StarGAN-VC论文解读
GAN的提出和发展让生成模型得到了大大的提高,随着GAN的不断成熟,我们见识到了WGAN, WGAN-GP,LSGAN,BEGAN, iGAN,SAGAN,Bayesian GAN等强大的图像GAN的生成模型。 也见识到了图像到文本生成的GAN-CLS,图像到图像的CycleGAN, Unit,BicycleGAN,图像音频相互转换的CMAV。 今天我们将来看GAN实现音频和音频互相转换生成的文章StarGAN-VC。最终可以实现男声到男声,男声和女声相互转换。
论文引入
语音转换(VC)是一种在保留语言信息的同时转换指定话语的语言信息的技术。VC可以在很多地方得到应用,如文本到语音(TTS)系统的说话人身份(男女,老少等)修改, 口语辅助,语音增强和发音转换。VC的发展也是一直在进步,应用较为广泛的就是基于高斯混合模型(GMM)的发展。这几年随着深度学习的铺开,RNN, GAN以及基于非负矩阵分解(NMF)在VC上也到了应用和发展。但是大部分的VC方法需要精确的将源语音信号和目标语音信号做严格配对,这就使得在一般情况下, 收集这些并行话语是相当困难的。然而即使可以收集这些并行数据,也需要执行时间对齐的操作,当源语音和目标语音之间存在较大的声学间隙时,这种对齐操作就会很麻烦。 目前VC的方法大部分对于并行数据中涉及的对齐处理不是很理想,因此可能需要仔细的预筛选和手动校正才能使这些框架可靠地工作。为了绕过这些限制, StarGAN关注的是实现一种非并行VC方法,它对训练集的要求上既不需要平行话语,也不需要时间对齐造作。
这样使用非并行语音训练在已有的方法上得到的转换后的语音质量和转换效果通常是有限的,实现具有与并行方法一样高的音频质量和转换效果的非并行方法是非常具有挑战性的。 自动语音识别(ASR)的方法大大改善了非并行语音转换,但是这种方法很大程度上取决于ASR的好坏,一旦ASR不稳定整个模型将无法正常工作。还有一些方法的提出, 比如i向量方法,但这种方法在语音转换的身份上受限。在深度学习上, CVAE在非并行语音转换上是成功的,CVAE我想熟悉生成模型的都知道,通过控制条件向量C完成语音间的转换,但是一个问题就是VAE在decoder的结果上是平滑的, 也就是生成的数据有一定模糊,这就导致了转换后的语音的质量不高。我们都知道GAN生成数据是很sharp的,这就是VC的另一个突破点,StarGAN作者就是利用GAN的思想不断完善VC。 StarGAN之前作者还写了一篇CycleGAN-VC,目的旨在学习声学特征从一个属性X到另一个属性Y的映射G和它的逆映射F,后面我们再展开说。
CVAE和CycleGAN虽然在并行数据的要求上没这么多限制但是在测试时必须知道输入语音的属性。对于CVAE-VC,源属性标签c必须被馈送到训练的CVAE的编码器中, 对于CycleGAN-VC,训练和测试时间的源属性域必须相同。VAE-GAN在很多方面都是较为优秀的,但是训练的不稳定是提出StarGAN的一个优势。 vector quantized VAE (VQ-VAE)在VAE的基础上使用了Wavenet网络,在处理非并行数据有了很大的提高,但是也带来了计算量的庞大,需要的训练样本较多。
