Visual to Sound论文解读
人的视觉和听觉是紧密相连的,同时视觉和听觉是人类感知世界的来源。寻求视觉和听觉的转换在很多领域都有很大的意义,论文 Visual to Sound: Generating Natural Sound for Videos in the Wild实现了视觉到语音的 完整转换,最终的效果就是输入一段视频输出一段对应的音频。这和之前的CMAV还有所不同,CMAV虽然也实现了 视觉到听觉的转换,但是最终输出的听觉仅仅是语音的LMS声谱图,今天我们一起看一下这篇论文实现的思路。
论文引入
盲人理解世界的根源来自于听觉、触觉、嗅觉,但是主要的来源还是来自听觉。盲人的听觉系统十分敏感,可谓是落针可闻,但是听觉不搭配视觉的话往往会带来麻烦。 比如在嘈杂的环境下的听觉往往起不到很好的作用,所以适当的视觉协助对于盲人的出行会起到很大的帮助。视觉和听觉可以说是人类感知周围环境最重要的渠道, 而且它们经常被缠绕在一起。通过对自然世界的终生观察,人们能够学习视觉和声音之间的关联。例如,当在天空中看到一道闪电时,人们可能下意识地捂住耳朵, 知道雷声即将来临。或者,听到叶子在风中沙沙作响,可能会想起一幅宁静的森林景象。
利用深度学习掌握视觉到听觉的关系是十分有意义的,这种关系的模型可能是许多应用的基础,例如将视频与自动生成的环境声音相结合,以增强虚拟现实中的瞬态体验; 自动为视频添加声音效果,减少繁琐的手动声音编辑工作;或者通过将视觉信息与视觉信息相关联来实现平等可访问性(允许他们通过声音“看到”世界)。 基于可视内容生成视频音频是联系视觉和听觉关系的基础,CMAV实现了图像和语音声谱图的相互转换,文中的音频是在室内录制的,所以对于自然声音不一定会起到很好的作用。
目前语音合成的技术主要是利用WaveNet和SampleRNN,在文本到语音(TTS)是一直研究的热点, WaveNet提出了一种具有扩张结构的卷积神经网络, 可根据之前生成的数字预测新的音频数字。SampleRNN也在TTS中实现了不错的结果,SampleRNN提出了一种分层递归神经网络(RNN),以在时间上递归地生成原始波形样本, 其分层RNN结构显示了处理长序列生成的能力。
Visual to Sound: Generating Natural Sound for Videos in the Wild论文简称为V2S可以处理开放收集的视频中产生自然声音,为了实现这一过程, 引入了一个从AudioSet中派生出来的数据集。AudioSet是为音频事件识别而收集的数据集,但不适合此任务, 因为许多视频和音频都是松散相关的;目标声音可能被其他声音(如音乐)覆盖;并且数据集包含一些错误分类的视频。所有这些噪声源都会阻碍模型学习从视频到音频的正确映射, 为了缓解这些问题,文章通过分别验证视频和音频的目标对象的存在(每隔2秒)来清理数据的子集,包括人/动物的声音和其他自然声音,以使它们适合于生成任务。
