Deep Audio-Visual Speech Enhancement论文解读
当几个人异口同声的说话时,往往会造成大家都在说但是谁说的话都听不清的问题。这个时候在这样的音视频分离出一个人的声音就可以很好的解决这个 问题。The Conversation:Deep Audio-Visual Speech Enhancement正是在这种情况下提出的, 通过深度神经网络根据视频中人物的唇部动作指导提取出与之对应的音频的幅度和相位,从而提取出这个人的说话音频。实验上可以最多支持5个人分离出 独自的音频。
论文引入
我们看新闻节目的时候,在一些会场连线或者各个新闻台之间直播连线过程中,为了保持自己的观点上的优势,往往大家都是异口同声的阐述着个人的想法。 在这种时间紧迫的节目安排上,几乎没有人愿意让出时间给对方发言,但是大家一起说会造成观众们听不到任何一个人的发言。如果可以在连线结束后节目再 安排复播把每个人的发言单独提取出来重放就可以很好的解决这件事。如果人力去完成分离工作可能会造成时间上的浪费,如果让机器通过每位发言者的唇部 动作来分离出音频,这样就好大大节省时间,甚至做到在线处理及时发布。
The Conversation:Deep Audio-Visual Speech Enhancement一文通过深度神经网络实现在多位发言者中分离出其中一位发言者的音频,为了进一步 展示我们看一下实验实现的视频结果(视频仅有YouTube资源,国内打开下面视频需要翻墙)。
这个模型的可以有很多的应用,其中之一是自动语音识别(ASR),虽然机器可以在无噪声环境中相对良好地识别语音,但在嘈杂环境中识别性能会显着下降。 如果可以将音频分离开那么识别的话也会轻松起来,还可以用于YouTube视频的自动字幕。
从音频中分离出多讲话者同声说话的方法已经有了一些,这些中的大多数基于仅使用音频的方法,结合视觉上将音频分离开的几乎没有。在基于音频的方法中 通过对幅度和相位的过滤提取是常用的方法。在深度神经网络下也产生了一些方法,通过静态帧图像生成语音,通过混合去增强语音。但是The Conversation:Deep Audio-Visual Speech Enhancement 也做到了改进,主要的不同于已有的方法之处:
- 不将频谱图视为图像,而是将频率区域视为信道的时间信号,这样能够构建一个具有大量参数的更深层网络,这些参数可以快速训练
- 生成一个用于过滤的软掩模,而不是直接预测幅度
- 设计了相位增强子网络
- 在视频演示了很好的实验效果
模型框架
我们先从大方向上看一下模型实现的框架结构:
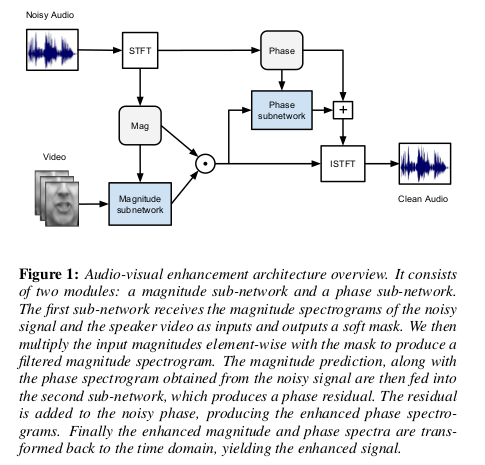
模型实现的基础就是将视觉上的唇部动作和一段混合的音频在模型作用下,通过不同人物的唇部动作提取出对应人物的音频的幅度和相位信息最后合成仅有 该人声音的音频。首先对原始音频通过短时傅里叶变化(STFT)提取得到音频的幅度(Mag)和相位(Phase)信息。对于音频幅度和视觉唇部图像经过幅度 子网络作用得到一个融合后具有视觉信息的预测幅度,将预测幅度和相位再经过相位子网络得到新的幅度相位最后经过逆短时傅里叶变换从而还原出仅含视觉唇部 对应的音频。
这个模型整体上理解起来是很清晰的,接下来我们展开看一下具体的实现细节,我们看一下详细的模型结构:
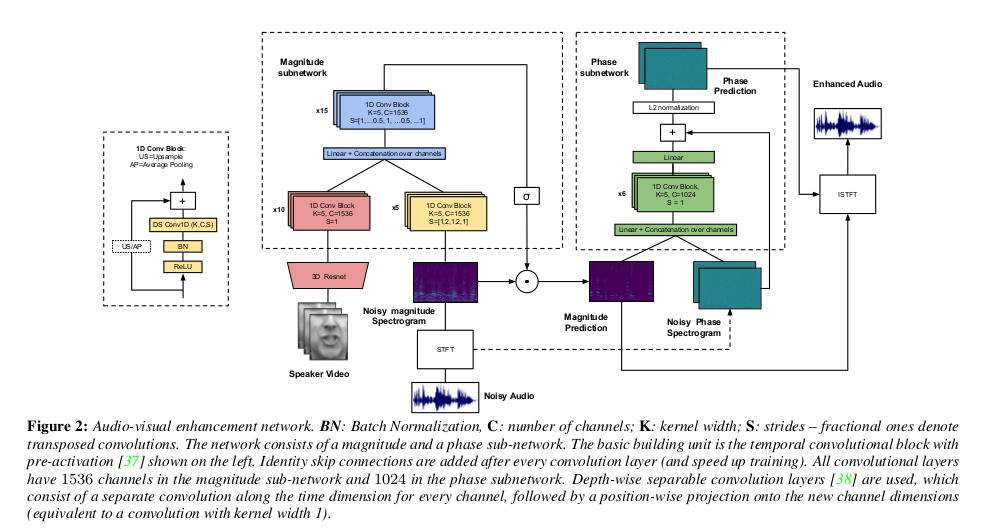
首先对视觉特征的提取采用一个3D Resnet来实现,对于每一个视频帧最后提取到的特征表示为512维的特征向量$f_0^v$,其中下标0指的是视听网络中的层编号。 对于音频通过短时傅里叶变化从原始音频波形中提取声学表示,其产生幅度和相位谱图。
