UGATIT-自适应图层实例归一化下图像到图像转换
生成对抗网络(GAN)在这几年的发展下已经渐渐沉淀下来,在网络的架构、训练的稳定性控制、模型参数设计上都有了指导性的研究成果。我们可以看出17、18年大部分关于GAN的有影响力的文章多集中在模型自身的理论改进上,如PGGAN、SNGAN、SAGAN、BigGAN、StyleGAN等,这些模型都还在强调如何通过随机采样生成高质量图像。19年关于GAN的有影响力的文章则更加关注GAN的应用上,如FUNIT、SPADE等已经将注意力放在了应用层,也就是如何利用GAN做好图像翻译等实际应用任务。学术上的一致性也暗示了GAN研究的成熟,本文主要介绍一种利用GAN的新型无监督图像转换论文U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation。
论文引入
图像到图像转换可以应用在很多计算机视觉任务,图像分割、图像修复、图像着色、图像超分辨率、图像风格(场景)变换等都是图像到图像转换的范畴。生成对抗网络[1]不仅仅在模型训练的收敛速度上,同时在图像转换质量上展示了优越的结果。这些优越性能相比Pixel CNN、VAE、Glow都是具有很大竞争力的。所以近年来的围绕GAN实现图像翻译的研究是很多的,例如CycleGAN、UNIT、MUNIT、DRIT、FUNIT、SPADE。图像翻译是GAN铺开应用的第一步,跨模态间的转换,文本到图像、文本到视频、语音到视频等,凡是这种端到端,希望实现一个分布到另一个分布转换的过程,GAN都是可以发挥一定的作用的。
回归到现实,图像到图像的转换到目前为止还是具有一定挑战性的,大多数的工作都围绕着局部纹理间的转换展开的,例如人脸属性变换、画作的风格变换、图像分割等,但是在图像差异性较大的情况下,在猫到狗或者是仅仅是语义联系的图像转换上的表现则不佳的。这就是图像转换模型的适用域问题了,实现一个具有多任务下鲁棒的图像转换模型是十分有必要的。本文将要介绍的U-GAT-IT正是为了实现这种鲁棒性能设计的,我们先宏观的看一下文章采用何种方式去实现这种鲁棒性能。
首先是引入注意力机制,这里的注意力机制并不传统的Attention或者Self-Attention的计算全图的权重作为关注,而是采用全局和平均池化下的类激活图(Class Activation Map-CAM)[2]来实现的,CAM对于做分类和检测的应该很熟悉,通过CNN确定分类依据的位置,这个思想和注意力是一致的,同时这对于无监督下语义信息的一致性判断也是有作用的,这块我们后续再进行展开。有了这个注意力图,文章再加上自适应图层实例归一化(AdaLIN),其作用是帮助注意力引导模型灵活控制形状和纹理的变化量。有了上述的两项作用,使得U-GAT-IT实现了鲁棒下的图像转换。总结一下U-GAT-IT的优势:
- 提出了一种新的无监督图像到图像转换方法,它具有新的注意模块和新的归一化函数AdaLIN。
- 注意模块通过基于辅助分类器获得的注意力图区分源域和目标域,帮助模型知道在何处进行密集转换。
- AdaLIN功能帮助注意力引导模型灵活地控制形状和纹理的变化量,增强模型鲁棒性。
模型结构
端到端模型最直观的展示就是模型结构图,我们看一下U-GAT-IT实现结构:
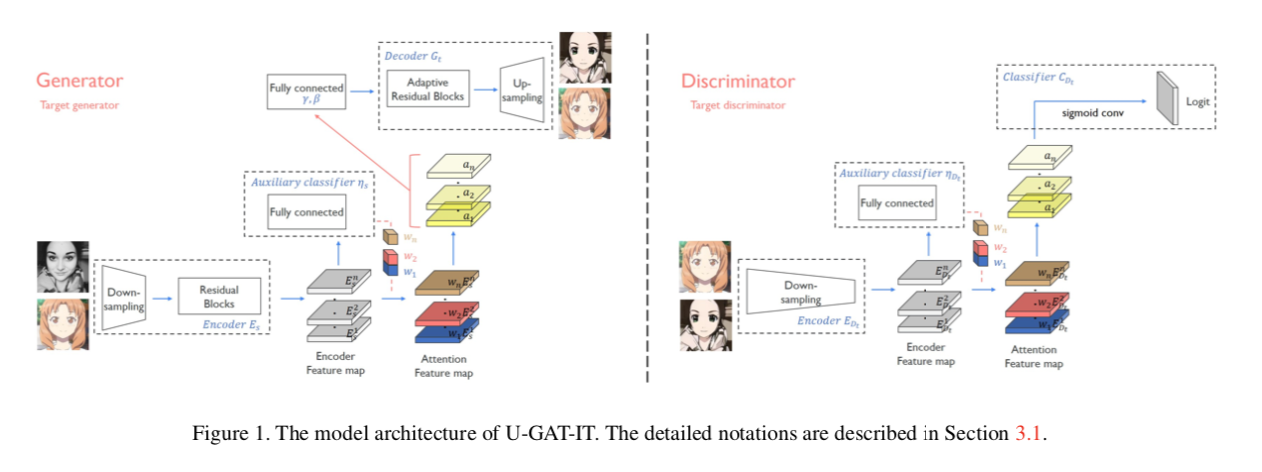