V2S整体上采用对视频利用VGG网络做编码,将编码的隐变量送入声音生成器达到同步生成相应的音频,整体的优势总结一下有:
- 可从在开放的视频中产生声音
- 发布了一个包含28109个清理过的视频(总共55个小时)的数据集,涵盖了10个对象类别
- 探索了生成架构的模型变体
- 提供了数值和人工评估以及生成结果的分析
数据集预处理
AudioSet是一个基于音频事件组织的大型以对象为中心的视频数据集。它包含了家禽,婴儿哭泣,引擎声音等事件, Audioset包含来自Youtube的10秒视频剪辑(带有音频), 但作为设计用于音频事件检测的数据集,由于以下三个原因,AudioSet仍然无法完全满足同步生成的需求。首先,视觉和声音不一定直接相关。例如,有时声音源可能不在帧内。 其次,目标声音可能已经被其他噪声(如背景音乐)所覆盖。第三,存在错误分类。
为了使数据对生成任务有用,从AudioSet中选择某些视频子集并进一步清理已达到目的。实验从AudioSet中选择10个类别(每个类别包括超过1500个视频)以进行进一步清理, 所选择的数据包括人/动物声音和环境声音(特别是:婴儿哭声,人类呼吸声,狗声,水流,烟火,铁路运输,打印机,鼓,直升机和电锯)。
清理采用Amazon Mechanical Turk(AMT)进行数据清理,要求turkers在视觉和音频模式下验证视频片段感兴趣的对象/事件的存在。如果两种方式都经过验证, 就认为这是一个干净的视频。对于大多数视频而言,噪音并不会影响整个视频。因此,为了保留尽可能多的数据,将每个视频分成2秒短片以进行单独标记。 对于每个短片段,将视频和音频分开以进行独立注释。
在音频清理上,Turkers提供三种选择:”是 - 目标声音比其他声音(噪声、环境声)占主导地位”,”排序 - 竞争(实力相当)”,”否 - 其他声音占主导地位”; 在视频情理上,turkers用三种选择来注释目标对象的存在:”是 - 目标对象始终出现”,”排序 - 部分出现”,”否 - 目标对象不出现或几乎不出现”。 删除视频和音频标记为“否”的剪辑,并保留“是”和“标记剪辑的排序”以在收集的数据中引入更多变化。最后,将经过验证的相邻短片组合在一起形成更长的视频, 从而产生2-10秒的视频。
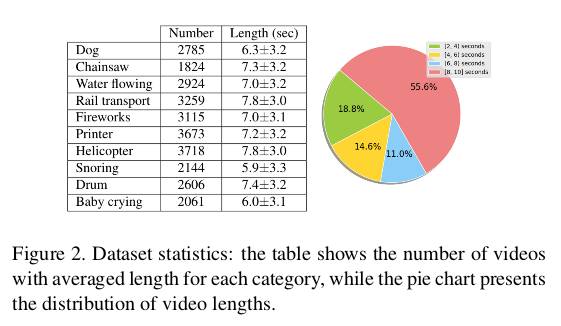
论文在视觉和音频模式中注释了132,209个剪辑,每个剪辑都标记为3个特影,并从原始数据中删除了34,392个剪辑。合并相邻的短片后,共有28,109个视频, 平均长度为7秒,总长度为55小时。下表显示了每个类别的视频数量和平均长度以及标准偏差,饼图显示了长度的分布,表明大多数视频都超过8秒。
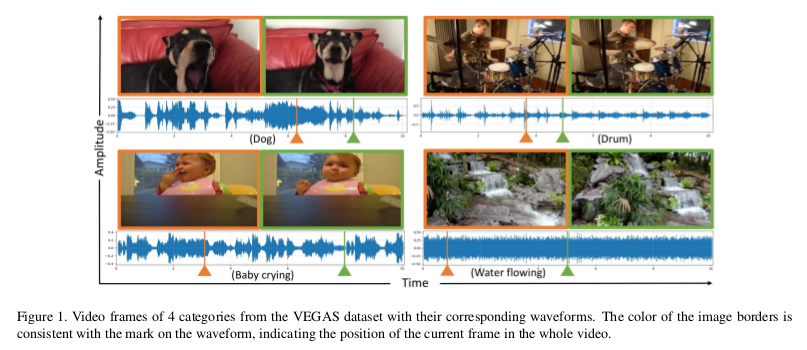
对于视频实例的帧对应的音频波形如下图所示,可以看到声音如何与目标物体的运动以及场景事件相关联,例如水流动(右下方)。
V2S模型框架
