Temporal GAN论文解读
图片到图片,文本到图片的生成,这些都属于不含时序信息的生成过程。我们之前提过GAN用于音频的生成也是基于声谱图的基础上展开的, 时序信息的生成一直是生成模型上的一个难点,今天一起来看一篇可以用于时序信息生成的GAN模型–Temporal GAN。 Temporal GAN从名字上看就是和时序有关的GAN的模型,我们一起来看一下。
论文引入
在计算机视觉领域两个大类就是图片和视频,视频的处理也是一个重点和难点因为牵扯到时序信息的处理,所以好的视频生成对于计算机视觉上是很重要的。 GAN已经在无监督图像生成上表现出了很优秀的结果,然而与图像相比,无监督的视频学习则是困难重重。在机器学习的浪潮下,视频的生成已经有了很大的进步, 但是在预测视频未来帧的问题上,在无监督学习视频生成上仍然是一个非常具有挑战性的问题。
3D卷积网络给处理视频带来了一定的帮助,所谓的3D就是在xy平面之外再加上一个时间维度t,其中x和y表示空间维度,t表示时间维度。但是单纯的加上时间维度对于视频生成上效果受限。 基于RNN的LSTM在视频的预测分类上有了一定的进展,但是RNN的思想不能直接应用于从头开始生成整个序列的任务,它们需要初始序列作为输入,这个对视频生成上有了一定的阻碍。 GAN和3D卷积结合在视频生成上是一个突破,但是视频的背景和整体上的生成效果任然很不很让人满意。
Temporal GAN是在扩展现有的GAN模型基础上提出的时间生成对抗网络(TGAN),它能够从未标记的视频数据集中学习表示并生成新视频。与使用3D反卷积层生成视频的生成器不同, TGAN包含两个生成器,分别为时间生成器和图像生成器。时间生成器首先产生一组潜在变量,每个潜在变量对应于图像生成器的潜在变量。 然后, 图像生成器将这些潜在变量转换为与变量具有相同帧数的视频。由时间和图像生成器组成的TGAN模型不仅能够有效地捕获时间序列,甚至可以通过帧插值来生成预测视频。 实验中为了保证GAN训练的稳定性使用了目前比较火的模型Wasserstein GAN(Temporal GAN论文出稿时WGAN-GP并未发表),由于WGAN对超参数敏感, 论文提出了一种从WGAN中去除敏感超参数并进一步稳定训练的新方法,文中称为Singular Value Clipping。
总结一下Temporal GAN的优势:
- 能够有效捕捉视频中时间维度的潜在空间,并且通过图像生成器生成视频,利用帧插值可以进一步做视频的生成预测
- 对WGAN对超参数敏感做改进,提出了SVC,稳定了WGAN的训练
Temporal GAN模型介绍
了解一个模型框架,首先要从模型框图开始,我们先看一下TGAN的模型框图:
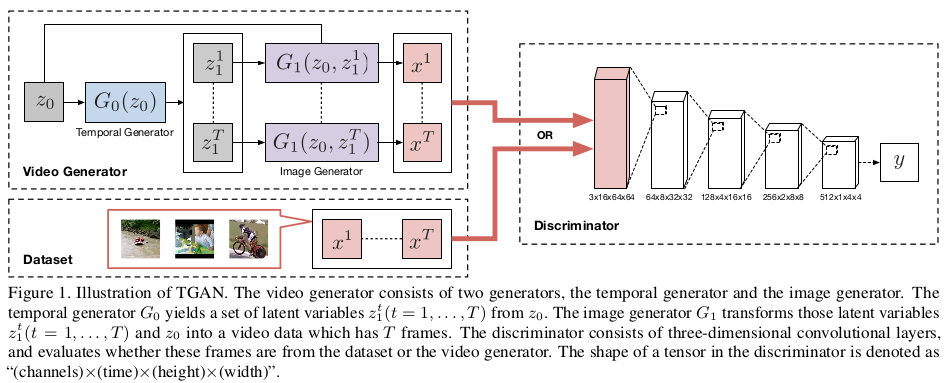
\(G_0\)是时间生成器,潜在变量\(z_0\)通过时间生成器\(G_0\)生成对应于各帧的潜在变量\([z_1^1,...,z_1^T]\),潜在变量\([z_1^1,...,z_1^T]\) 通过图像生成器\(G_1\)生成对应的帧图像\([x^1,...,x^T]\),判别器\(D\)用了判断的帧图像\([x^1,...,x^T]\)和真实数据的帧图像\([x^1,...,x^T]\) 的真假。