我们先把我们能直观看懂的部分做一个介绍,模型分为生成器和判别器,可以看到生成器和判别器的结构几乎相同,生成器好像多了一点操作(这多的这点就是AdaLIN和Decoder部分),我们分析生成器,首先是对端的输入端进行图像的下采样,配合残差块增强图像特征提取,接下来就是注意力模块(这部分乍一看,看不出具体细节,后续分析),接着就是对注意力模块通过AdaLIN引导下残差块,最后通过上采样得到转换后的图像。对于判别器相对于生成器而言,就是将解码过程换成判别输出。
重点来了,就是如何实现图像编码后注意力模块以及AdaLIN怎样引导解码得到目标域图像的呢?
CAM & Auxillary classifier
对于这部分计算CAM,结合模型结构图做进一步理解:
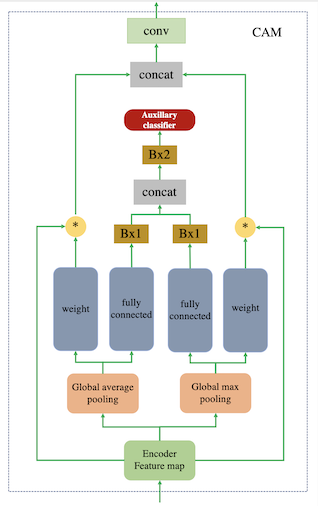
由上图,我们可以看到对于图像经过下采样和残差块得到的Encoder Feature map经过Global average pooling和Global max pooling后得到依托通道数的特征向量。创建可学习参数weight,经过全连接层压缩到$B \times 1$维,这里的$B$是BatchSize,对于图像转换,通常取为1。对于学习参数weight和Encoder Feature map做multiply(对应位想乘)也就是对于Encoder Feature map的每一个通道,我们赋予一个权重,这个权重决定了这一通道对应特征的重要性,这就实现了Feature map下的注意力机制。对于经过全连接得到的$B \times 1$维,在average和max pooling下做concat后送入分类,做源域和目标域的分类判断,这是个无监督过程,仅仅知道的是源域和目标域,这种二分类问题在CAM全局和平均池化下可以实现很好的分类。当生成器可以很好的区分出源域和目标域输入时在注意力模块下可以帮助模型知道在何处进行密集转换。将average和max得到的注意力图做concat,经过一层卷积层还原为输入通道数,便送入AdaLIN下进行自适应归一化。
AdaLIN
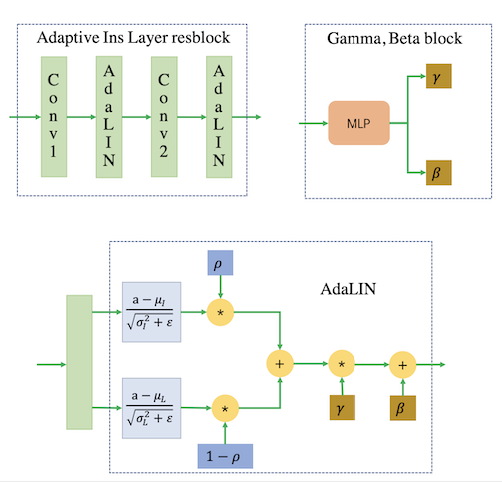
由上图,完整的AdaLIN操作就是上图展示,对于经过CAM得到的输出,首先经过MLP多层感知机得到$\gamma , \beta$,在Adaptive Instance Layer resblock中,中间就是AdaLIN归一化。AdaLIN正如图中展示的那样,就是Instance Normalization和Layer Normalization的结合,学习参数为$\rho$,论文作者也是参考自BIN[3]设计。AdaIN的前提是保证通道之间不相关,因为它仅对图像map本身做归一化,文中说明AdaIN会保留稍多的内容结构,而LN则并没有假设通道相关性,它做了全局的归一化,却不能很好的保留内容结构,AdaLIN的设计正是为了结合AdaIN和LN的优点。
判别器
文章的源码中,判别器的设计采用一个全局判别器(Global Discriminator)以及一个局部判别器(Local Discriminator)结合实现,所谓的全局判别器和局部判别器的区别就在于全局判别器对输入的图像进行了更深层次的特征压缩,最后输出的前一层,feature map的尺寸达到了$\frac{h}{32} \times \frac{w}{32}$,根据感受野的传递,这个尺度卷积下的感受野是作用在全局的(感受野超过了图像尺寸),读者可以自行按照论文给出的网络设计参数进行计算(kernel全为4),(我算的结果是$286 \times 286$比输入图像$256 \times 256$要大)对于局部判别器,最后输出的前一层,feature map的尺寸达到了$\frac{h}{8} \times \frac{w}{8}$,此时感受野是达不到图像尺寸(我算的结果是$70 \times 70$),这部分称为局部判别器。