StarGAN v2图像翻译下的标榜模型
近期NVIDIA发布的StyleGAN2对于GAN用于图像生成又推进了一把,同时也是赚足了眼球,然而同期下另一篇图像翻译任务下的改进版模型却显得有点默默无闻了,这就是今天我们要介绍的StarGAN v2。模型整体在StarGAN[1]的基础上解决了图像翻译任务中源域的图像转换为目标域的多种图像,并支持多个目标域的问题,实现了较好的源域图像到目标域图像的转换,值得一说的是文章还公布了一个动物面部图像数据集,即将发布于作者的Github下。
论文引入
图像翻译旨在学习不同视觉域之间的映射,域这个概念在视觉下表示一组图像,这组图像可以将它们分组为视觉上独特的类别,比如一个域全是由狗的图像构成,我们称这个就是一个域,在这个域下全是狗的图像,但是狗又可以细分为拉布拉多、斗牛犬、巴哥、柴犬等这些具有特定风格的图像,在一个大类下的分支它们具有这个类的属性,但是又有自己独特的特征,我们称此为风格,推演到人的话,妆容、胡须、卷发也可以定义为风格。
这种不同域下不同的风格进行转换是相对复杂的,之前的论文在处理这种人脸风格图像的时候往往通过热编码进行有监督的一一属性之间的转换,但是这种热编码的标签在同一张图像输入得到的目标属性的结果往往是相同的,因为我们的输入是相同的,标签也是相同的,得到的结果也是一致的,这种方式也是原始的StarGAN[1]采用的转换方式。另一种转换的方式就类似于CycleGAN[2]那样,从一个域简单的转换到另一个域,可以实现斑马到马,博美到吉娃娃这种单一的转换,如果要实现博美到萨摩这种变换,往往需要重新设计一组生成器。那么由$N$中风格图像的转换的话,就需要设计$N \times (N-1)$种生成器,这显然是不合理的。上述分析的两个问题就是图像翻译任务下的两个需要解决的问题。
为了实现由一个域图像转换到目标域的多种图像,并支持多个目标域的问题,StarGAN v2便在StarGAN的基础上进行了改进,并且解决了这两类问题。StarGAN是不是第一篇处理这两个问题的呢?答案是否定的,在18年由NVIDIA发表的MUNIT[3]就成功的解决了这两类问题,StarGAN v2算是在MUNIT的基础上实现了更加简洁易懂的处理和图像翻译任务。
为了展示模型的转换效果,这里先贴一张实验效果图。

图1.StarGAN v2图像转换效果展示
总结一下StarGAN v2的优势:
- 设计了Mapping Network用于生成风格编码,摆脱了标签的束缚;
- 用风格编码器指导Mapping Network进行目标风格学习,可以实现目标域下多风格图像的转换;
- 公开了动物面部数据集AFQH,实现了图像翻译下较好的结果。
StarGAN v2模型结构
在具体介绍模型前,我们先来规定下用到的符号,源域图像$x \in \mathcal X$,目标域图像$y \in \mathcal Y$,StarGAN v2的目的是设计单个生成器$G$,该生成器$G$可以生成与图像$x$对应的每个域$y$的不同图像。我们先来看看原文中给的整体结构图。
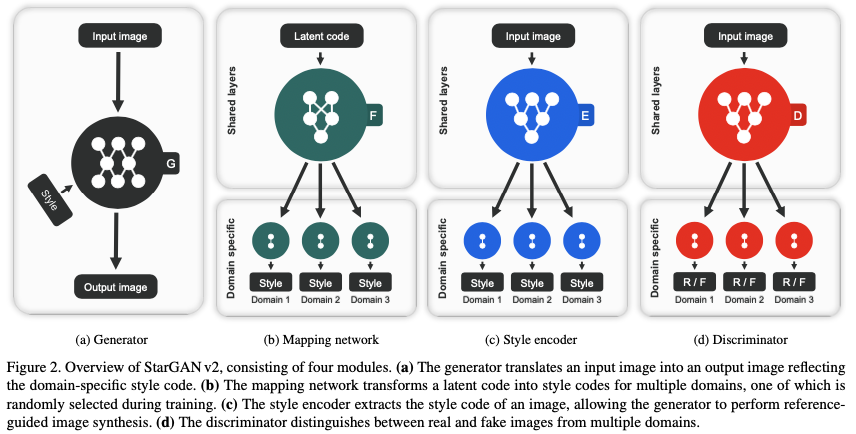
图2.StarGAN v2模型整体结构
图2给出的结构是一个很笼统的图示,可以看出StarGAN v2由四部分组成,生成器$-G$,映射网络$-F$,风格编码器$-E$判别器$-D$。我们先捋一下整个过程,首先映射网络学习到目标域图像的风格编码$\hat s = F_{\hat y}(z)$,其中$\hat y \in \mathcal Y$,这是映射网络学习到的目标域图像的风格编码,而作为参照真实目标域图像的风格编码由风格编码器得到$s=E_y(y)$,得到了风格编码$\hat s$结合源域输入图像$x$便可送入到生成器,生成器输出的就是转换后的目标域图像$G(x, \hat s)$,而判别器则为了区分生成的目标域图像是否是真实来源于真实目标域。
从大方向上捋了一下StarGAN v2的结构,是不是有几个问题要问,为什么设计了映射网络就能实现由源域图像转换到目标域下多幅图像?多幅图像是怎么得到的?这里的风格编码器除了优化映射网络还能用来干嘛?具体的网络细节要怎么实现?
