Sphere GAN(论文解读)
GAN是通过积分概率度量实现数据分布的拟合,从原始的GAN一路发展下来经过了多次重大的改进。Wesserstein距离代替了原始GAN中KullbackLeibler(KL)散度,从而提出了WGAN;梯度惩罚下的WGAN-GP;MMD GAN匹配在希尔伯特空间中单位球上定义的有序矩;SNGAN为代表的参数归一化的实现;Cram’er GAN使用能量距离来训练GAN。这些改进都在对判别器进行约束,本博客将介绍的Sphere GAN使用超球面来绑定目标函数中的积分概率度量(IPM),实现了更加快捷稳定的GAN的训练,同时这篇论文也被选作CVPR 2019 Oral。
论文引入
自Goodfellow等人提出生成对抗网络(GAN)[1]引起了很多研究兴趣,它们已被用于在各种计算机视觉应用中并实现了卓越性能,包括图像生成、超分辨率、视频预测、风格迁移、图像修复、图像编辑、视觉跟踪、三维重建、图像分割、物体检测、强化学习和医学成像等。
GAN现在已经得到普及式的推广,传统的GAN试图最小化生成数据和真实数据之间的分布差异。为此目的,生成器试图产生看起来像真实数据的所需样本,判别器试图将它们与实际数据区分开。尽管GAN已经成功地应用于各种任务,但是训练它们非常困难,常见的两大问题就是训练上的不稳定(一旦判别器训练到最优状态,生成器会出现参数的梯度消失)、生成的多样性不足(GAN训练上对数据分布的记忆性)。
随着深度学习的训练模型的硬件进步,改进的GAN已经取得了足以以假乱真的实验结果,例如BigGAN、StyleGAN、FUNIT都是深度学习巨头公司的杰作。作为大众研究者,我们更希望看到的是对GAN进行理论上的改进,Sphere GAN的出发点也在于此,并将重点放在基于积分概率指标(IPM)GAN上,以克服上述问题。基于IPM的GAN将梯度惩罚项或改进项插入到目标函数中以实现模型稳定学习,然而,这些附加约束不可避免地引入了需要调整的额外超参数,从而导致更高的计算成本。此外,许多基于IPM的GAN也带来了基于样本的约束策略的不稳定行为,
Sphere GAN是一种新颖的基于IPM的GAN,通过使用几何矩匹配并利用数据的高阶统计信息,从而获得准确的结果。因为矩形匹配是在超球面上进行的,所以Sphere GAN的IPM可以是有界的。文章也证明了超球面引起的几何约束使得GAN训练更加稳定。Sphere GAN并不依赖于传统的基于IPM的GAN的虚拟采样技术和附加的梯度惩罚项,而是利用数学理论支持的黎曼流形下超球面进行实现。
总结一下Sphere GAN的优势:
- Sphere GAN是利用黎曼流形在GAN目标函数中定义IPM的第一次尝试
- 第一个基于IPM的GAN下不使用梯度惩罚或虚拟数据采样技术
- Sphere GAN的良好性能在数学上得到证实
Sphere GAN
为了更加直观的介绍Sphere GAN,我们先来回顾一下基于Wasserstein度量GAN直接匹配一维特征空间中实现方式,WGAN[2]模型的目标函数如下:
\[\min_G \max_D \mathbb E_{x \sim \mathcal P}[D(x)] - \mathbb E_{z \sim \mathcal N}[D(G(z))]\]如果大家对WGAN比较熟悉的话,上述目标函数应该很好理解,G和D分别对应着生成器和判别起参数,$\mathcal P$是真实数据分布,$\mathcal N$为先验噪声分布。Wasserstein度量下判别器将样本映射到实数域进行损失优化,$D:x \in \mathcal X \to \mathbb R$。其中D应满足$1- Lipschitz$条件,图像样本$x \subset \mathbb R^n$是n维欧几里得图像空间,判别器是将n维图像空间映射到一维特征空间下。
