像帧的时间跨度为0.64秒。
实验评估上采用峰值信噪比(PSNR)和结构相似性指数测量(SSIM)为了评估生成的图像帧的清晰度,采用基于感知的无参考物镜图像清晰度度量(CPBD), 最后为了评估合成视频是否对应于基于输入音频的精确唇部运动,通过LandMark Distance(LMD)来提出新度量(详细的说明参看原论文)。 在实验下LMD越小越好,其它度量越大越好。
在模型自身的损失选择上,实验如下:

实验可以说吗各种损失设计的必要性和作用。
在定量上,论文也展现了一定的优势:
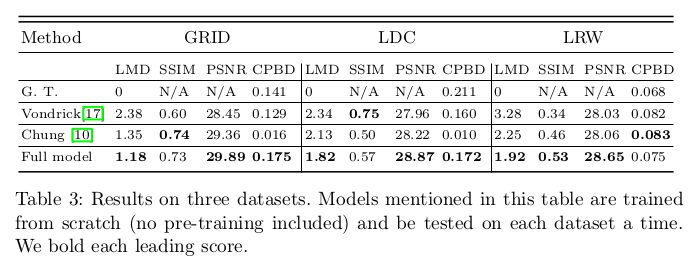
定性上也展示了较好的生成效果:

总结
这篇论文实现了给定任意音频语音和任意目标身份的一个唇部图像,生成表达语音的目标身份的合成唇部动作视频。为了达到良好的效果,不仅要考虑目标身份的保留, 合成图像的照片般逼真,视频中图像的一致性和平滑性,还要学习语音音频和语音之间的相关性。文章设计了四种损失做优化,在音视频的关联损失上给人的启发还是很大的。
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







