高分辨率自然场景时移变换
同一个场景在不同时间段存在着一定的变化,这主要取决于光照对图像的成像的影响,如何通过一个时间段的场景图像在无域标签的情况下合成出不同时间段下的高分辨率场景图像是本文要介绍的CVPR 2020 oral中High-Resolution Daytime Translation Without Domain Labels(HiDT)所做的工作。
论文引入
大部分使用Mac系统的用户默认动态壁纸是位于洛杉矶卡特琳娜岛的一天场景变化,对应着清晨、日出、正午、傍晚、入夜、凌晨的时移变化,固定机位间隔拍摄可以作为取景,然而这将花费一天时间。如何利用一张高分辨率图像达到时移自然场景的合成,是HiDT要实现的任务,文章称之为Daytime Translation,图1展示了任务效果。

图1.HiDT在自然场景时移变换的结果图
自然场景的时移变换其实就是图像翻译的一类应用,早期的图像翻译在训练以及推理时都需要域标签,而MUNIT[1]和FUNIT[2]提出了目标域的几幅图像作为翻译指导,同时期的StarGAN v2[3]更是提出了在一个生成器中根据不同的style code实现多域转换,这些或多或少都要有域标签的参与。在时移场景变换下,域对应于一天中的不同时间和不同的照明,这个域标签定义起来是繁琐的,如何在无域标签的情况下实现高分辨率时移场景的合成是一个大的挑战。
然而大部分图像翻译任务在处理的图像上的尺寸多为中等尺寸,即$256\times 256$居多,如何实现高分辨率下($1024 \times 1024$)的图像翻译仍是一个值得研究的问题,同时自然场景时移变换更是面临着不能完全依赖图像色彩空间的全局仿射变换,不能依赖时间戳和高分辨率下如何消去伪影等问题。HiDT通过对高分辨率源域图像进行分步转换,最后通过融合实现高分辨率图像合成,在处理图像伪影和细节上,文章将跳跃连接(Skip connections)和AdaIN进行结合,总结一下HiDT相比较已有的图像翻译方法的优势。
- 在仅有语义分割图的弱标签下实现了多域图像转换
- 在图像细节转换上通过跳跃连接和AdaIN结合实现高质量转换
- 通过拆分转换和融合达到高分辨图像转换
网络架构和优化
HiDT的架构是建立在跳跃连接和AdaIN结合的基础上,采用UNet和AdaIN架构起网络的编码和解码器的主体,这个结构如图2所示。
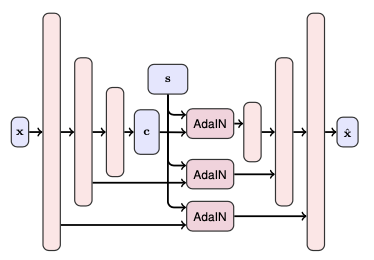
图2.HiDT编码和解码器网络
由架构图可以看到对于输入$x$,通过下采样进行编码得到对应的图像内容编码$c$,解码端(生成器)将内容编码$x$,风格编码$s$与不同下采样进行跳跃连接再配合AdaIN嵌入进行上采样生成对应的目标域图像。决定转换后图像风格(可以理解为自然场景的不同时刻和光照)的是由风格编码$s$决定。而风格编码$s$在训练阶段是由目标域图像编码得到,在测试阶段则是通过在先验分布下采样得到,这部分我们待会再详细讨论。
HiDT的整体架构倒是很直观,详细的网络结构只能通过代码去进一步查看,作者放出了项目地址,但是代码还在更新中。不过值得说的是HiDT对于模型的优化过程介绍的很好,这也算是图像翻译中比较详细和先进的模型优化方式。
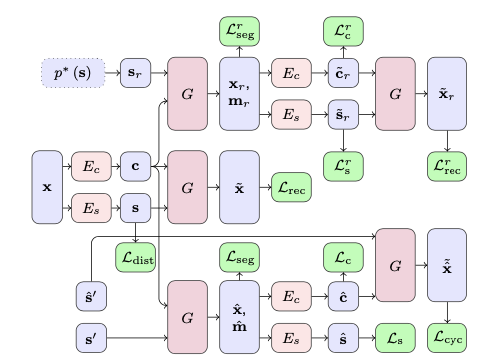
图3.HiDT网络优化过程
在介绍之前,先来梳理一下图3中的符号,$x$表示源域输入图像,$E_c$表示内容编码器相对应的$c$为内容编码,$E_s$表示风格编码器相对应的$s$为风格编码,$G$为生成器,$s^\prime$为目标域风格编码,$p^*(s)$为风格编码的先验分布,$s_r$为在风格编码的先验分布下随机采样的风格编码。生成器$G$不光光输出的是转换后的图像,同时也输出相对应的风格掩码图$m$。从上到下分析,随机风格采样$s_r$与内容编码$c$生成$G(c,s_r)=x_r,m_r$,此时$x_r$的风格取决于随机风格$s_r$,掩码$m_r$则是受内容$c$的影响,对$x_r$继续进行内容和风格编码得到\(\tilde{c}_r,\tilde{s}_r\),将\(\tilde{c}_r,\tilde{s}_r\)馈送到生成器$G$得到重构的\(\tilde{x}_r\),为什么说是重构呢?因为此时输入的风格是$x_r$自身的风格编码;中间一路就是对$x$进行编码后再重构得到$\tilde{x}$;最下面一路则是先根据源域内容编码$c$与目标域风格编码$s^\prime$生成得到目标域图像和分割掩码$\hat{x},\hat{m}$,再由$\hat{x}$编码得到的内容编码$\hat{c}$与风格编码$\hat{s}^\prime$得到最原始源域图像$\tilde{\hat{x}}$,由于$\tilde{\hat{x}}$给出的损失为\(\mathcal L_{cyc}\),这里推测风格编码$\hat{s}^\prime$就是源域图像的风格表示,此处在原文中并没有做详细交代,等作者公布代码可以做进一步验证。
上述分析,总结起来就是模型在优化阶段由三种模式,一是随机风格的转换和重构,二是原始图像的重构,三是目标域图像转换和循环一致的转换。