我们再来看一下Sphere GAN的目标函数:
\[\min_G \max_D \sum_r \mathbb E_{x \sim \mathcal P}[d_s^r(N,D(x))] - \sum_r \mathbb E_{z \sim \mathcal N}[d_s^r(N,D(G(z)))]\]其中$r=1, \cdots ,R$指的是取的样本对应的索引表示,函数$d_s^r$测量每个样本与超球面北极之间的第$r$个矩距离$N$。与直接匹配一维特征空间的WGAN不同,Sphere GAN匹配在超球面上定义的高阶和多阶。为此,判别器输出一个n维超球,$D:x \in \mathcal X \to \mathbb S^n$,$d_s^r$的下标$s$表示的是在$\mathbb S^n$上定义的。
为了形象的展示这个目标函数的实现意义,我们看一下这个实现超球面度量的结构表示:
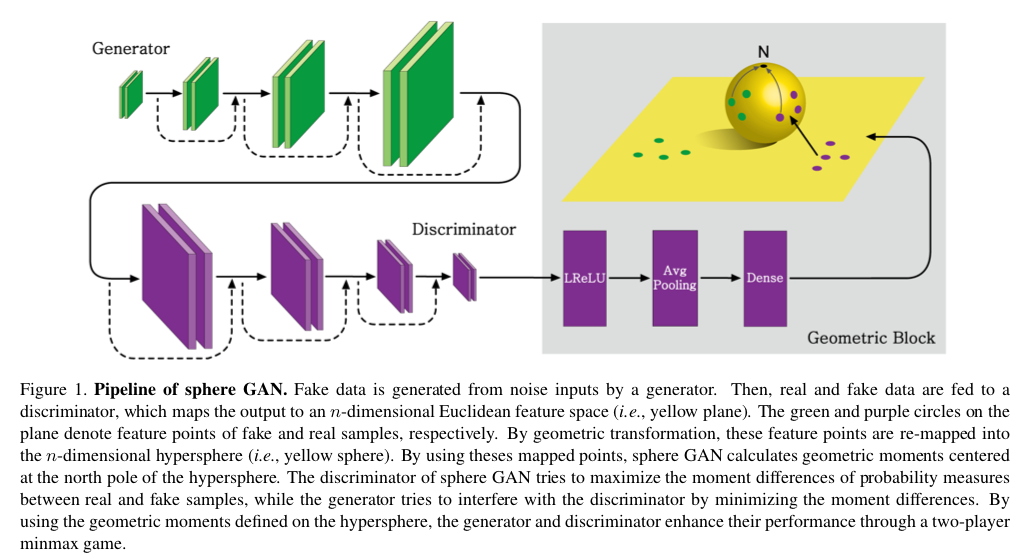
对于生成器和判别器的实现网络没什么要说的,我们看一下判别器最后的输出口是通过将样本映射到欧几里得空间$\mathbb R^n$再投影到超球面$\mathbb S^n$上,通过度量超球面上的点到超球面北极的距离作为最终的确定度量。
判别器的作用就是使得真实样本的超球面下的度量距离和生成样本尽可能的远,而生成器的目的就是为了让这两个度量距离越近越好,从而达到最大最小的对抗,实现对抗优化。
基于Wesserstein距离的传统判别器需要$Lipschitz$约束,这迫使判别器成为$1-Lipschitz$函数的成员。具有不恰当的权重参数λ的约束可能会降低网络稳定并且增加网络训练的压力,例如WGAN-GP[3],WGAN-CT[4]和WGANLP[5]在目标函数中需要额外的约束项来更新判别器。这一种约束在Sphere GAN下是不需要的,通过匹配在超球面$\mathbb S^n$上定义的特征空间上的多个矩,这样就不是在任意的黎曼流形取实现界限约束。
我们再来梳理一下这个过程。传统的GAN通常将欧几里德空间$\mathbb R^n$视为欧几里德距离,这些GAN可以通过对任意黎曼流形进行建模来扩展。这些流形是不紧凑的,距离函数不受限制,可能导致梯度爆炸和学习不稳定。Sphere GAN使用几何感知变换函数,该函数将欧几里德空间$\mathbb R^n$变换为超球面$\mathbb S^n$,这个变换函数是微分同胚下的,是可微分的并且可以在特征空间的每个点处保持维度(后续会做展开说明)。
超球面在GAN下的应用带来了以下的优势:
- 超球面的距离函数$d_s^r$是有界的
- 梯度范数与$d_s^r$距离函数对于稳定学习至关重要
- 超球面的黎曼结构适用于GAN
几何感知转换函数
超球面的距离度量是通过欧几里得空间$\mathbb R^n$映射到超球面$\mathbb S^n$上,这是一个立体投影的过程,而且这个立体投影是符合微分同胚的,立体投影的逆可以被认为是将超平面投影到超球面上的一种方式整个过程如下图展示:
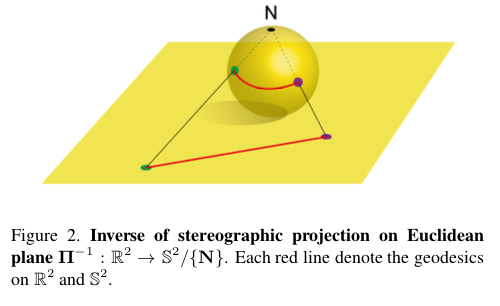
我们先看原文给出的投影定义,假设$p=(p_1,p_2, \cdots , p_n)$点是坐标系$\mathbb R^n$上,$N=(0, \cdots , 1)$为超球面的北极,也就是默认了超球面的半径为1,立体投影$\prod^{-1}:\mathbb R^n \to \mathbb S^n/ \lbrace N \rbrace$的逆定义为: \(\begin{matrix} \prod^{-1} \end{matrix} (p) = (\frac{2p}{\Vert p \Vert^2 + 1},\frac{\Vert p \Vert^2 - 1}{\Vert p \Vert^2 + 1})\) 在$n$维的条件下我们不好理解这个公式是如何投影的,我们不妨将维度降低一些来分析,我们将超球面变为2维的圆,那么欧几里得上坐标就是一个点,我们设北极为$N(0,1)$(圆的半径为1),由北极$N$投影的点为$p(p,0)$,投影在圆上的点为$\hat{p}(x,y)$,现在我们就来表示点$\hat{p}$。
