STGAN人脸属性编辑(论文解读)
AttGAN和StarGAN在人脸属性编辑上取得了很大的成功,但当人脸属性之间相互交集或者目标人脸属性比较复杂时,这两种方式对于控制属性的标签上的精细化就显示了些许的不足。STGAN是一个建立在AttGAN基础上的人脸属性编辑模型,通过差分属性标签下选择性传输单元的跳跃连接实现了人脸高精度属性的编辑。
论文引入
图像编辑是计算机视觉下有趣但也具有挑战性的工作,随着生成对抗网络的发展,图像编辑取得了长足的发展,任意属性编辑实际上也转换到了多域图像到图像变换任务。类似于CycleGAN和Pix2Pix等此类单个翻译模型已经取得了一定的成功,但是它在利用整个训练数据方面是无效的,并且学习的模型随着属性的数量呈指数增长。为了解决这个问题,多属性的图像变换模型逐渐涌现,其中最为有名的则是AttGAN[1]和StarGAN[2]了。
这两个模型都是架构在编码器 - 解码器上,同时将源图像和目标属性向量作为输入,AttGAN不是对潜在表示施加约束,而是对生成的图像应用属性分类约束,以保证所需属性的正确变化,同时引入重建学习以保留属性排除细节。StarGAN只用一个generator网络,处理多个domain之间互相generate图像的问题,这是比AttGAN更深一步的人脸属性迁移。
STGAN是建立在这两个模型基础上的人脸高精度属性编辑模型,我们先看一下这三个模型生成的人脸对比:

从上图可以看出这三个模型下虽然所有属性都保持不变,但AttGAN和StarGAN在结果中可以观察到不必要的变化和视觉退化,造成这种结果的主要原因在于编码器 - 解码器的结构限制和目标属性的使用矢量作为输入。STGAN仅考虑要改变的属性,以及在用解码器特征编辑属性无关区域时选择性地连接编码器特征。
仅考虑要改变的属性通过目标和源属性标签之间的差异作为编码器 - 解码器的输入;提出了选择性传输单元(STU)来自适应地选择和修改编码器特征,其进一步与解码器特征连接以增强图像质量和属性操纵能力。总结一下STGAN的优势:
- 将差异属性向量作为输入,以增强属性的灵活转换并简化训练过程
- 设计选择性传输单元并与编码器 - 解码器结合,以同时提高属性操作能力和图像质量
- 实验结果上,STGAN在任意面部属性编辑和图像翻译方面取得了很好的效果
Skip Connection
skip connection在UNet下被广泛使用,翻译过来的话可以称为跳跃连接,skip connection已经在图像语义分割上得到了广泛的应用,同时也不仅仅是限于UNet的设计框架下。STGAN将skip connection应用在模型中,我们知道人脸属性编辑上的架构采用编码器 - 解码器结构,其中空间池化或下采样对于获得属性操纵的高级抽象表示是必不可少的。然而,下采样不可逆地降低了空间分辨率和特征图的细节,这些细节无法通过反卷积完全恢复,并且结果容易模糊或丢失细节。为了提高编辑结果的图像质量,skip connection自然而然的被想到应用在结构中。
为了分析skip connection的影响和限制,作者在测试集上测试了AttGAN的四种变体:1.没有skip connection的AttGAN(AttGAN-ED);2.具有一个skip connection(AttGAN)也就是原版的AttGAN;3.具有两个skip connection的AttGAN(AttGAN-2s);4.具有所有对称skip connection的AttGAN(AttGAN-UNet)。下表和下图显示了对比实验的结果:

可以看出,添加跳过连接确实有利于重建细节,并且随着skip connection的增加可以获得更好的结果。然而,作者又做了人脸属性添加上的对比性实验:
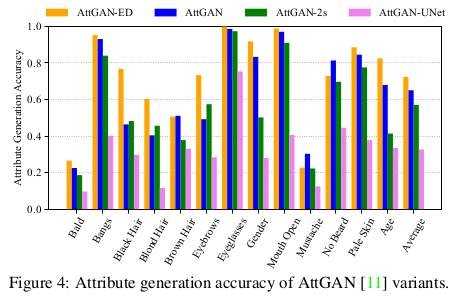
通过分类准确率可以看到,添加多个skip connection却实现了降低指标的作用,我们可以猜测通过skip connection的部署弱化了属性操纵能力为代价改善了重建图像质量,主要归因于该跳过连接直接连接编码器和解码器特征。为了避免这种情况,STGAN采用选择性传输单元来自适应地转换由要改变的属性引导的编码器特征。
选择性传输单元
在介绍选择性传输单元之前,我们先把文章对目标属性和源属性的标签处理交代一下。StarGAN 和AttGAN 都将目标属性向量$Att_t$和源图像x作为输入到生成器。实际上,使用完整目标属性向量是多余的,可能对编辑结果有害。如果目标属性向量$Att_t$与源$Att_t$完全相同,此时,理论上输入只需要对图像进行重构即可,但StarGAN和AttGAN 可能会错误地操作一些未更改的属性,比如把原本就是金色头发变得更加的金色。
对于任意图像属性编辑,而不是完整目标属性向量,只应考虑要更改的属性以保留源图像的更多信息。因此,将差异属性向量定义为目标和源属性向量之间的差异是合适的:
\[Att_{diff} = Att_t - Att_s\]比如男性有胡子戴眼镜的源图编辑到男性无胡子戴眼镜秃头目标图,这里面仅仅是添加了秃头这一属性,减少了胡子这一属性,其它的可以保持不变。$Att_{diff}$可以为指导图像属性编辑提供更有价值的信息,包括是否需要编辑属性,以及属性应该改变的方向。然后可以利用该信息来设计合适的模型,以将编码器特征与解码器特征进行变换和连接,并且在不牺牲属性操纵精度的情况下提高图像重建质量。
选择性传输单元(STU)来选择性地转换编码器特征,使其与解码器特征兼容并互补,而不是通过skip connection直接将编码器与解码器特征连接起来。这个变换需要适应变化的属性,并且在不同的编码器层之间保持一致,作者修改GRU[3]的结构以构建用于将信息从内层传递到外层的STU。我们来看一下STU的结构:
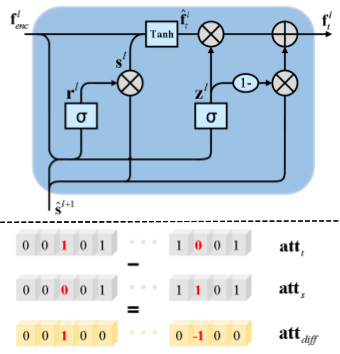
$f_{enc}^l$为编码器第l层输出,$s^{l+1}$为数据编码在l+1层的隐藏状态,隐藏状态$\hat{s}^{l+1}$则是结合了$Att_{diff}$得到的:
\[\hat{s}^{l+1} = W_{t}*_{T}[s^{l+1},Att_{diff}]\]其中$[\cdot , \cdot]$表示为concatenation操作,$*_{T}$为转置卷积,然后,STU采用GRU的数学模型来更新隐藏状态$s^l$和转换后的编码器特征$f_t^l$:
\[r^l = \sigma(W_r * [f_{enc}^l,\hat{s}^{l+1}]),z^l = \sigma(W_z * [f_{enc}^l,\hat{s}^{l+1}]),s^l=r^l \circ \hat{s}^{l+1}\] \[\hat{f}_t^l = tanh(W_h*[f_{enc}^l,s^l]),f_t^l = (1-z^l) \circ \hat{s}^{l+1} + z^l \circ \hat{f}_t^l\]其中$*$表示卷积运算,$\circ$表示逐项乘积,$\sigma (\cdot)$表示sigmoid函数。复位门$r^l$和更新门$z^l$的引入允许以选择性方式控制隐藏状态,差异属性向量和编码器特征。输出$f_t^l$提供了一种自适应的编码器特征传输方法及其与隐藏状态的组合。
选择性传输单元(STU)说白了就是在GRU的结构上实现的,差分标签控制下的编码特征的选择。
模型结构
有了上述的分析,我们再看模型的结构则是比较容易理解了:
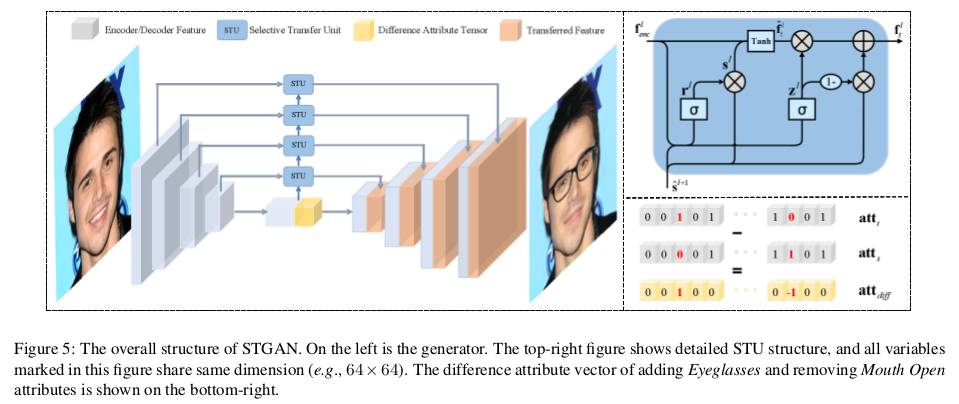
整个模型比较简单,在编码器和解码器过程中,加入STU选择单元,从而获得人脸属性编辑后的输出。编码器的输入端包括源图x和差分属性标签$Att_{diff}$。对于判别器,也是判别生成器输出真假和对应的属性标签。对抗损失采用WGAN-GP来实现生成优化,对应着$\mathcal L_{D_{adv}},\mathcal L_{G_{adv}}$。对于属性标签和生成器的属性优化通过源真实样本和标签优化判别器,再通过判别器去判别目标生成的属性结果来优化生成器:
\[\mathcal L_{D_{att}} = -\sum_{i=1}^c[att_s^{(i)}logD_{att}^{(i)}(x)+(1-att_s^{(i)})(1-logD_{att}^{(i)}(x))]\] \[\mathcal L_{G_{att}} = -\sum_{i=1}^c[att_t^{(i)}logD_{att}^{(i)}(\hat{y})+(1-att_t^{(i)})(1-logD_{att}^{(i)}(\hat{y}))]\]$att_s^{(i)},att_t^{(i)}$为源域和目标域属性标签,文章还加入了一个不使用标签的重构误差,也就是差分标签置为0:
\[\mathcal L_{rec} = \Vert x - G(x,0) \Vert_1\]最终得到的损失为:
\[\min_D \mathcal L_D = -\mathcal L_{D_{adv}} + \lambda_1 \mathcal L_{D_{att}}\] \[\min_G \mathcal L_G = -\mathcal L_{G_{adv}} + \lambda_2 \mathcal L_{G_{att}} + \lambda_3 \mathcal L_{rec}\]实验
人脸属性编辑的实验建立在CelebA数据集上,CelebA数据集包含裁剪到$178 \times 218$的202,599个对齐的面部图像,每个图像有40个带/不带属性标签。图像分为训练集,验证集和测试集,文章从验证集中获取1,000张图像以评估训练过程,使用验证集的其余部分和训练集来训练STGAN模型,并利用测试集进行性能评估。实验考虑13种属性,包括秃头,爆炸,黑发,金发,棕色头发,浓密眉毛,眼镜,男性,嘴微微开口,小胡子,无胡子,苍白皮肤和年轻,实验中,每个图像的中心$170 \times 170$区域被裁剪并通过双三次插值调整为$128 \times 128$。
定性结果分析上,文章将STGAN与四种竞争方法进行比较,即IcGAN,FaderNet,AttGAN和StarGAN,实验结果如下图所示,可以看出STGAN展示了很好的竞争效果。

