Look,Listen and Learn论文解读
这段时间一直忙着实验室的一些事,更新有点停滞,接下来一段时间我想把视听觉结合的这方面文章做一下梳理,感兴趣的小伙伴可以持续关注。 视觉和听觉是紧密结合的,这两者可以说是同时产生的,确定一件事情是真的发生时,多模态信息之间结合确认是很有必要的,这也是人类和大多数动物所掌握的技能。 如何让机器像人一样利用视觉和听觉的融合特征去判断一件事物和识别一些物体是《Look,Listen and Learn》 一文的目的。文章简称《Look,Listen and Learn》的方法为$L^3-Net$,接下来的描述中也保持这一简称。
论文引入
日常生活中,人类确定一件事情的发生往往通过视觉上和听觉上多模态信息的结合最终得到判断结果。视觉和听觉在忽略介质传播速度上,在时空上是同时发生的。 刮风伴随着风声和飘扬的树叶,下雨则是雨点的低落和雨声的淅淅沥沥。一个正常人在只接受一种模态的数据时往往很难判断事情的具体状况,比如我们听到 “嘭”的物体落地声,我们可以判断可能有物体掉落,但是很难判断到底是什么掉落;当我们在检修机器看到机器表面毫无破损,但是当我们听到内部异常的转动声时, 我们则有理由判断这台机器出现了异常。
从多个角度认识事物可以得到更加具体和客观的结果。然而,往往占据判断主导地位的是视觉信息,毕竟俗语有说:“眼见为实”。从事物发生的认知角度看, 确实视觉信息可以反映大部分的事物信息。从计算机发展上同样可以反映这个问题,视觉图像和视频的分类相比较音频信息更加容易,准确率也更高。 ImageNet预训练模型大大提高了视觉图像特征的提取,然而声音的分类和识别在深度学习上仍然是个不小的挑战。
结合视觉信息和听觉信息相互提高的模型中比较典型的有SoundNet 和今天我们要说的《Look,Listen and Learn》。当然,18年也出了一些其它优秀的文章,这个我们后续继续介绍。 SoundNet的目的是通过ImageNet预训练特征提取模型对视觉信息进行特征提取,利用视觉信息特征去指导听觉特征的提取和分类。$L^3-Net$ 则是将视觉信息和听觉信息提取完对应的特征后再进行融合,决策输出视听觉信息是否关联,通过不断优化,建立起视听觉特征在网络提取中的关联性, 达到更好地分类和识别效果。
在开始$L^3-Net$介绍之前,我们先来简要了解一下SoundNet的原理。我们看一下SoundNet实现的结构框架:
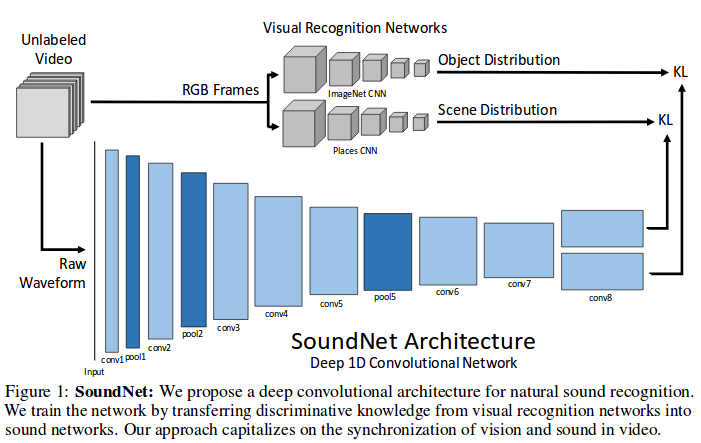
如上图所示,SoundNet分为上下两路,上面是视觉特征的提取过程,分为对象和场景两块的特征提取。相对应的,在声音的特征提取也有两个输出, 只不过不是特别强调对象和场景的分离。视觉特征的提取可以利用ImageNet预训练模型实现,听觉特征提取则是直接利用音频信号做卷积实现, 在输出提取的特征分布时,利用KL散度去优化缩小视觉和听觉上的特征差异,从而让听觉在特征提取上可以尽可能的靠近视觉特征的提取, 通过优化得到的听觉特征提取网络将可以实现更好地特征提取,从而实现单纯音频输入下较好的分类和识别任务。
$L^3-Net$较SoundNet有所改进,$L^3-Net$融合视听觉特征,在判别关联下同时优化视觉特征和听觉特征的提取网络,这里的视觉特征提取也是从零开始训练。 $L^3-Net$算是真正意义上的结合了视觉和听觉在高层语义上的联系,通过关联程度实现两者关系的建立,达到更好地特征提取。总结一下$L^3-Net$的优势:
- 设计了一个能够以完全无监督的方式学习视觉和音频语义信息的系统
- 引入了一种新颖的视听对应(AVC)学习任务
- 实验展示了使用激活可视化来定位视频帧中的音频事件的源
$L^3-Net$
$L^3-Net$设计核心思想是使用视频本身中包含的有价值但尚未开发的信息源-视觉和音频流之间的对应关系,这种关系可以有助于视觉和音频特征的提取。 视听信息的相关任务学习,是实现建立视觉和听觉关系的纽带,主体思想如下图所示:
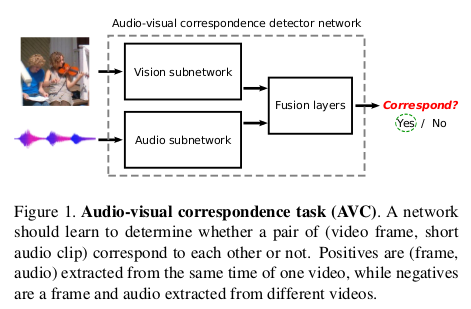
我们说的AVC就是指视觉和听觉是否是关联的?这个思想就是对视觉信息提取特征,对听觉信息提取特征,然后通过融合层将两个模态信息特征融合, 通过判断这个融合特征来实现视听关联的判断。训练阶段,相应的正例对是从同一视频同时拍摄的对,而不匹配的负例对则从不同的视频中提取。这个任务是相当困难的, 因为音频信息中往往存在大量的噪音,同时音频源不一定在视频中可见(例如,摄像机操作员说话,人员叙述视频),声源不在视野中或被遮挡音频和视觉内容可以是完全不相关的 (例如,具有添加音乐的编辑视频,非常低音量的声音,诸如风的主导声音,尽管存在其他音频事件,但是风等主导音频轨道等)。
AVC说白了就是二分类问题,瞎猜的话50%的准确性,在无标签条件加上实现上的困难,也体现了$L^3-Net$的强大。我们还是先来看看$L^3-Net$的实现结构:
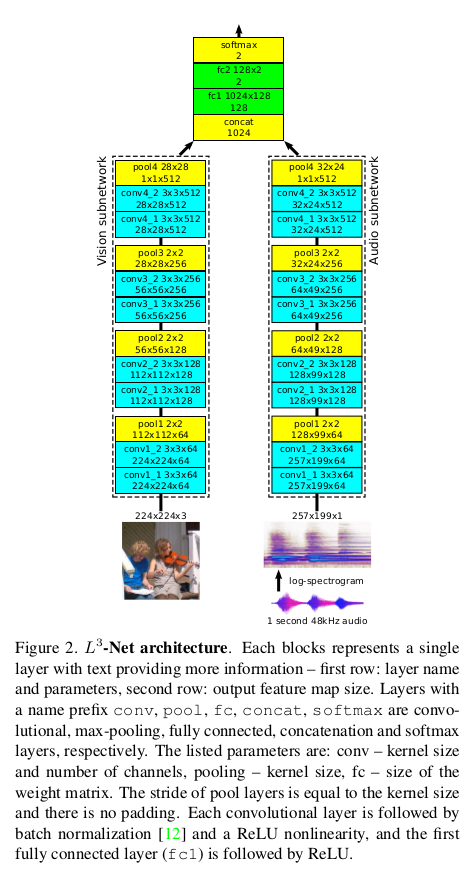
结构上有三个不同的部分:分别提取视觉和音频特征的视觉和音频子网,以及考虑到这些特征的融合网络,从而产生关于视觉和音频信号是否关联的最终决定。
视觉子网
视觉子网的输入是224×224彩色图像,整体上具有3×3卷积滤波器和2×2最大池化层,步幅为2,且无Padding。网络可以被分段为四个卷积块,使得在每个块内部, 两个卷积层具有相同数量的滤波器,而连续块具有倍增的滤波器数量:64,128,256和512。最后,在所有空间位置执行最大池化以产生单个512-D特征向量。 每个卷积层之后是批量标准化和ReLU非线性激活操作。
音频子网
音频子网的输入是1秒声音片段,先转换为对数谱图,之后将其视为灰度257×199图像。音频子网的架构与视觉架构相同,但输入像素是1-D灰度图而不是3-D彩色图, 因此与视频子网相比,conv1中滤波器尺寸小3倍。最终的音频功能也是512-D。
融合网络
这两个512-D视觉和音频功能被连接成一个1024-D矢量,该矢量通过融合网络产生一个双向分类输出,即视觉和音频是否相应。它由两个全连接层组成, 它们之间加上ReLU,中间特征尺寸为128-D。
对于正负样例的选择,通过在视频下随机采样实现,对于负例则是在不同视频下随机采样视频帧和音频,正例则是在采样到的视频帧下同时采样重叠对应的音轨。 至于对数谱的变换,想必涉及到语音处理的都能理解,就是将1秒音频重新采样到48kHz,计算频谱图,窗口长度为0.01秒。整个网络的训练都是从头开始, 包括视觉特征的提取,这个也对应了视听觉特征关联建立的过程。这个训练过程和成本也是相当巨大的,不过对于DeepMind这样的公司来说则是小问题了。