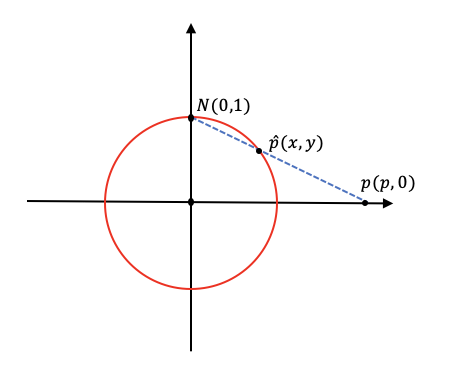
我们由三角形的相似定理可以得到:
\[\frac{y}{1} = \frac{p-x}{p}\]我们再有圆上点的特性有:$x^2 + y^2 = 1$
上述公式化简后平方可得:$p^2 y^2 = p^2 - 2px + x^2$
将$y$用$x$表示可以解得:
\[\begin{cases} x = \frac{2p}{p^2+1} \\ y=\frac{p^2-1}{p^2+1} \end{cases}\]对应在单位圆上可以进一步得到:
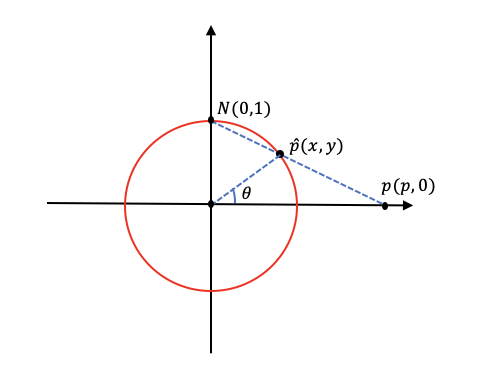
将这个过程上升到$n$维,加上向量的思想后就得到了一开始的立体投影的结果了,我们再来求对应超球面的两点的测地距离$d_r^s$,我们取投影后的两点$p(p,0),q(q,0)$。
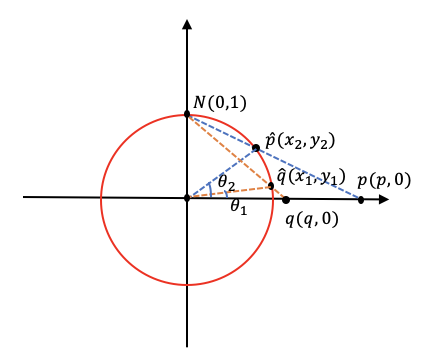
此时的两点的测地距离就是点$p,q$这段弧长,我们由弧长公式$d = \theta \cdot R$可以得到:
\[d = arccos(cos(\theta_2 - \theta_1)) \cdot R\]我们知道半径$R=1$,再由余弦和差公式$cos(\theta_2 - \theta_1) = cos \theta_2 cos \theta_1 + sin \theta_1 sin \theta_2$,由已知的解代入其中:
\[cos(\theta_2 - \theta_1) = \frac{p^2-1}{p^2+1} \cdot \frac{q^2-1}{q^2+1} + \frac{2q}{q^2+1} \cdot \frac{2p}{p^2+1}\]最后整理得到:
\[d = arccos(\frac{p^2q^2 - p^2 - q^2+ 4pq + 1}{(p^2 + 1)(q^2 + 1)})\]将此上升到$n$维超球面就得到了原文中的公式:
\[d_s(\begin{matrix} \prod^{-1} \end{matrix} (p) , \begin{matrix} \prod^{-1} \end{matrix} (q) ) = arccos(\frac{\Vert p^2 \Vert \Vert q^2 \Vert - \Vert p^2 \Vert - \Vert q^2 \Vert + 4pq + 1}{(\Vert p^2 \Vert + 1)(\Vert q^2 \Vert + 1)})\]如图,超球面上两点之间的测地距离比欧几里德距离短得多,并且在超球面(即黄色球面)上有界,因此实现几何变换等效于对超平面施加全局约束,这也保证了训练上的稳定性。
原文为了进一步对Sphere GAN做了数学分析,通过和IPM、Wesserstein距离、梯度进行分析,较全面的对Sphere GAN进行了深入的理论分析,限于篇幅就不展开了,有兴趣的可以自行阅读原文。我们说一下如何在程序的思想上实现立体投影下欧几里得到超平面的逆定义,以及用在GAN下的损失函数的实现:

我们用tensorflow进行实现:
def inverse_stereographic_projection(x) :
x_u = tf.transpose(2 * x) / (tf.pow(tf.norm(x, axis=-1), 2) + 1.0)
x_v = (tf.pow(tf.norm(x_u, axis=0, keepdims=True), 2) - 1.0) / (tf.pow(tf.norm(x_u, axis=0, keepdims=True), 2) + 1.0)
x_projection = tf.transpose(tf.concat([x_u, x_v], axis=0))
return x_projection
对应的度量距离:
def sphere_loss(x, y) :
loss = tf.math.acos(tf.keras.backend.batch_dot(x, y, axes=1))
return loss
我们再把对应的GAN下训练的判别器和生成器的损失整理进来:
def discriminator_loss(real, fake, moment=3):
real_loss = 0
fake_loss = 0
bs, c = real.get_shape().as_list()
# [bs, c+1] -> [0, 0, 0, ... , 1]
north_pole = tf.one_hot(tf.tile([c], multiples=[bs]), depth=c+1)
real_projection = inverse_stereographic_projection(real)
fake_projection = inverse_stereographic_projection(fake)
for i in range(1, moment+1) :
real_loss += -tf.reduce_mean(tf.pow(sphere_loss(real_projection, north_pole), i))
fake_loss += tf.reduce_mean(tf.pow(sphere_loss(fake_projection, north_pole), i))
loss = real_loss + fake_loss
return loss
def generator_loss(loss_func, fake, moment=3):
fake_loss = 0
bs, c = fake.get_shape().as_list()
# [bs, c+1] -> [0, 0, 0, ... , 1]
north_pole = tf.one_hot(tf.tile([c], multiples=[bs]), depth=c+1)
fake_projection = inverse_stereographic_projection(fake)
for i in range(1, moment+1) :
fake_loss += -tf.reduce_mean(tf.pow(sphere_loss(fake_projection, north_pole), i))
loss = fake_loss
return loss
实验
网络训练批次大小为64。在所有实验中,对发生器和鉴别器使用Xavier初始化和Adam优化器,将发生器和判别器的Adam优化器的超参数固定为$\alpha = 1e-4,\beta_1 = 0, \beta_2 = 0.9$。在使用ConvNet的实验中,将moment modes设置为$\sum_1^5d^r$。在其他实验中,将超球面的尺寸设置为$\mathbb S^{1024}$,将moment modes设置为$\sum_1^3d^r$。