最后就是如何对模型进行损失优化,正由图3中所展示的,重构损失$\mathcal L_{rec}$,风格掩码损失$\mathcal L_{seg}$,内容编码损失$\mathcal L_{c}$,风格编码损失$\mathcal L_s$,风格编码下趋紧先验分布的损失$\mathcal L_{dist}$以及循环一致损失$\mathcal L_{cyc}$,由此衍生的$\mathcal L_{seg}^r , \mathcal L_c^r, \mathcal L_s^r, \mathcal L_{rec}^r$也是一样的含义,图3中省略了对抗损失$\mathcal L_{adv}, \mathcal L_{adv}^r$,对抗损失主要是对转换后的$\hat x$和$x_r$进行优化。
重构损失为$L_1$损失,即$\mathcal L_{rec}=\Vert \tilde x - x \Vert_1$,类似的有$\mathcal L_{rec}^r = \Vert \tilde x_r - x_r \Vert_1$,循环一致损失也是采用$L_1$损失$\mathcal L_{cyc} = \Vert \tilde{\hat{x}} - x \Vert_1$。对于分割掩码损失则是采取交叉熵损失$CE(m,\hat m)=-\sum_{i,j}m_{i,j} \log \hat m_{i,j}$,则有$\mathcal L_{seg}=CE(m, \hat{m}), L_{seg}^r=CE(m, m_r)$。由于风格编码的维度较低,此时可以通过均值和方差拉向正态分布,达到风格编码向先验分布靠近,$\mathcal L_{dist} = \Vert \hat\mu_r \Vert_1 + \Vert \hat\sum_T - I \Vert_1 + \Vert diag(\hat\sum_T) - 1 \Vert_1$。对于内容编码损失$\mathcal L_{c}$和风格编码损失$\mathcal L_s$,则是通过$L_1$损失一致性优化,即$\mathcal L_s = \Vert \hat s - s^\prime \Vert_1, \mathcal L_s^r = \Vert \tilde s - s_r \Vert_1, \mathcal L_c = \Vert \hat c - c \Vert_1, \mathcal L_c^r = \Vert \tilde{c}_r - c \Vert_1$。
总的损失可变式为:
\[\begin{equation} \begin{aligned} \min_{E_c,E_s,G}\max_D \mathcal L(E_c,E_s,G,D) &= \lambda_1(\mathcal L_{adv} + \mathcal L_{adv}^r)+\lambda_2(\mathcal L_{rec}+ \mathcal L_{rec}^r+ \mathcal L_{cyc}) +\lambda_3(\mathcal L_{seg} + \mathcal L_{seg}^r) \\ &+\lambda_4(\mathcal L_{c} + \mathcal L_{c}^r) +\lambda_5 \mathcal L_{s}+\lambda_6 \mathcal L_{s}^r +\lambda_7 \mathcal L_{dist} \end{aligned} \end{equation}\]其中$\lambda_{i},i \in [1,7]$为超参数,HiDT的模型优化算是对图像翻译下的损失进行了一个系统的介绍。
增强处理
由于内存和计算时间的限制,在高分辨率图像上进行图像翻译是不可行的。文章进行了一个增强处理,整个过程如图4所示。
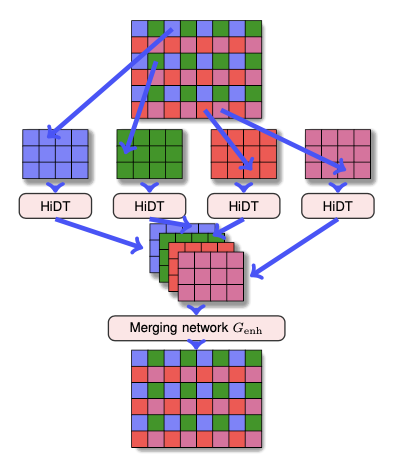
图4.HiDT增强处理下拆分和融合方案
虽然内存和时间的限制可以通过在中等分辨率训练,并以完全卷积的方式应用于高分辨率图像;或者可以使用引导过滤[4]对中等分辨率的处理结果进行升采样。但是,经过实验文章发现完全卷积的应用可能会由于感受野有限而导致场景崩塌,在夕阳下可能会出现多个太阳,或者在水反射下可能会混淆天空和水面之间的边界。另一方面,引导过滤在水或阳光下能较好地实现转换,但如果通过样式转换更改细小细节,则引导过滤将失败,在高对比度边界附近产生光晕伪影。
为此,作者提出了图4所示的增强处理拆分和融合方案,对原始的高分辨率图像\(x_{hi}\)分为不同的移位版本,根据保留移位位置像素,对于中间的像素用0去替代,得到移位的高分辨率图像\(\lbrace x_{hi}^i \rbrace_i\),对移位后的图像进行双线性下采样得到中等分辨率图像\(\lbrace x_{med}^i \rbrace_i\),文中的移位版本设置为16,对这16个中等分辨率图像进行图像翻译,即\(\hat{x}_{med}^{i} = G(E_c(x_{med}^{i}),E_s(x_{med}^{i}))\),再由这16个中等分辨率图像经过融合网络\(G_{enh}\)融合得到高分辨率图像输出,图4则是大致的演示过程。
实验
对于对比的基线选择,文章选择了FUNIT[2]和DRIT[5],在定性对比上,得到的结果如图5所示,从左到右对应的是原始图像、FUNIT-T、FUNIT-O、HiDT。