以上的种种问题,诞生了StarGAN,一个集美貌与才华为一身的存在。StarGAN同时具有CVAE-VC和CycleGAN-VC的优点,但与CycleGAN-VC和CVAE-VC不同的是StarGAN-VC的生成器网络G 可以同时学习多对多映射,其中发生器输出的属性是由辅助输入c控制。与CVAE-VC和CycleGAN-VC不同,StarGAN-VC使用对抗性损失进行生成器训练, 以鼓励生成器输出与真实语音无法区分,并确保每对属性域之间的映射将保留语言信息,StarGAN-VC在测试时不需要任何有关输入语音属性的信息。
最后,总结一下StarGAN的优点:
- 既不需要并行语音同时转录也不需要语音生成器训练的时间对齐
- 可以同时在单个发生器网络中学习使用不同属性域的多对多映射
- 能够足够快地生成转换语音的信号以允许实时实现
- 仅需要几分钟的训练示例来生成合理逼真的语音
CycleGAN-VC模型介绍
我们一起来看一下CycleGAN-VC的模型结构图:
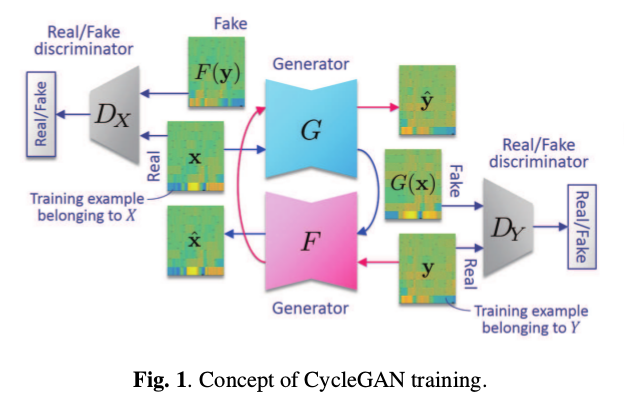
其实CycleGAN-VC在整体框架上和CycleGAN处理图片是一致的,只是我的输入从图片-图片换成了音频-音频而已。我们一起把网络屡一下,音频\(x\)通过G网络生成音频\(\hat{y}\), 音频\(y\)通过F网络生成音频\(\hat{x}\),音频\(x\)与生成的\(\hat{x}(F(y))\)送入判别器\(D_X\)判断真假,音频\(y\)与生成的\(\hat{y}(G(x))\)送入判别器\(D_Y\)判断真假。 为了实现循环的思想,将生成的\(\hat{x}\)送入G网络得到\(\hat{y}\),同样的将生成的\(\hat{x}\)送入G网络得到\(\hat{y}\)。因为是存在两个生成器, 两个判别器,所以对抗损失也有两个;为了保证循环生成的质量,还有一个循环损失;最后为了保证特征学习,再加上一个身份损失(id loss)。
\[\begin{cases} L_{adv}^{D_Y} = -E_{y \sim p_Y(y)}[log D_Y(y)] - E_{x \sim p_X(x)}[log(1 - D_Y(G(x)))]\\ L_{adv}^{G} = E_{x \sim p_X(x)}[log(1 - D_Y(G(x)))]\\ L_{adv}^{D_Y} = -E_{x \sim p_X(x)}[log D_X(x)] - E_{y \sim p_Y(y)}[log(1 - D_X(F(y)))]\\ L_{adv}^{F} = E_{y \sim p_Y(y)}[log(1 - D_X(F(y)))]\\ L_{cyc}(G,F) = E_{x \sim p_X(x)}[\Vert F(G(x)) - x \Vert_1] + E_{y \sim p_Y(y)}[\Vert G(F(y)) - y \Vert_1]\\ L_{id}(G,F) = E_{x \sim p_X(x)}[\Vert F(x) - x \Vert_1] + E_{y \sim p_Y(y)}[\Vert G(y) - y \Vert_1]\\ I_{G,F}(G,F) = L_{adv}^{G} + L_{adv}^{F} + \lambda_{cyc}L_{cyc}(G,F) + \lambda_{id}L_{id}(G,F)\\ I_D(D_X,D_Y) = L_{adv}^{D_Y} + L_{adv}^{D_Y} \end{cases}\]其中\(\lambda_{cyc} \geq 0\),\(\lambda_{id} \geq 0\)。