整个流程下来是不是感觉也蛮好理解的,但是模型中包含了很多的小细节。我们先来看看判别器,判别器的tensor的形状定义为\((channels)\times (time)\times (height)\times (width)\) 其中的卷积层采用的是3D卷积层,因为其中包含了维度。时间维度定义在第二个位置,随着不断的经过卷积层,时间维度由16帧逐渐的变为单帧, 整个判别器的目的就是为了判断真实视频和生成的视频是否为一类,是否在整体分布上一致。
对于时间生成器和图像生成器,论文中也是给了详细的参数配置:
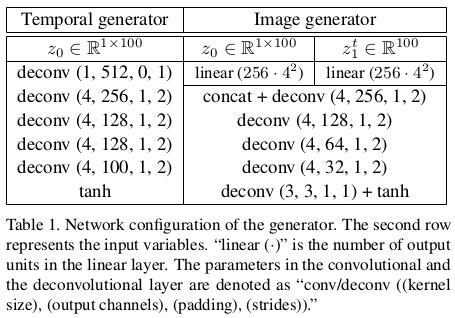
可以看出时间生成器和图像生成器中的反卷积层在时间方向上执行一维反卷积。
Temporal GAN损失函数
TGAN采用的是WGAN的损失函数思想,通过缩小Earth Mover’s distance来取出JS的分歧,从而避免训练的梯度消失。所以TGAN的损失函数是利用WGAN的思路, 损失函数如下:
\[\min_{\theta_{G_0},\theta_{G_1}} \max_{\theta_D} E_{[x^1,...,x^T]\sim p_{data}}[D([x^1,...,x^T])] - E_{z_0 \sim p_{G_0}}[D([G_1(Z_0,Z_1^1),...,G_1(z_0,z_1^T)])]\]但是我们知道WGAN中为了使判别器成为K-Lipschitz,文中提出了一种方法,就是将判别器中的所有权重限制到一个固定的范围内,表示为\(\omega\in[-c,c]\)。 虽然这个权重限制很简单,并且确保了判别符满足K-Lipschitz条件,但它也意味着无法知道c和K之间参数的关系。我们知道目标函数在K = 1的情况下是EMD的良好近似表达式, 当我们想要找到EMD的近似值时限制住权重可能带来一定的问题。
为了稳定WGAN的训练,TGAN中提出了奇点裁剪的方法(Singular Value Clipping)
Singular Value Clipping
WGAN要求判别器满足K-Lipschitz约束,并且作者采用了一种参数限幅方法,将判别器中的权重限制在\([-c,c]\)。然而,超参数c的调整和大小是很难把握的, 文中指出这个问题是由K-Lipschitz约束根据c的值广泛变化的属性引起的,以此提出了一种可以明确调整K值的替代方法。在K为1时,为了满足1-Lipschitz约束, TGAN在判别器中的所有线性层中添加约束,其满足权重参数W等于或小于1的谱范数。这意味着权重矩阵的奇异值都是一个或更少。在参数更新后执行奇异值分解(SVD), 将所有大于1的奇异值替换为1,并用它们重构参数。文中还通过将权重参数中的高阶张量解释为矩阵apply,将相同的操作应用于卷积层,将这些操作称为奇异值裁剪(SVC)。 对于Batch normalization也采用限制权重\(\gamma\)的方式,具体的Clipping文中给了表格参考:

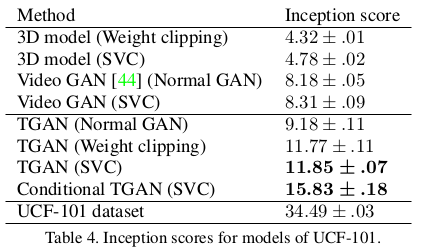