幅度子网
对于幅度子网,首先视觉特征$f_0^v$由10个卷积块的残差网络处理,其中每一次卷积都包含一个内核宽度为5且步长为1的临时卷积,也就是上图中的最左侧表示。 对于音频信息,采用5次卷积,沿时间维度执行卷积,其中原始音频输入频谱图$M_n$的频率被视为信道。两个卷积中间使用步幅2执行卷积,对时间维度进行整体下采样4, 以便将其降低到视频流分辨率。最后对视觉和音频做合成$f_0^{av} = [f_{10}^v;f_5^a]$。融合后的张量再通过15次卷积,由于希望输出掩模具有与输入 幅度谱图相同的时间分辨率,因此在15次卷积中包括两个转置的卷积,每个卷积对时间维度上采样2倍,导致总共4倍。融合输出通过位置卷积投影到原始幅度 谱图尺寸并通过信号激活,以输出值介于0和1之间的掩模。得到的张量乘以噪声幅度谱图元素方面产生增强的幅度谱:
\[\hat{M} = \delta (W_m^T f_{15}^{av}) \odot M_n\]相位子网
相位子网络以原始音频相位和幅度预测为条件。这两个输入通过线性投影和连接融合在一起,然后由一堆6个时间卷积块处理,每个块有1024个通道。 通过将结果投影到相位谱的尺寸上来形成相位残差,并将其添加到原始音频相位。最终通过L2范数预测相位结果。
\[\phi_6 = \underbrace{ConvBlock(...ConvBlock([W_{m \phi }^T \hat{M};W_{n \phi }^T \Phi_n]))}_{\times 6}\] \[\hat{\Phi} = \frac{W_{\phi}^T \phi_6 + \Phi_n}{\Vert \phi^T \phi_6 + \Phi_n) \Vert_2}\]通过最小化预测幅度谱图和真实分离幅度谱图之间的$L_1$损失来训练幅度子网。通过最大化相位预测和真实相位之间的共同相似性来训练相子网, 并通过真实量值进行缩放。总体优化目标是:
\[\mathcal L = \Vert \hat{M} - M^* \Vert - \lambda \frac{1}{TF} \sum_{t,f} M_{t,f}^* <\hat{\Phi_{t,f}},\Phi_{t,f}^*>\]整个框架和实现和大方向上的是一样的,整个网络的训练和微调还是很有难度的。
实验
实验在两个数据集上进行训练:第一个是BBC-牛津唇读法句2(LRS2)数据集,其中包含来自BBC程序的数千个句子,如Doctors和EastEnders;第二个是VoxCeleb2, 它包含超过6000个不同发言者所说的超过一百万个话语。
实验通过信号干扰比(SIR)测量不需要的信号被抑制的程度,信号与伪影比(SAR)解释了增强过程引入的人工制品以及信号与失真比(SDR)是一个整体质量措施, 考虑到这两点,还报告了PESQ的结果,它测量了整体感知质量和STOI,这与信号的可懂度相关。实验结果如下,可以看到模型在定量有一定的优势:
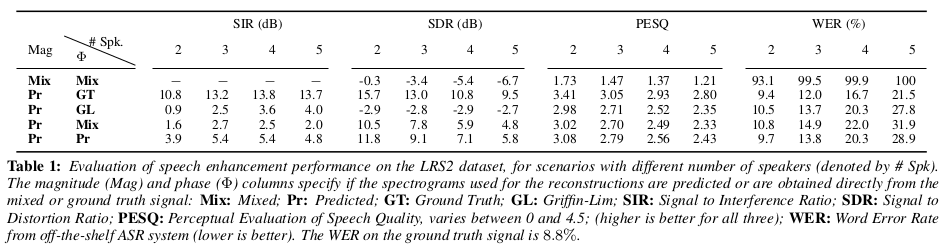
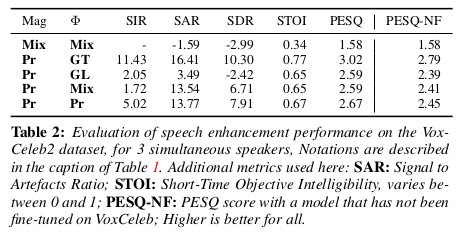
总结
文章提出了一种使用来自目标说话者嘴唇的视觉信息将目标说话者的语音信号与背景噪声和其他说话者分开的方法。深度网络通过预测目标信号的相位和幅度 来产生逼真的语音段;文章还证明了网络能够从无限制的“野外”环境中记录的非常嘈杂的音频片段中生成可理解的语音。
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







