DTN论文解读
Unsupervised Cross-domain Image Generation也称为Domain Transfer Network简称为DTN, 作为较早利用GAN思想实现跨模态图像的生成,对于后期的工作有很好的指导和借鉴。文章巧妙地将模态间的的特征做了处理,使得源域提取的特征在模型 作用下趋于目标域的特征,从而实现模态上的转换。
论文引入
人类擅长于在不同域之间进行类比,将元素从一个域转移到另一个域,以及使用这些功能来混合来自多个源域的概念的任务。但是让机器通过类比的思想学习到 域之间的转换是困难的。截止到现在已经有很多文章实现了跨模态间的相互生成,但是在17年初连CycleGAN 都还没发表的时候,DTN已经可以说得上是很具有开创性的了。
在图像生成上GAN可以说是很有优势,虽然本身存在问题但是逼真的实验结果让GAN更加的受人关注,很多实现跨模态间生成上都是实验GAN的思想实现的。 模态间的生成意义很大,我们在之前的文章也有讨论,这里不再赘述。
跨模态间的生成的一个很大的问题就是如何统一源域与目标域之间的特征关系,UNIT采用的是将两个域的特征做融合再用来生成, CycleGAN采用的是两个生成器和两个判别器已经循环重构误差来优化,以及最近的Cross Domain Image Generation 采用的是域之间的隐空间之间的相互映射,这些方法实际上都是为了实现源域到目标域的特征上的转换。实现了源域特征到目标域的特征其实也就已经实现了 跨模态的生成。
DTN采用重构源域与目标域的特征空间误差来缩小域之间的特征差异,最后实现较好的统一从而生成上利用特征空间来生成目标域的图像,我们后面会详细说明。 总结一下DTN一文的优势:
- 较早的提出用GAN实现跨模态的生成
- 特征误差的巧妙设计
- 利用目标域的重构加强判别器的能力,从而实现更好的生成
- 实现了无监督下的跨模态生成
DTN模型
DTN模型的结构框图是很清晰的,我们一起来看一下:
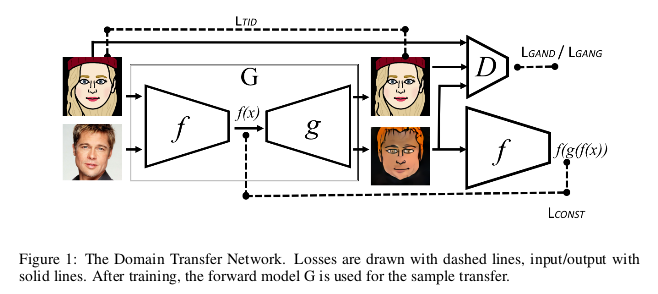
文章的实现基础是在人物真实面部到卡通表情包的转换,也就是把人物真实面部图像作为源域$S$,把人物卡通表情作为目标域$T$。最终的目的是为了实现 源域$S$通过模型生成目标域$T$图像。接下的分析主要来自DTN的源码可能与文章的描述有 稍许的不同,但是整体思想是一样的。
源域训练
在模型训练上分为两部分来实现,一部分是源域图像优化模型,另一部分是目标域图像优化模型。在实际训练过程中这两者也是分开训练的,我们也分开分析。 我们先看源域图像优化模型,对应着就是模型框图的最下面的一路,输入源域的图像$x$经过特征提取器$f$得到特征空间$f(x)$,由特征空间$f(x)$经过 生成器生成出目标域的图像$g(f(x))$。此时判别器D的目的是为了识别出$g(f(x))$为假,二对于生成网络G而言则是希望欺骗过判别器D,此时在$S$下的 判别器与生成器对应的损失函数为:
\[\mathcal L_D = - \mathbb E_{x \in s}[log(1 - D(g(f(x))))]\] \[\mathcal L_G = - \mathbb E_{x \in s}[log D(g(f(x)))]\]此时判别器的目的是判别生成的图像为假,生成器的目的是让判别器判别错误,实现了对抗。接下来的重点来了,为了实现源域特征与目标域特征的靠近, 这部分又做了一个特征误差的优化。有源域的图像经过生成网络得到的目标域图像$g(f(x))$再通过特征提取器$f$得到特征$f(g(f(x)))$,通过缩小特征 $f(x)$与$f(g(f(x)))$的误差来实现源域与目标域特征间的拉拢。最理想的目的是实现源域的图像经过特征提取器后直接得到目标域的特征空间, 当然这是理想条件,所以这个特征误差在DTN模型上是十分重要的,特征误差损失为:
\[\mathcal L_{const} = \sum_{x \in s} d(f(x), f(g(f(x))))\]这里的$d$是MSE损失,下面说到的$d_2$也是一样的。
目标域训练
源域训练与目标域训练在源码下是交替进行的,对于目标域的训练更像是一个标准的GAN实现过程。目标域图像$x$经过特征提取器得到特征空间$f(x)$, 经过生成器$g$得到目标域的重构图像$g(f(x))$。判别器此时以真实目标域图像$x$为真,重构图像$g(f(x))$为假做判别。生成网络的目的是为了让判别器 认为重构的图像是真实的,此时对应的损失函数为:
\[\mathcal L_D = - \mathbb E_{x \in t}[log D(x)] - \mathbb E_{x \in t}[log(1 - D(g(f(x))))]\] \[\mathcal L_G = - \mathbb E_{x \in t}[log D(g(f(x)))]\]为了进一步优化生成网络,在目标域训练下还做了一个重构误差的损失优化:
\[\mathcal L_{TID} = \sum_{x \in t} d_2(x, G(x))\]分析一下,如果判别器对于$T$域重构的图像都认为是假的,那么由源域生成的图像则会更容易判别为假,这样迫使生成网络不断提高生成能力,生成质量更高的图像。 至此,整个网络已经实现了整体的优化,为了是生成的图像进一步平滑,文章加上了各向异性的总变差损失,其中$z=[z_{ij}]=G(x)$:
\[\mathcal L_{TV}(z) = \sum_{i,j}((z_{i,j+1} - z_{ij})^2 + (z_{i+1,j} - z_{ij})^2)^{\frac{B}{2}}\]这里的$B$常取1。
上述的分析和原文中将D视为三元分类器的意义是相同的,不过我认为上述的描述可以帮助读者更好地理解文章,如果上来就说三元分类器估计很多人是不明白的。 所以,这里与原文上有一些不同,但是描述的思想是从源码中剥离,尊重原文的。
到这一步,模型的整体已经分析结束了,整个模型更像是AE和GAN的结合,创新之处在于特征损失的设计和实现,从而拉近了源域与目标域之间的的特征差别, 在跨域生成上实现了平稳过渡。
DTN实验
我们首先看一下SVHN到MNIST,以及人脸到卡通表情的最终生成结果:

可以看出在保留原域的基本特征信息上实现了目标域图像的生成,整体效果是不错的。为了说明模型的每一部分的作用,实验在SVHN到MNIST上做了比较:
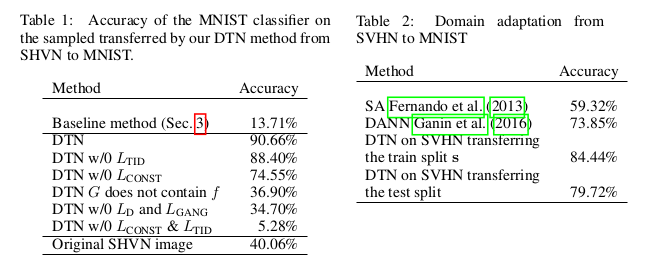
从生成结果的准确性上,原始DTN最高,特征损失的缺失对于模型准确率上影响很大,在缺失某一个域下训练的时候,结果怎样呢?文中给出了实验:

可以看出目标域下的训练是十分重要的。最后就是人脸到卡通的转换:

DTN存在的一大问题就是生成上的不对称,即有人脸到卡通的域转换可以实现,但是由卡通到人脸则是一个很大的挑战。一个说明是人脸的信息量大,特征空间较为复杂, 仅仅通过特征误差很难使得卡通特征很好的拟合人脸,所以DTN的局限性也正是体现在这里:

总结
DTN巧妙设计特征误差实现了模态域间的转换,当目标域的信息量小于源域的时候,通过模型的训练可以很好地实现源域到目标域的生成。但是DTN的一大缺点就是 当目标域的信息量大于源域的时候,此时,模型在实现模态间转换上是不对称的,这也是需要改进的一个地方。
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