为了说明SVC的优势,实验在UCF-101数据集上做了有无SVC的测试:
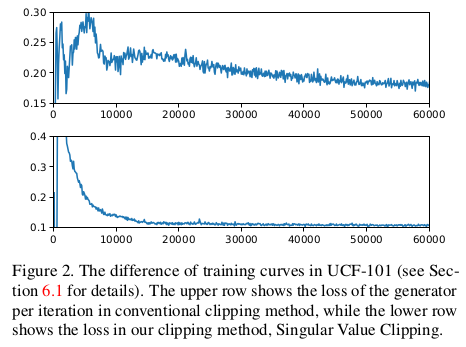
可以看出SVC的加入使得实验过程更加的稳定。对于在WGAN中使用SVC的伪代码文中也给了出来。

Temporal GAN扩展应用
TGAN单独拿出一节来说明TGAN可做到的扩展应用,包括可以通过帧插值的方法做到视频的预测生成,不过这一过程只限制在两个视频之间的过渡。 另一个扩展应用就是可以讲TGAN做成有监督生成视频,通过在训练阶段给定视频标签v可以生成对应标签的视频,文中称为Conditional TGAN简称为CTGAN。
Temporal GAN实验
TGAN在Moving MNIST,UCF-101和Golf scene三大视频数据集上做测试,我们简单介绍一下这几个数据集。
Moving MNIST包含有10000个视频,每个视频有20个帧,每个视频在64×64补丁内移动的两个数字组成。在这些视频中,两个数字线性移动, 随机选择运动矢量的方向和幅度。如果数字接近补丁中的一个边缘,它会从边缘反弹并且在保持速度的同时改变其方向。 TGAN试验中从这些视频中随机提取了16个帧, 并将它们用作训练数据集。
UCF-101是一个常用的视频数据集,由13320个属于101个不同类别的视频组成,如IceDancing和Baseball Pitch。由于数据集中视频的分辨率对于生成模型来说太大, TGAN将视频的大小调整为85×64像素,随机提取16帧,并裁剪出64像素的中心正方形。
Golf scene数据集是高尔夫场景数据集是由Vondrick等人制作的大型视频数据集,包含20268个128×128分辨率的高尔夫视频。 由于每个视频平均包含29个短片, 因此它总共包含583508个短视频片段。与UCF-101一样,文章调整了所有64×64像素的视频片段。为了满足背景始终固定的假设,他们使用SIFT和RANSAC算法稳定了所有视频。
接下来展示一些TGAN的实验结果,这中间包含了TGAN和已有的3D卷积和3D GAN,WGAN的比较。
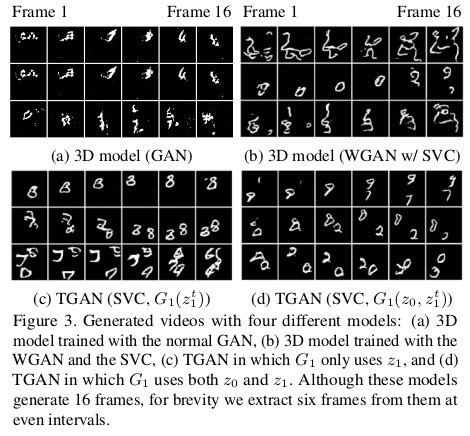

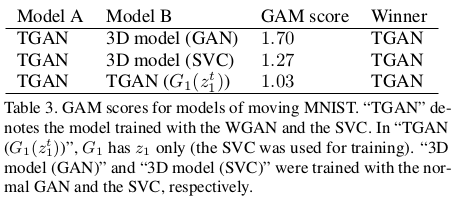
在定量上TGAN也是展示了一定的优势。
总结
TGAN在GAN的基础上提出的一种生成模型,可以学习视频的语义表示,并可以生成图像序列。通过时间生成器生成一组潜在变量,图像生成器将它们转换为图像序列。 与现有的3D GAN相比可以生成质量更好的视频,而且可以实现帧插值。为了稳定训练,TGAN提出了一种新的参数裁剪方法–奇异值裁剪(SVC),它可以稳定WGAN的训练。 但是文章在介绍时间生成器送入的\(z_0\)时仅仅说\(z_0\)是随机采样自分布\(p_{G_0}(z_0)\),没有说明分布\(p_{G_0}(z_0)\),让人有点含糊不清, 如果复现论文还要进一步深入。
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