V2S的目的是为了给定输入视频(无声)生成出相应的同步音频出来,可以理解为视频为条件输入,输出就是根据视频得到的音频,次条件概率可以表示为:
\[p(y_1,y_2,...,y_n \vert x_1,x_2,...,x_m)\]这里的$x_1,x_2,…,x_m$代表视频帧,$y_1,y_2,…,y_n$代表输出的音频波形图,通常$m \ll n$,因为音频的采样率远高于视频的采样率, 因此音频波形序列比同步视频的视频帧序列长得多。V2S的整体框架采取编码器 - 解码器架构,模型由两部分组成:视频编码器和声音发生器。 下图为模型框架的整体结构:
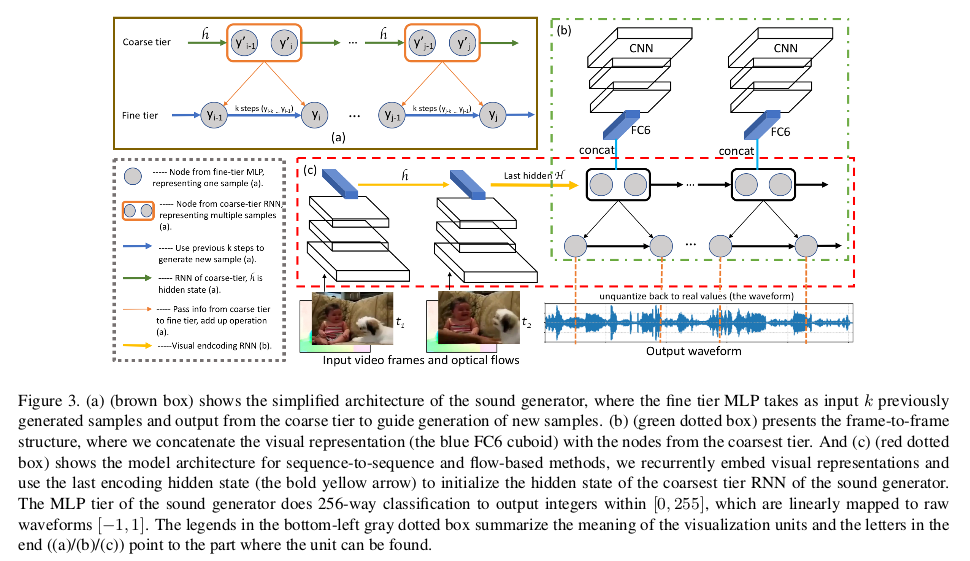
(a)棕色框显示了SampleRNN模型的简化概述;(b)绿色虚线框呈现帧到帧结构;(c)红色虚线框序列到序列和基于流的方法的模型架构。从宏观上分析这个模型, 可以看到右上方为视频帧到帧通过VGG19提取到特征经过FC层得到特征空间,此特征空间包含了视频帧的固有特征,为了更好地反应视频内部的时序和运动敏感, 加入了序列到序列和基于光流的方法。通过帧到帧,序列到序列,基于光流得到的特征最后送入到声音发生器中,从而构建同步的音频信号。 我们接下来详细说一下各个模块。
帧到帧方法
视频帧表示为$x_i=V(f_i)$,其中$f_i$为视频的第$i$帧,$x_i$为对应的视频帧表示,$V(\cdot )$是提取VGG19网络和fc6特征的操作, 该特征已在ImageNet上预先训练,$x_i$是4096维向量。通过将帧表示与声音发生器的初始RNN的节点(样本)一致地连接来编码视觉信息, 由于两种模态之间的采样率不同,为了保持它们之间的对齐,对于每个$x_i$将其复制一次,以便视觉和声音序列具有相同的长度。 这里$s = ceiling [sr_{audio} / sr_{video}]$,其中$sr_{audio}$是音频的采样率,$sr_{video}$视频的采样率。
序列到序列方法
序列到序列模型中,视频编码器和声音发生器清晰地分开,构建了一个递归神经网络来编码视频特征。这里使用相同的深度特征(VGG19的fc6层)来表示视频帧 在视觉编码(即深度特征提取和循环处理)之后,使用来自视频编码器的最后隐藏状态来初始化声音发生器的初始RNN的隐藏状态,然后开始声音生成。 因此声音生成任务变为:
\[p(y_1,y_2,...,y_n \vert x_1,x_2,...,x_m) = \prod_{i=1}^n p(y_i \vert H,y_1,...,y_{i-1})\]基于光流方法
为了反应视频帧与帧之间的关系,更好地捕捉视频帧对运动的敏感,文中提出了基于光流改进模型。视觉领域中的运动信号,即使有时是微妙的, 对于合成逼真且同步良好的声音也是至关重要的,例如,犬叫的声音应该在狗张嘴的时候产生,同时伴随着身体开始向前倾。使用VGG特征是在对象分类任务上预先训练的, 这通常导致具有旋转和平移不变性的特征。尽管VGG功能是沿着连续的视频帧计算的,这些视频帧隐含地包含一些运动信号,但它仍然无法捕获它们。 因此,为了明确地捕获运动信号,在视觉编码器中添加了基于光流的深度特征,并将此方法称为基于光流的方法。这一块实现上和序列到序列一起组成(c) 最终输出的维度也是4096维。