StarGAN-VC模型介绍
说完CycleGAN-VC后,StarGAN-VC模型就好说明了,我们一起来看看StarGAN模型框架:
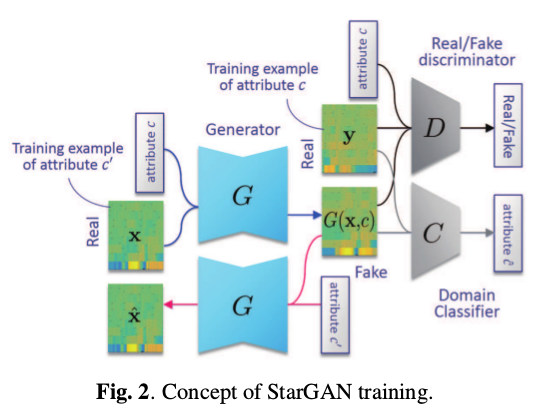
与CycleGAN-VC不同的是StarGAN-VC生成器和判别器只有一个,但是可以实现不同属性的声音的生成。我们以一段原始音频为例,如果给定男性的属性C, 那么经过网络后会生成出男性的音频。我们从头分析一下模型,整个框架有3部分组成,生成器G,判别器D,分类器C。一段音频\(x\)加上属性\(c\) 经过生成器G得到具有属性\(c\)的音频\(G(x,c)\),属性\(c\)下的真实音频\(y\)与生成音频\(G(x,c)\)送入判别器判断真假,此时为了保证属性也还需要属性标签\(c\) 的参与。为了很好的将属性标签分开,训练了分类器C,通过优化标签c和属性音频的匹配达到分类器的优化,从而让每一个属性音频之间可以很好的区别, 同时也让生成的属性音频之间尽可能的有各自的属性特点。同样的为了达到循环优化的目的\(G(x,c)\)在原始音频属性\(c'\)经过生成器G可以得到\(\hat{x}\), 最后为了保证特征学习,再加上一个身份损失(id loss)。整个网络大方向上有生成器G的损失,判别器D的损失和分类器C的损失。
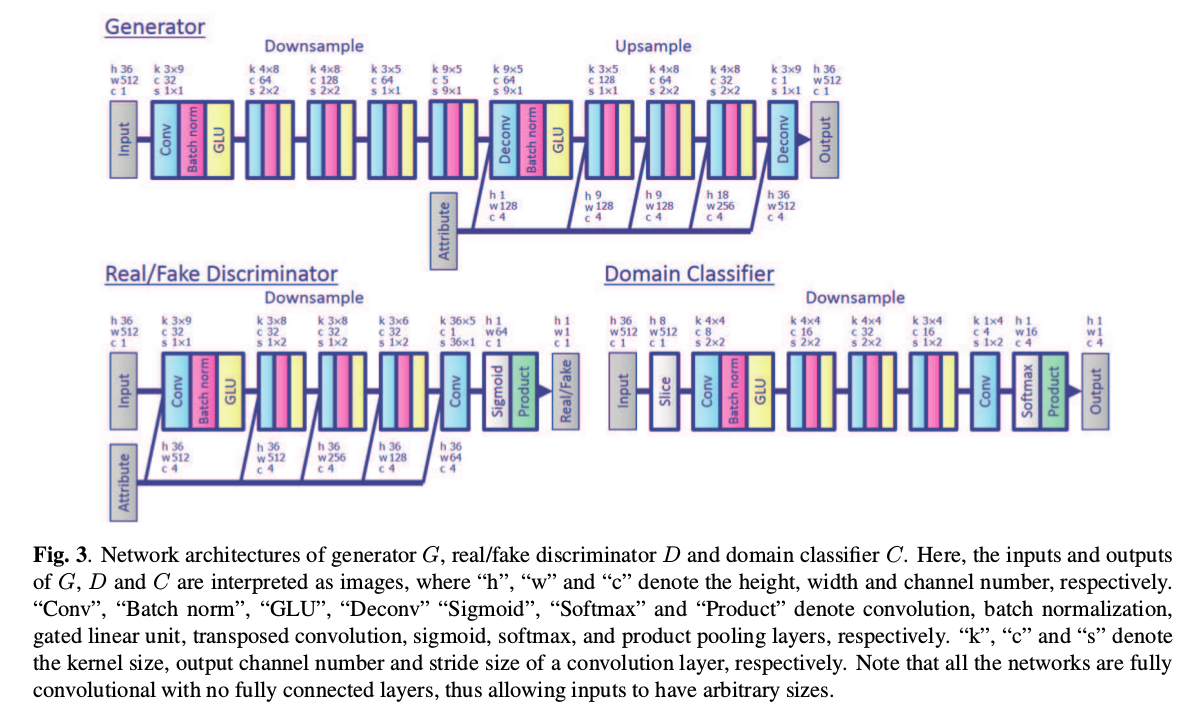
\[\begin{cases} L_{adv}^{D} = - E_{c \sim p(c),y \sim p(y\vert c)}[log D(y,c)] - E_{x \sim p(x),c \sim p(c)}[log(1 - D(G(x,c),c))]\\ L_{adv}^{G} = - E_{x \sim p(x),c \sim p(c)}[logD(G(x,c),c)]\\ L_{cls}^{C}(C) = - E_{c \sim p(c),y \sim p(y\vert c)}[log p_C(c \vert y)]\\ L_{cls}^{G}(G) = - E_{x \sim p(x),c \sim p(c)}[log p_C(c \vert G(x,c))]\\ L_{cyc}(G) = E_{c' \sim p(c),x \sim p(x \vert c'),c \sim p(c)}[\Vert G(G(x,c),c') - x \Vert_\rho]\\ L_{id}(G) = E_{c' \sim p(c),x \sim p(x \vert c')}[\Vert G(x,c) - x \Vert_\rho]\\ I_{G}(G) = L_{adv}^{G} + \lambda_{cls}L_{cls}^{G}(G) + \lambda_{cyc}L_{cyc}(G) + \lambda_{id}L_{id}(G)\\ I_D(D) = L_{adv}^{D}\\ I_C(C) = L_{cls}^{C}(C) \end{cases}\]音频之间转换的核心也是将音频转换为声谱图文中称之为声学特征序列,利用图像到图像的关系实现最终的转换。