最后通过extend将全局和局部判别结果进行连接,此处要提一下,在判别器中也加入了CAM模块,虽然在判别器下CAM并没有做域的分类,但是加入注意力模块对于判别图像真伪是有益的,文中给出的解释是注意力图通过关注目标域中的真实图像和伪图像之间的差异来帮助进行微调。
损失函数
对于利用GAN实现图像到图像转换的损失函数其实也就那几个,首先是GAN的对抗损失$\mathcal L_{gan}$,循环一致性损失$\mathcal L_{cycle}$,以及身份损失(相同域之间不希望进行转换)$\mathcal L_{identity}$,最后说一下CAM的损失。CAM的损失主要是生成器中对图像域进行分类,希望源域和目标域尽可能分开,这部分利用交叉熵损失: \(\mathcal L_{cam} = -(\mathbb E_{x \sim X_s}[log(\eta_s(x))]+\mathbb E_{x \sim X_t}[log(1 - \eta_t(x))])\) 在判别器中,也对真假图像的CAM进行了对抗损失优化,主要是为了在注意图上进一步区分真假图像,最后得到完整的目标函数: \(\mathcal L = \lambda_1 \mathcal L_{gan} + \lambda_2 \mathcal L_{cycle} + \lambda_3 \mathcal L_{identity} + \lambda_4 \mathcal L_{cam}\)
Trick和AdaLIN实现代码
作者公布的源码如果大家尝试运行可能会参数爆内存,这里的罪魁祸首发生在计算自适应图层实例归一化下的MLP直接从卷积展平送到全连接层中参数过大,大致计算一下,从$1 \times 64 \times 64 \times 256$直接展平的尺寸是$1 \times 1048576$再进行全连接操作,这个计算量是很大的,为了减小计算量,可以在这一步先对map进行global average pooling再进行全连接操作。对于生成器Encoder部分的归一化采用IN,Decoder采用LIN,判别器网络加上谱归一化限制(生成器并没有加),我们接下来放上论文的核心AdaLIN的tensorflow下代码实现:
def adaptive_instance_layer_norm(x, gamma, beta, smoothing=True, scope='instance_layer_norm'):
with tf.variable_scope(scope):
ch = x.shape[-1]
eps = 1e-5
# 计算Instance mean,sigma and ins
ins_mean, ins_sigma = tf.nn.moments(x, axes=[1, 2], keep_dims=True)
x_ins = (x - ins_mean) / (tf.sqrt(ins_sigma + eps))
# 计算Layer mean,sigma and ln
ln_mean, ln_sigma = tf.nn.moments(x, axes=[1, 2, 3], keep_dims=True)