我们将从这几个问题详细的解释下StarGAN v2,这里的映射网络的输入是一个先验$z$,根据我们的经验的话,这个$z$可以设置为高斯分布,映射网络学习到的是目标域图像的风格表示,也就是说源域图像$x$提供的是源域图像的大致的内容信息,而风格编码$\hat s$则提供了目标域的风格表示,这部分可以指导源域图像$x$按照告诉的风格$\hat s$去转换到目标域下的图像。重点来了,我们在采样$z$下,由于每次采样是不同的,固然得到的风格表示也是不同的,这样每次的$\hat s$也是不一样的,所以可以由固定的一张$x$根据不同的风格表示$\hat s$生成出目标域下不同的风格图像。这就是前两个问题的实现答案。
风格编码器当然不是单纯用来优化映射网络的,它的另一个大作用是为了在应用阶段作为目标域图像风格的指导器,也就是如果我想指定生成器生成我要求的目标域中某张图像$y$的风格,这个时候就不能送入给生成器随机采样得到的$\hat s$,此时应该馈送进去的是此时的风格编码器的输出$s=E_y(y)$。这样生成出的图像就是指定的风格了,这里可以理解为风格编码器在测试阶段就是一个在线标签生成器,用来指定生成器要按照什么风格进行转换。
最后就是网络的具体实现,这部分我根据作者给出的附录整理了一下,得到了图3的模型设计图。
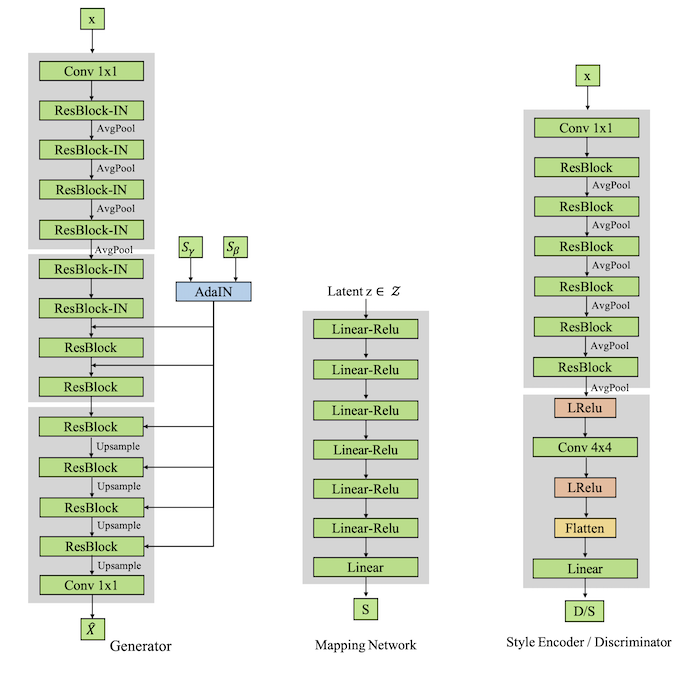
图3.StarGAN v2模型设计结构
这里要强调的是映射网络、风格编码器和判别器的输出都是多分支的,因为文章的目的是进行多目标域的转换,这里的多分支就是不同的目标域的表示,对于映射网络和风格编码器,多分支表示的是多个目标域图像的风格表示,对于判别器多分支则是代表不同目标域的判别真假情况,作者在附录中用$N$表示分支数。虽然作者没有具体的公布代码,有了上述的具体结构,复现简易版本StarGAN v2应该是没啥问题的,要想写代码还是需要对损失函数做简单的解释。
损失函数
上一章节如果读透了,损失函数这部分就没啥要介绍的了,首先是生成器和判别器的对抗损失:
\[\mathcal L_{adv} = \mathbb E_{x,y}[logD_y(x)] + \mathbb E_{x, \hat y, z}[log(1-D_{\hat y}(G(x, \hat s)))]\]这里提一下,虽然公式前半部分写的是$x$,但是在训练阶段肯定是参照的是目标域图像作为真实的,当然,可以设计双向网络,也就是源域和目标域可以实现相互转换。
为了优化映射网络,设计了风格重构损失:
\[\mathcal L_{sty} = \mathbb E_{x, \hat{y}, z} [\Vert \hat{s} - E_{\hat{y}}(G(x, \hat{s})) \Vert_1]\]为了让映射网络可以学习到更多的目标域下的不同风格,也就是让风格更加的多样化,设计了距离度量损失,也就是希望每次得到的风格表示尽量的不一致,这样风格就会更加丰富,所以是最大化$\mathcal L_{ds}$:
\[\mathcal L_{ds} = \mathbb E_{x, \hat{y}, z_1, z_2}[\Vert G(x,\hat{s}_1) - G(x, \hat{s}_2) \Vert]\]为了保留源域的特征,作者又加入了一个循环一致损失:
\[\mathcal L_{cyc} = \mathbb E_{x, y, \hat{y},z}[\Vert x - G(G(x, \hat{s}), s) \Vert_1]\]在最终的损失优化上:
\[\mathcal L_D = - \mathcal L_{adv}\] \[\mathcal L_{F,G,E} = \mathcal L_{adv} + \lambda_{sty} \mathcal L_{sty} - \lambda_{ds} \mathcal L_{ds} + \lambda_{cyc} \mathcal L_{cyc}\]实验