图5.HiDT定性结果对比
定量上也展示了优越的结果。
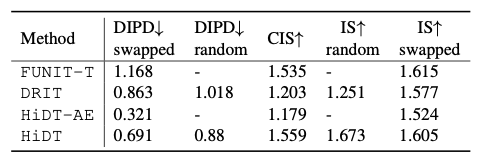
图6.HiDT定量结果对比
对于自然场景图像时移变换下,通过随机采样$N$的设置,可以实现多域的生成,图7展示了时移图像的转换结果。

图7.HiDT自然场景时移结果
由于模型的设计,HiDT可根据指导图像进行指导转换,图8为展示结果。

图8.HiDT指导图像进行转换
在消融实验上,当去掉分割掩码损失,转换结果上大幅度下降。

图9.HiDT去掉分割掩码损失后的结果
在高分辨率上的拆分和融合上展示了一定的结果。

图10.HiDT高分辨率图像下的结果
总结
HiDT作为图像翻译模型,在训练和推理过程中均不依赖域标签,通过增强方案解决了图像翻译下高分辨率图像的转换。模型主要用于自然场景时移图像的合成,在定性和定量结果上展示了优越的结果。
整体而言,HiDT与MUNIT存在着一定的相似性,但是网络结构中通过U-Net和AdaIN的结合实现了更好的翻译结果,同时在高分辨率转换上也取得了一定的成效,这归功于HiDT的拆分和融合思想,同时自然场景时移变换在很多场合下有着积极的意义。
参考文献
[1] Xun Huang, Ming-Yu Liu, Serge Belongie, and Jan Kautz. Multimodal Unsupervised Image-to-Image Translation. In Vittorio Ferrari, Martial Hebert, Cristian Sminchisescu, and Yair Weiss, editors, Computer Vision – ECCV 2018, pages 179–196, Cham, 2018. Springer International Publishing. 1, 2, 6
[2] Ming-Yu Liu, Xun Huang, Arun Mallya, Tero Karras, Timo Aila, Jaakko Lehtinen, and Jan Kautz. Few-shot unsupervised image-to-image translation. In The IEEE International Conference on Computer Vision (ICCV), October 2019. 1, 2, 3, 6
[3] Choi Y, Uh Y, Yoo J, et al. StarGAN v2: Diverse Image Synthesis for Multiple Domains[J]. arXiv preprint arXiv:1912.01865, 2019.
[4] K. He, J. Sun, and X. Tang. Guided Image Filtering. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(6):1397–1409, June 2013. 2, 4
[5] Hsin-Ying Lee, Hung-Yu Tseng, Qi Mao, Jia-Bin Huang, Yu-Ding Lu, Maneesh Singh, and Ming-Hsuan Yang. DRIT++: diverse image-to-image translation via disentangled representations. CoRR, abs/1905.01270, 2019. 1, 2, 6

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