x_ln = (x - ln_mean) / (tf.sqrt(ln_sigma + eps))
# 给定rho的范围,smoothing控制rho的弹性范围
if smoothing:
rho = tf.get_variable("rho", [ch], initializer=tf.constant_initializer(0.9),
constraint=lambda x: tf.clip_by_value(x,
clip_value_min=0.0, clip_value_max=0.9))
else:
rho = tf.get_variable("rho", [ch], initializer=tf.constant_initializer(1.0),
constraint=lambda x: tf.clip_by_value(x,
clip_value_min=0.0, clip_value_max=1.0))
# rho = tf.clip_by_value(rho - tf.constant(0.1), 0.0, 1.0)
x_hat = rho * x_ins + (1 - rho) * x_ln
x_hat = x_hat * gamma + beta
return x_hat
实验
作者在五个不成对的图像数据集评估了方法的性能,有比较熟悉的马和斑马,猫到狗,人脸到油画,风格场景还有就是最让我感兴趣的作者团队创建的女性到动漫的数据集,不过可惜的是这个数据集作者并没有公布。
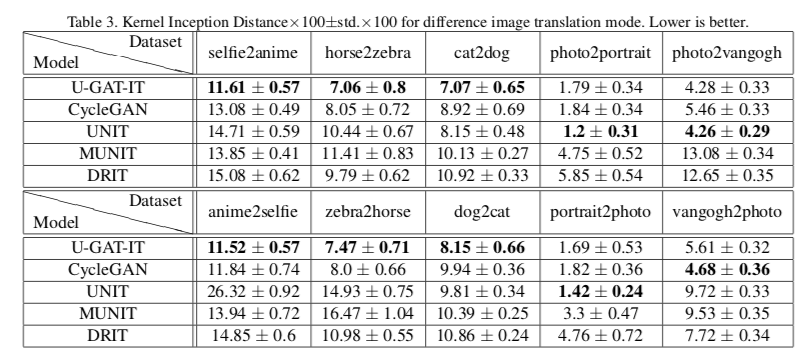
在定性和定量上,U-GAT-IT都展示了优越的结果:

总结
论文提出了无监督的图像到图像转换(U-GAT-IT),其中注意模块和AdaLIN可以在具有固定网络架构和超参数的各种数据集中产生更加视觉上令人愉悦的结果。辅助分类器获得的关注图可以指导生成器更多地关注源域和目标域之间的不同区域,从而进行有效的密集转换。此外,自适应图层实例规范化(AdaLIN)可以进一步增强模型在不同数据集下的鲁棒性。
参考文献
[1] Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]//Advances in neural information processing systems. 2014: 2672-2680.
[2] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba. Learning deep features for discriminative localization. In Computer Vision and Pattern Recognition (CVPR), 2016 IEEE Conference on, pages 2921–2929. IEEE, 2016. 2, 3
[3] H. Nam and H.-E. Kim. Batch-instance normalization for adaptively style-invariant neural networks. arXiv preprint arXiv:1805.07925, 2018. 2, 3

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