将帧到帧(b)和序列到序列以及光流法(c)得到的特征空间最终送入声音生成器初始RNN下,用于生成音频信号。
V2S实验
实验对比了三种方法得到的结果,实验定性分析上在四个类别的结果从左到右显示:狗,烟花,鼓和铁路运输的音频输出的结果:
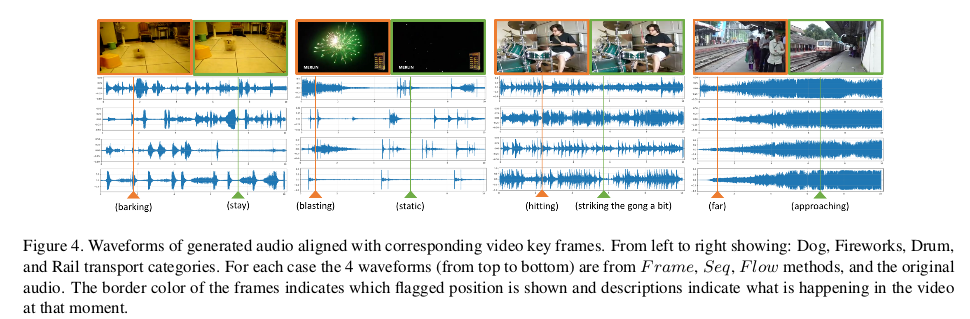
从图中可以看到,在烟花示例(左起第二个)中,与真实音频相比,Flow显示了几个额外的光爆炸(高峰)。当我们看到它时,这些额外的峰值听起来像是远处的爆炸, 这恰好适合现场。铁路运输类别对物体的特定速度并不敏感,但是某些视频(例如描述的示例)具有明显的特性,即声音的幅度受目标物体距离的影响(当火车接近时)。 三个模型下都可以看出这种效果。实验为了进一步说明又做了定量分析,定量分析上采用平均交叉熵损失:
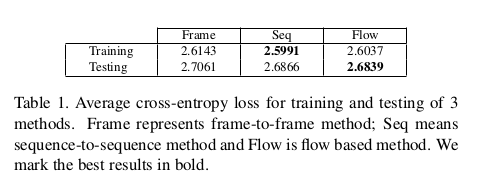
可以看到Flow和Seq方法比Frame方法得到的结果更低,反映出了一定的优势。Seq方法具有最低的训练损失,而Flow在测试损失方面效果最佳。对于生成的波形 直接定量评估是不充分的,文中还设计了检索实验,其中视觉特征被用作查询,检索出具有最大采样可能性的音频。所有测试视频的音频被组合到1280个音频的数据库中, 并且测量每个测试视频的音频检索性能。下表显示了类别和实例检索的平均top1和top5检索准确性。
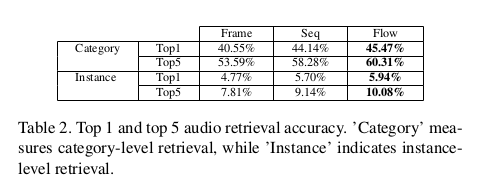
可以观察到所有方法都明显优于偶然性(类别检索的机会为10%,例如检索为0.78%),其中基于光流的方法在两个度量下都实现了最佳准确度。
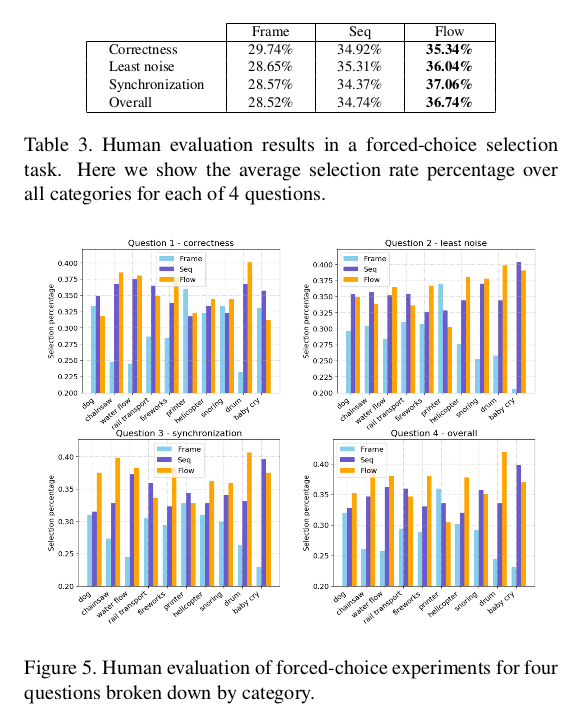
为了进一步说明实验,还进行了人为评估,在四个标准上做出选择1)产生的声音的正确性(哪一个听起来最可能来自视觉内容); 2)含有最少的刺激性噪音; 3)最佳时间与视频同步; 4)他们更喜欢整体。下图展示了三个方法下的对比结果,可以看出seq和Flow要优于Frame。
总结
V2S将视频帧作为输入从而生成相对应的同步音频,整体采用编码解码的思想,通过对视频帧提取特征得到编码后的特征空间,再通过声音生成器(由SampleRNN组成) 实现了视频输入音频输出。但是V2S的整体上仍然是视频到音频的单向过程,如果将原始的声音波形直接转换到视频信号在此框架下是无法实现的, 同时对原始的语音波形上的处理是困难的,S2V的仍然是个有待解决的问题。
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