对于基线的选择,作者选定了MUNIT[3]、DRIT[4]和MSGAN[5]这几个都是图像翻译中代表性的文章,数据集上作者在CelebA HQ和自己公布的动物脸部数据集 AFHQ上进行了测试,至于评估标准除了大家熟悉的FID外,还引入了LPIPS[6],这是一个衡量图像色块相似度的指标(越大越好)。
在定性实验对比上可以看到StarGAN v2转换得到的图像更加的逼真和多样性,这个在CelebAHQ和AFHQ数据集上都得到了体现。

图4.StarGAN v2定性实验结果
在有参照的测试结果也同样展示了优越的结果。

图5.StarGAN v2在有参照图像下定性实验结果
定量实验和人力评估上也都展示了优秀的结果。
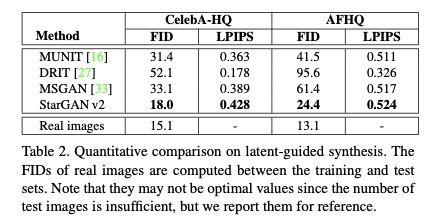
图6.StarGAN v2定量实验结果
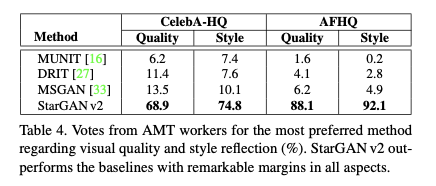
图7.StarGAN v2人力评估下实验结果
总结
StarGAN v2最大的创新之处就是设计了Mapping Network,这个将固定的风格编码用更加灵活的映射网络去学习,可以更加丰富的学习到风格表示,同时整个网络的设计也像较于MUNIT得到了一定的精简,结构更加清晰。网络的整体架构参考了StyleGAN的优越的生成效果,在图像转换上进一步得到了提高,同时也处理了图像翻译下将一个域的图像转换为目标域的多种图像,并支持多个目标域的问题。
参考文献
[1] Y. Choi, M. Choi, M. Kim, J.-W. Ha, S. Kim, and J. Choo. Stargan: Unified generative adversarial networks for multidomain image-to-image translation. In CVPR, 2018. 2, 3, 4
[2] Zhu J Y, Park T, Isola P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2223-2232.
[3] X. Huang, M.-Y. Liu, S. Belongie, and J. Kautz. Multimodal unsupervised image-to-image translation. In ECCV, 2018. 2, 3, 4, 6, 7, 8, 12
[4] H.-Y. Lee, H.-Y. Tseng, J.-B. Huang, M. K. Singh, and M.-H. Yang. Diverse image-to-image translation via disentangled representations. In ECCV, 2018. 2, 3, 4, 6, 7, 8
[5] Q. Mao, H.-Y. Lee, H.-Y. Tseng, S. Ma, and M.-H. Yang. Mode seeking generative adversarial networks for diverse image synthesis. In CVPR, 2019. 2, 3, 4, 6, 7, 8
[6] R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang. The unreasonable effectiveness of deep features as a perceptual metric. In CVPR, 2018. 4, 9

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