定量评估上,文章从两个方面评估属性编辑的性能,即图像质量和属性生成准确性。图像质量上,保持目标属性向量与源图像属性相同,得到了PSNR / SSIM结果:

对于属性生成准确性,STGAN也展示了优秀的结果:
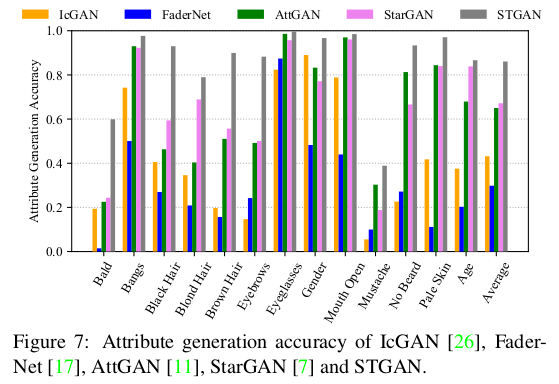
实验在用户的选择测试上也取得了最佳效果,Ablation Study实验上也证实了模型的每一部分的优势和必要。最后放一张STGAN在图像季节转换的实验效果:

总结
文章研究了选择性传输视角下任意图像属性编辑的问题,并通过在编码器 - 解码器网络中结合差分属性向量和选择性传输单元(STU)来提出STGAN模型。通过将差异属性向量而不是目标属性向量作为模型输入,STGAN可以专注于编辑要改变的属性,这极大地提高了图像重建质量,增强了属性的灵活转换。
参看文献
[1] He, Zhenliang, et al. “Attgan: Facial attribute editing by only changing what you want.” arXiv preprint arXiv:1711.10678 (2017).
[2] Choi, Yunjey, et al. “Stargan: Unified generative adversarial networks for multi-domain image-to-image translation.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
[3] Chung, Junyoung, et al. “Empirical evaluation of gated recurrent neural networks on sequence modeling.” arXiv preprint arXiv:1412.3555 (2014).

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