需要强调的是作者用于训练的就是单个GTX Titan GPU进行的,在某些大厂的GPU甚至TPU横飞的GAN模型训练下,能用单块GTX Titan GPU完成实验,并且获得CVPR 2019 Oral真可谓是着实不易。
文章在数据集的选择下使用了CIFAR-10,STL-10和LSUN数据集上进行了实验,对于CIFAR-10大家可能很熟悉,STL-10是图像大小为$96 \times 96$,包含10类的自然图像数据集,文章将此调整为$48 \times 48$,LSUN文章选择了卧室作为训练数据,并调整为$64 \times 64$。
文章首先进行了Ablation Study,在不同的矩匹配模式和超球面的不同维度下进行了测试,采用的定量指标是Inception Score:
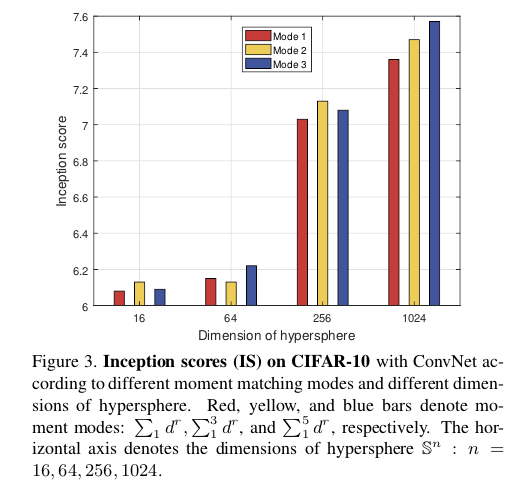
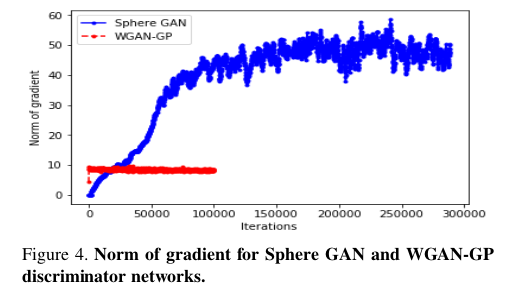
可以看到随着矩匹配模式和超球面维度的增加,得到的结果是增益的,这也符合理论的分析,在训练的稳定性和训练的持续性上,文章对比了WGAN-GP:
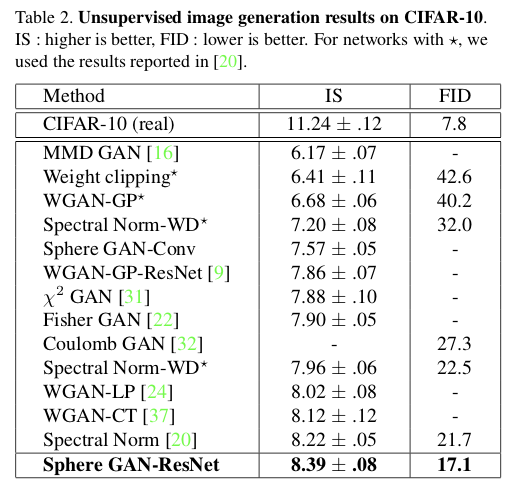
在不同的基于IPM的改进GAN的模型上,文章也做了定量上的IS和FID的对比:
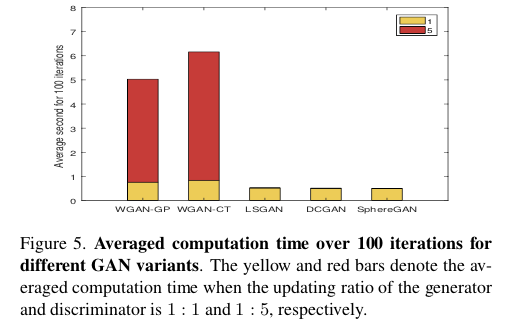
最后,文章还对Sphere GAN训练时间上的优势做了对比:
总结
Sphere GAN是一种新颖的基于IPM的GAN,定义了超球面上的IPM(一种黎曼流形),超球面的黎曼流形提供了有界的IPM使得训练变得稳定。高阶矩匹配使Sphere GAN能够利用有关数据的有用信息并提供准确的结果。实验结果也验证了Sphere GAN确实实现了GAN的又一个不错的方向上的改进。
参考文献
[1] Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]//Advances in neural information processing systems. 2014: 2672-2680.
[2] Arjovsky M, Chintala S, Bottou L. Wasserstein generative adversarial networks[C]//International Conference on Machine Learning. 2017: 214-223.
[3] Gulrajani I, Ahmed F, Arjovsky M, et al. Improved training of wasserstein gans[C]//Advances in Neural Information Processing Systems. 2017: 5767-5777.
[4] Petzka H, Fischer A, Lukovnicov D. On the regularization of Wasserstein GANs[J]. arXiv preprint arXiv:1709.08894, 2017.
[5] Wei X, Gong B, Liu Z, et al. Improving the improved training of wasserstein gans: A consistency term and its dual effect[J]. arXiv preprint arXiv:1803.01541, 2018.

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