一旦生成的谱增益函数就可以通过频谱增益函数与输入语音的频谱 包络相乘并且通过声码器重新合成信号来重建出时域的语音信号。所以整个模型框架采用CNN搭建起来,但是为了保证声谱图的结构性,论文用了GateCNN为主要手段, 文中称其优于LSTM。下面为整个框架的网络结构设计:
StarGAN-VC实验
实验使用了语音转换挑战赛(VCC)2018数据集,其中包括6位女性和6位男性美国英语发音者的录音。 使用了一部分发言人进行培训和评估。实验主要选择了两位女性发言人,“VCC2SF1”和“VCC2SF2”,以及两位男性发言人,“VCC2SM1”和“VCC2SM2”。 因此,c表示为四维one-hot矢量,并且总共有十二种不同的源和目标扬声器组合。每个扬声器的音频文件被手动分成116个短句(约7分钟), 其中81和35个句子(约5和2分钟)分别作为训练和评估集提供。所有语音信号都以22050 Hz的频率进行采样。对于每个话语,使用WORLD分析仪每5毫秒提取一个频谱包络, 一个对数基频(\(log F_0\))和一个周期(AP)。然后从每个谱包络中提取36个mel-cepstral系数(MCC)。采用对数高斯归一化变换转换\(F_0\)轮廓。 不经改变直接使用非周期性。
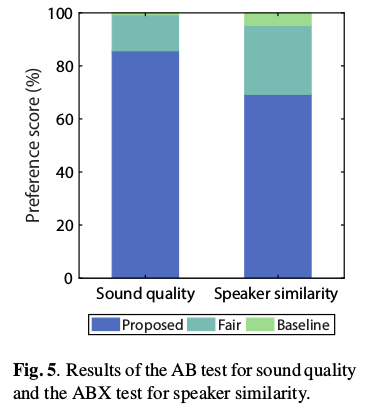
文中只和VAE-GAN做了性能的对比,实验采用AB测试以比较转换后的语音样本的声音质量和ABX测试,以比较转换后的语音样本与目标说话者的相似度, 其中“A”和“B”是使用建议和基线获得的转换后的语音样本方法和“X”是目标说话者的真实语音样本。通过这些听力测试,“A”和“B”以随机顺序呈现, 以消除刺激顺序的偏差。八位听众参加了听力测试,对于声音质量的AB测试,每个听者都被呈现{“A”,“B”}×20个话语,并且对于说话者相似性的ABX测试, 每个听众被呈现{“A”,“B”,“X”}×24个话语。然后要求每个听众为每个话语选择“A”,“B”或“公平”。结果如下图,所提出的方法在声音质量和说话者相似性方面明显优于基线方法。
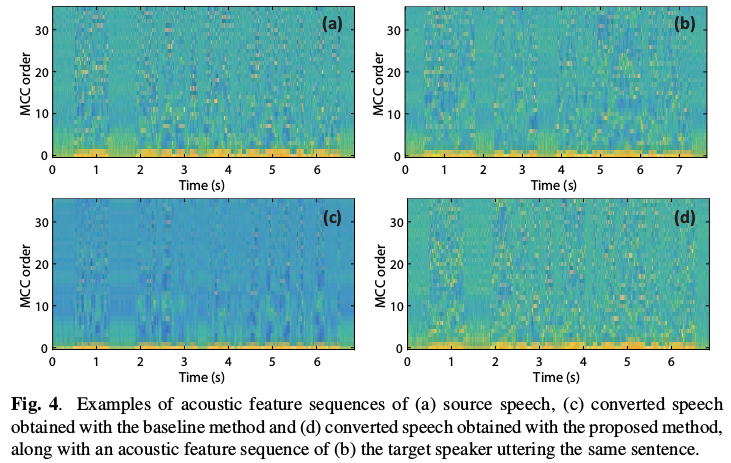
下面这个图就是源语音和重构的转换语音的声谱图(MCC)序列的示例。
论文中的大部分实验结果通过他们自己的网站展示出来,实验结果还是比较炫酷的,点击这里 体验一下StarGAN语音转换的结果。
总结
StarGAN实现了音频到音频的相互转换生成,利用了StarGAN的框架将音频装换为声谱图MCC,再通过图到图的思想达到声谱图相互转换的实现, 最后通过和语音信号的包络相乘实现时域语音信号的生成。论文对于由声谱图到时域语音信号的转换没有详细展开,这个我认为也是一个难点吧, 在后续有机会复现这篇论文的话要做进一步了解。
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