文章的主体部分已经介绍完了,整体上看还是很好理解的。总结一下就是通过分别提取视听觉特征,进行融合后判断输出是否关联,通过关联的正确与否优化整个网络。 在优化的阶段,无形中建立了视觉和听觉的高层语义的联系,比如一段视频中只要出现狗就有狗叫,那么狗和狗叫就是一对。这个过程完全是无监督过程, 文章的大篇幅放在了实验上,算是通过实验加强理论的说明,我们通过实验进一步理解文章。
分析和实验
实验开展建立在两个数据上,一个是无标签的Flickr-SoundNet,这是来自Flickr的完全无约束视频的大型未标记数据集,除了视频本身之外没有使用任何标签或任何类型的附加信息。 它包含超过200万个视频,但出于实际原因,实验使用500k视频的随机子集(400k训练,50k验证和50k测试),并且仅使用每个视频的前10秒。另一个是带标签的Ki- netics数据集的一个子集, 其中包含使用Mechanical Turk手动注释人类操作的YouTube视频,并在操作周围裁剪为10秒。该子集包含19k 10秒的视频剪辑(15k训练,1.9k验证,1.9k测试), 通过过滤34个人类动作类的动力学数据集形成,这些动作类被选择为可视地和听觉地表现出来,例如游戏-使用各种乐器(吉他,小提琴,木琴等),使用工具(割草,铲雪等), 以及进行各种动作(踢踏舞,打保龄球,大笑,唱歌,吹鼻子等)。
AVC的输出是二分类,在无标签信息下,实验下AVC的分类准确率如下:
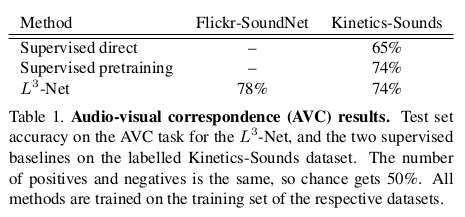
实验可以看出,$L^3-Net$在无监督下可以媲美有监督训练的AVC判别准确性完全可以媲美有监督训练结果。
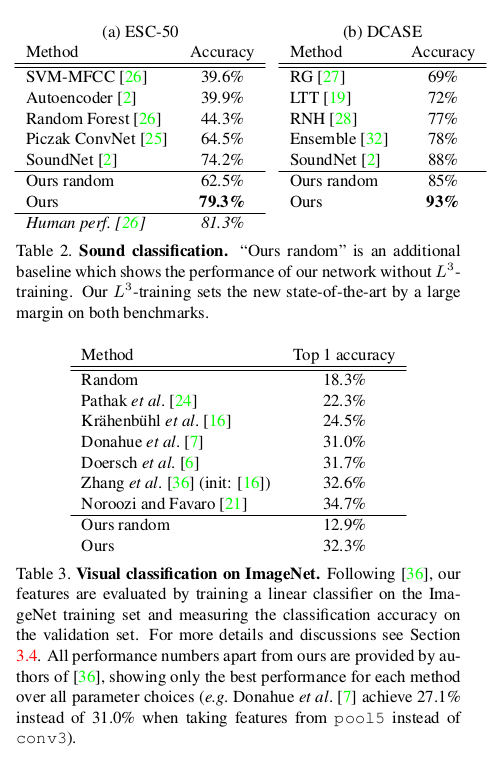
通过$L^3-Net$的训练,可以实现视觉特征提取和音频特征提取网络的提升,文章分别在声音特征提取上进行了音频分类实验,在视觉特征提取上进行了 ImageNet分类实验,从实验结果上看取得了很好的效果:
在定性分析上,文章在Kinetics-Sounds和Flickr-SoundNet数据集的测试集上可视化结果,在pool4中选择一个特定的“单元”激活显示,视觉子网下无需任何明确的监督, 识别语义实体,如吉他,手风琴,键盘,单簧管,保龄球馆,草坪或割草机等,结果如下所示:

下图显示了Kinetics-Sounds数据集中哪些特定音频单元敏感。对于可视化目的,文章不显示声音形式,而是显示与声音对应的视频帧。

下图显示了频谱图及其语义热图,说明我们的$L^3-Net$学会检测音频事件。

文章在实验上做了特别充分的说明,验证了视听觉融合后在判别优化下同时提升了视觉和听觉的特征提取,并且在分类和识别任务上展现了一定的优势。
总结
文章展示了AVC任务培训的网络在声音分类方面取得了卓越的成果,在视觉特征提取上也有所提高,这其中的原因可能是视觉网络的额外自由度允许学习更好地利用视频中各种视觉信息提供的机会 (而不是仅限于通过预训练网络的眼睛看到),文章认为视觉和听觉两个流的并发性存在附加信息,因为并发性比相关性强,因为事件需要同步(当然,如果事件是并发的,那么它们将相关,但反之亦然)。 当然,视听觉的融合和相互提高并不限于这篇文章,近段时间也是出了一些好文,我们陆续做解读了解。
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







