Fast R-CNN简析(大部分引用)
Fast R-CNN是rbgirshick在R-CNN基础上提出的改进,提出了一些创新式的做法,不仅提升了训练和测试时的速度, 而且提升了精度。作为目标检测的经典之作,今天我们一起来看看。本博文参考了这篇和 这篇
在开始论文解读前,我们看看Fast R-CNN的效果

SPPnet是Kaiming He提出的一种结构,论文链接在这里
可以看出,FRCN不仅在精度上得到了提升,更重要的是,它在测试时比RCNN快了213倍,这让实时处理成为可能(当然faster RCNN基本已经达到了实时的要求)。
一、基础介绍
detection有两方面的挑战。第一,大量的候选区域需要被处理;第二,候选区域只能提供大致的定位,所以必须被细调来达到精确的定位。这两个挑战让众多解决方案只能牺牲速度和精度。
回顾一下R-CNN
a. 在图像中确定约1000-2000个候选框
b. 对于每个候选框内图像块,使用深度网络提取特征
c. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
d. 对于属于某一特征的候选框,用回归器进一步调整其位置
更多细节可以参看这篇博客。
Fast RCNN方法解决了RCNN方法三个问题:
问题一:测试时速度慢
RCNN一张图像内候选框之间大量重叠,提取特征操作冗余。Fast RCNN将整张图像归一化后直接送入深度网络。在邻接时,才加入候选框信息,在末尾的少数几层处理每个候选框。
问题二:训练时速度慢
原因同上。在训练时,Fast RCNN先将一张图像送入网络,紧接着送入从这幅图像上提取出的候选区域。这些候选区域的前几层特征不需要再重复计算。
问题三:训练所需空间大
RCNN中独立的分类器和回归器需要大量特征作为训练样本。Fast RCNN把类别判断和位置精调统一用深度网络实现,不再需要额外存储。
总的来说Fast RCNN有以下的提高:
1.更高的检测质量(mAP)相比于RCNN和SPPnet
2.使用一个多任务的loss,训练时单级的
3.训练可以更新所有网络层
4.不需要为特征缓存提供磁盘存储
二、Fast R-CNN 框架
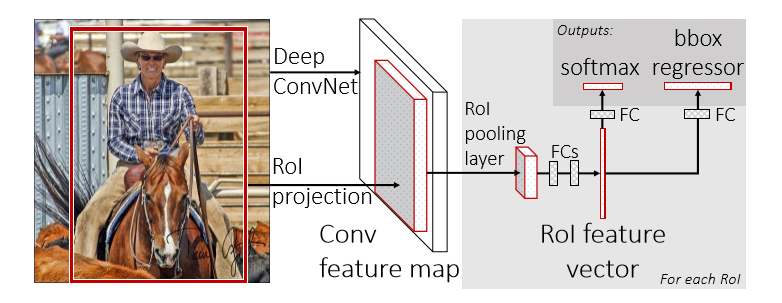
这张图就是FRCN的架构图。一个FRCN网络使用整张图片和候选区域集做为输入,网络首先处理整张图片得到一个卷积特征图,然后, 为每个候选区域的ROI(region of interest)池化层从特征图中提取一个固定长度的特征向量,每个特征向量被送入全连接层,最终分成两个兄弟输出层: 一个产生softmax概率评估K个物体类别外加一个”背景”类,另一个为每一个物体类输出4个实数值,每个4个值的集合都是K个类别的位置细调的结果。
这里的ROI池化层是SPP(spatial pyramid pooling)层的特殊情况。
初始化FRCN网络
从上图中我们可以看出一个预训练的网络初始化一个FRCN网络,需要三个转换:
1.最后一层最大池化层被一个ROI层替代来和网络的第一个全连接层相容
2.最后一个全连接层和softmax层被前文所述的兄弟层替代
3.网络需要被修改成采用两个输入:一个图像列表和这些图像中的ROIs列表
微调检测
使用反向传播方法来训练所有网络层的参数是FRCN的一个重要能力。首先,文中阐释了为什么SPPnet不能更新SPP层以下的层的参数的原因。 根本原因是因为RCNN和SPPnet训练时的样本来自不同的图像,导致SPP层的反向传播非常低效。这种低效性来源于每个ROI基本都有一个非常大的感受野,经常就是整张图片。
文中提出了一个有效的方法。在FRCN训练过程中,SGD mini-batches是分层抽样的,首先采样N张图片,然后采用对每一张图片采样R/N个ROIs。 关键是在前向和反向计算时,来自同一张图片的ROIs共享计算和内存,这大大减少了一个mini-batch的计算。例如,当N=2,R=128时, 这种方法比从128个不同的图像中提取一个ROI的方法要快64倍。这种策略的一个缺点在于其可能会减慢训练的收敛因为来自同一张图片的ROIs是相关的。 但是在实践中这种担忧并没有出现,当N=2,R=128时,比RCNN使用更少的SGD迭代得到了更好的结果。
Multi-task loss
相比于训练softmax分类器,SVM,regrossor三个阶段,fast R-CNN把这些过程都一起优化。
多任务损失函数:
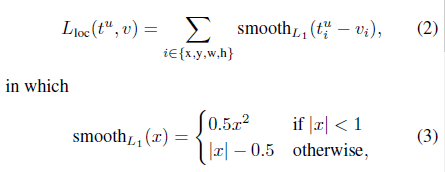
L1 loss对异常值更不敏感相比于L2 loss;
超参数lambda控制两个loss的平衡,在使用中取1;
多尺度训练的方法可以近似大小不变;
三、Fast R-CNN detection
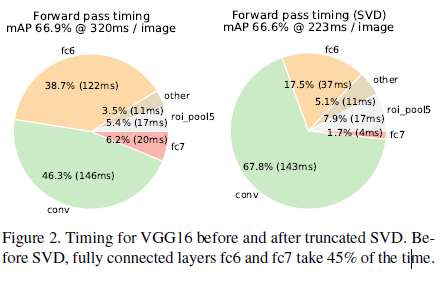
对于整个图片的分类,相比于卷积层,FC层画的时间很少,但是在检测中,由于ROI的数量很大,有一半的时间画在了FC层,通过简单的奇异值分解对FC层进行加速;
假设某层的参数可以分解为:

U大小为uxt,V为vxt,中间为txt,这样的话参数个数可以从uxv降为t(u+v),如果t远远小于min(u,v)就更显而易见了;把SVD用于两层FC层,可以很好的加速,并且mAP只下降了0.3%;

Main results:

fine-tune conv3_1以上的卷积层;
更多的训练数据可以提升mAP;
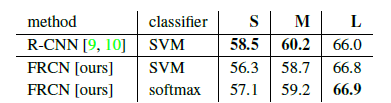
softmax和SVM的比较:
我创建了一个机器学习方面的交流群,目的是交流机器学习的前景应用、日常code过程中的收获和学习生活中的困难。QQ群号:701451028
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







