img2poem论文解读
诗歌讲究句式、格调、语言含义等一系列规则,一首好的诗歌会给人以强烈的画面感,在视觉和心灵上引发读者的共鸣。让机器去创造诗歌,这可能会令很多文人嗤之以鼻, 他们肯定会认为让一个没有任何感情的机器如何去创作诗歌。话虽如此,但是机器的一个最大的优势就是知识量渊博,茫茫的诗歌库对于机器可能只要几天就能掌握, 书到用时方恨少,现在已经掌握了庞大数量的书去创造诗歌,结果如何呢?
论文引入
文字是对客观事物的抽象表达,是一个概述性的,这也是人类之所以称为智慧生物的原因,我们掌握着文字并懂得利用文字去表达个人的看法。同时, 文字也是枯燥的,相比于图像和视频人类可能更能在短时间接受的是图像和视频内容,这也叫眼见为实。当我们充分掌握了一个场景的事物,我们希望用更凝练的文字去描述, 这就有了记叙的文字段落,更深一层次有了诗歌的创作。
诗歌是在文字的基础上更加凝练和写意,人类掌握诗歌的前提是已经可以熟练的运用文字,让一个文盲去品味一首好诗估计也不会有多大的见解,我们用一个例子分析:

用文字去描述上面这幅图,只是简单的说明图像内容,而诗歌的描述则更加具有画面感和生动性,这就是诗歌的魅力所在,往往可以用更少的文字实现丰富的表达。 当然诗歌的创作难度是更大的,不能简单的通过文字的组合来实现。Beyond Narrative Description: Generating Poetry from Images by Multi-Adversarial Training 就是实现了图像到诗歌的生成,我们之后简称为img2poem。这篇论文是2018年ACM MM的Best Paper,模型在实现诗歌创作中运用了两个判别器做指导, 通过在生成上的奖励机制实现了图像到诗歌较好的生成。
随着机器学习的发展,涉及视觉和语言的研究引起了广泛关注,关于图像描述(像图像标题技术和图像生成短文)的研究数量呈现出爆发式的增长。 图像描述的研究旨在根据图像生成使用人类语言描述事实的语句。img2poem希望完成更具认知性的工作:以诗歌创作为目的,根据图像生成诗歌语言。
在已知的诗歌生成上,Facebook提出了使用神经网络来生成英文韵律诗, 微软开发了一个叫作“小冰”的系统,其最重要的功能之一正是生成诗歌。不过,以端对端的方式从图像生成诗歌仍然是一个新的主题,面临着巨大挑战。
从一幅图像生成诗歌,需要面临以下三个挑战:首先,与根据主题生成诗歌相比,这是一个跨模态的问题。从图像生成诗歌的一种直观方法是先从图像中提炼关键词或说明文字, 然后以这些关键词或说明文字为种子,生成诗歌,正如从主题生成诗歌那样。但是,关键词或说明文字会丢失许多图像信息,更不用说对诗歌生成十分重要的诗歌线索了。 其次,与图像标题技术和图像生成短文相比,从图像生成诗歌是一项更主观的工作,这意味着同一幅图像可以对应不同方面的多首诗歌,而图像标题技术/图像生成短文更多地是描述图像中的事实, 并生成相似的语句。第三,诗句的形式和风格与叙述语句不同。
img2poem主要关注的是一种开放形式的诗歌——自由诗。在不要求格律、韵律或其他传统的诗歌技术下,要有诗歌结构和诗歌语言,可以称之为诗意。 例如,诗歌的长度一般有限;与图像描述相比,诗歌一般偏好特定的词语;诗歌中的语句应与同一主题相关,保持一致。
img2poem的主要优势为:
- 提出以自动方式从图像生成诗歌(英文自由诗),这是首个尝试在整体框架中研究图像生成英文自由诗歌问题,它使机器在认知工作中能够具备接近人类的能力。
- 将深度耦合的视觉诗意嵌入模型与基于RNN的联合学习生成器结合,其中两个判别器通过多对抗训练,为跨模态相关性和诗意提供奖励。
- 收集了首个人类注解的图像-诗歌对数据集,以及最大的公共诗歌语料数据集。
模型框架
我们还是先从模型的框架图入手分析:
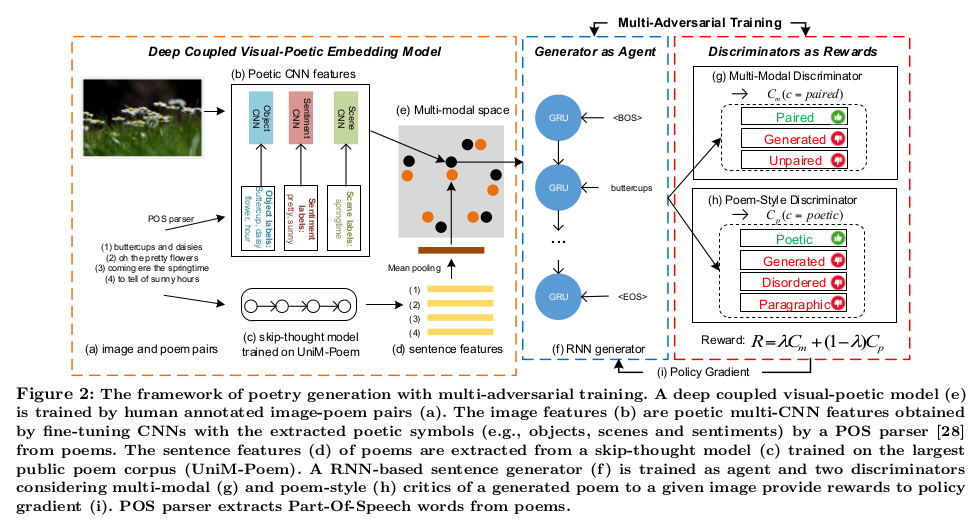
可以将img2poem模型分为3部分,左侧为深层图像诗歌耦合模块,中间是基于GRU的诗歌生成器,右侧是两个用于生成器奖励机制的判别器,我们先整体的分析一下各个模块。
对于深层图像诗歌耦合模块,它的目的是为了让配对的诗歌和图像做特征上的融合,将诗歌和图像建立深层的特诊联系,最理想的结果就是实现图像和诗歌的配对。 为了保证诗歌的对象、场景和情感信息,图像的特征提取也做了对象、场景和情感信息的分别提取;对于诗歌通过skip- thought模型提取得到诗歌特征; 将图像特征和诗歌特征映射到多模态空间下,作为诗歌生成器的输入。
诗歌生成器采用基于RNN的GRU框架,通过语句开始
最后的判别器为生成器提供奖励机制,对于生成的诗歌由一个判别器做生成的诗歌是否和图像配对,是否是生成的图像来提高生成器生成配对诗歌能力。 下面一个判别器则是强调生成器生成诗歌的诗意,通过对生成诗歌的诗意、顺序和段乱性判断,增强生成器生成诗歌的诗意。最后通过奖励函数为生成器提供指导生成。
接下来我们对每一部分详细描述。
深层图像诗歌耦合
图像诗歌嵌入模型的目标是学习嵌入空间,在该空间中不同模态的点(例如图像和语句)可以得到映射。假设一对图像和诗歌共享相同的诗歌语义, 使嵌入空间是可习得的。通过将图像和诗歌嵌入相同的特征空间,能够使用一首诗和一幅图像呈现的诗歌向量来直接计算它们之间的相关性。
对图像提取特征采用CNN实现,分别提取图像对应的对象、场景和情感特征。对象特征就是例如一幅图中的物体,比如蝴蝶,猎鹰等;场景就是对图像环境特征, 比如艳阳高照、大雨滂沱;情感就是图像赋予的感情,比如欢快、阴郁。为了缩小图像视觉表达和诗歌文本表达之间的语义分歧,文章提出使用多模态诗歌数据集来微调这三种网络。 通过挑选诗歌中与物品、情感和场景相关的常用关键词作为标签词汇,然后以多模态诗歌数据集为依据,为物品、情感和场景的检测分别建立了三个多标签数据集。 多标签数据集建成后,分别在三个数据集中对预先训练的CNN模型进行了微调,通过公式(1)交叉熵损失做优化。
\[\begin{equation} loss = - \frac{1}{n} \sum_{n=1}^N (t_n log p_n + (1 - t_n)log(1 - p_n)) \end{equation}\]其中$t_n$是标签,$p_n$为CNN输出的预测标签,通过微调可进一步建立图像和诗歌之间的相关性,再将提取的特征整合在一起:
\[v_1 = f_{Object}(I), v_2 = f_{Scene}(I), v_3 = f_{Sentiment}(I), v = (v_1, v_2, v_3).\]最后对特征做线性映射,嵌入到多模态空间下,其中$W_v \in \mathbb R^{K \times N}$是图像嵌入矩阵,$b_v \in \mathbb R^K$是图像偏差向量:
\[\begin{equation} x = W_v \cdot v + b_v \end{equation}\]这里的$v$在最后经过全连接层的维度为$D$,三个串联在一起就是$N = D \times 3$。根据诗歌语句的skip-thought 平均值计算出诗歌的表达特征向量,使用有M维向量的Combine-skip,记为$t \in \mathbb R^M$,skip-thought模型在单模态诗歌数据集得到训练,与图像嵌入类似, 其中$W_t \in \mathbb R^{K \times M}$是诗歌嵌入矩阵,$b_t \in \mathbb R^K$表示诗歌偏差向量,诗歌嵌入被表示为:
\[\begin{equation} m = W_t \cdot t + b_t \end{equation}\]最后,使用点积相似性最大限度地减少每对的排序损失,从而将图像和诗歌一起嵌入:
\[L = \sum_x \sum_k max(0, \alpha - x \cdot m + x \cdot m_k) + \sum_m \sum_k max(0, \alpha - m \cdot x + m \cdot x_k)\]其中$m_k$是用于图像嵌入x的比较研究诗歌,例如不匹配的,不相关的;而$x_k$则是诗歌嵌入m的比较,$\alpha$代表对比边际。
诗歌生成器
诗歌生成器采用的是非分层的递归模型,通过将句尾标记作为词汇中的一个词语来处理。这样做主要是因为相比段落,诗歌包含的词语数量通常更少; 此外,训练诗歌中语句之间的层次一致性更低,这使得句子间的层次更难学习。生成的模型包括图像编码器CNN和诗歌解码器RNN,其中编码器就是对由上面的提取的图像特征做进一步编码, 这里的编码器也是基于RNN的GRU处理的。
对于解码器,假设$\theta$是模型的参数,$y = y_{1:T} \in \mathbb Y^*$,这里的T生成语句的最大长度(包括代表语句开始的
令$r(y_{1:t})$代表时间t时取得的奖励,而$R(y_{1:T})$是累计奖励,即$R(y_{k:T}) = \sum_{t-k}^T r(y_{1:t})$。给定之前的所有词语$y_{1:(t-1)}$, 使$p_{\theta} (y_t \vert y_{1:(t-1)})$为在时间t时,挑选$y_t$的参数条件概率。每批次的策略梯度奖励可被计算为所有有效动作序列的总和,可以使用一个无偏估计量来对它进行近似:
\[\begin{equation} J(\theta) = \sum_{y_{1:T} \in \mathbb Y^*} p_{\theta} (y_{1:T}) R(y_{1:T}) = \mathbb E_{y_{1:T} \sim p_{\theta}} \sum_{t=1}^T r(y_{1:t}) \end{equation}\]通过梯度最大化$J(\theta)$:
\[\begin{equation} \nabla_{\theta} J(\theta) = \mathbb E_{y_{1:T} \sim p_{\theta}} [\sum_{t=1}^T \nabla_{\theta} log p_{\theta} (y_{1:(t-1)})] \sum_{t=1}^T r(y_{1:t}) \end{equation}\]实际操作下,期望梯度可以近似为使用一个蒙特卡洛样本,可引入基线b 来降低梯度估计的方差,而不改变预期的梯度,单一取样的预期梯度近似等于:
\[\begin{equation} \nabla_{\theta} J(\theta) \approx \sum_{t=1}^T \nabla_{\theta} log p_{\theta} (y_{1:(t-1)}) \sum_{t=1}^T r(y_{1:t} - b_t) \end{equation}\]判别器作为奖励
判别器设置了两个,一个是判断诗歌和图像的相关性,另一个是判断诗歌长度、诗意和一致性,文章将其定义为多模态判别器和诗歌风格判别器。
多模态判别器:为了检查生成的诗歌y是否与输入图像x相匹配,我们训练多模态判别器$D_m$,来将 (x, y)分类成匹配、不匹配和生成三个类别。$D_m$ 包括一个多模态编码器、模态融合层以及一个有softmax函数的分类器:
\[\begin{equation} c = GRU_{\rho}(y) \\ f = tanh(W_x \cdot x + b_x) \odot tanh(W_c \cdot c + b_c) \\ C_m = softmax(W_m \cdot f + b_m) \end{equation}\]其中$W_x,b_x,W_c,b_c,W_m,b_m$是要学习的参数,而$C_m$代表多模态判别器的三种类型的概率,我们利用基于GRU的语句编码器来进行判别器训练, $c \in \lbrace paired,unpaired,generated \rbrace$。
诗歌风格判别器:与强调格律、韵律和其他传统诗歌技术的大部分诗歌生成研究不同,文章关注的是一种开放形式的诗歌——自由诗,但是也要求我们生成的诗歌具备诗意特点。 没有为诗歌指定具体的模板或规则,而是提出了诗歌风格判别器$D_p$,将生成的诗歌朝人类创作的诗歌方向进行引导。在$D_p$中,生成的诗歌会被分为四类:诗意的、无序的、段落的和生成的。 诗意类是满足诗意标准的正面例子,其他三类都被视为反面示例。无序类是关于诗句之间的内部结构和连贯性,而段落类则是使用了段落句子,而被当成反面示例。 在$D_p$中,将单模态诗集当做正面的诗意示例。为构建无序类别的诗歌,首先通过分割单模态诗集中的所有诗歌,建立了一个诗句池,再从诗句池中随机挑选合理行数的诗句, 重新构成诗歌,作为无序类的示例。
完整的生成诗歌y被GRU编码,并解析到完全连通层,然后使用softmax函数计算被归到四种类别的概率。此过程的公式如下:
\[\begin{equation} C_p = softmax(W_p \cdot GRU_{\eta}(y) + b_p) \end{equation}\]其中$\eta , W_p , b_p$是要学习的参数,其中$c \in \lbrace poetic,disordered,paragraphic,generated \rbrace$
奖励函数:将策略梯度的奖励函数定义为生成的诗歌y(根据输入图像x生成)被分类到正面类别(多模态判别器$D_m$的匹配类以及诗歌风格判别器$D_p$的诗意类) 的概率的线性组合,然后经过加权参数$\lambda$加权:
\[\begin{equation} R(y \vert \cdot) = \lambda C_m (c = paired \vert x, y) + (1 - \lambda)C_p (c = poetic \vert y) \end{equation}\]实验
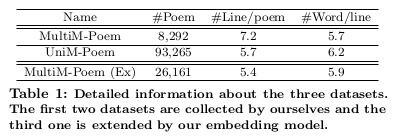
在数据集的选择下,文章选择了两个诗歌数据集,其中一个包含图像和诗歌对,即多模态诗歌数据集(MultiM-Poem),另一个是大型的诗歌语料库, 即单模态诗歌数据集(UniM-Poem)。第三个数据集通过VPE扩展而得,并构建了一个扩展的图像-诗歌对数据集,称为多模态诗集MultiM-Poem(EX), 这些数据集的详细信息如下表所示:
在比较方法的选取上,文章设计了:
1CNN:仅使用对象CNN,通过VGG-16对CNN-RNN模型进行了训练。
3CNNs:使用三个CNN特征,通过VGG-16对CNN-RNN模型进行了训练。
SeqGAN:使用一个判别器(用来分辨生成的诗歌和真人创作的诗歌的判别器)对CNN-RNN模型进行了优化。
区域层次:以文章为依据的层次段落生成模型。为了更好地与诗歌分布保持一致,我们在实验中将最大行数限制在10行,每行最大词数限制在10个。
此篇文章模型:为了证明两个判别器的有效性,在四个背景中训练我们的模型(使用GAN、I2P-GAN的图像到诗歌):无判别器的预训练模型(I2P-GAN w/o判别器)、 只有多模态判别器的训练模型(I2P-GAN w/ $D_m$)、有诗歌风格判别器的训练模型(I2P-GAN w/ $D_p$)以及有两个判别器的训练模型(I2P-GAN)。
在评估方法上,文章采用三种评价标准,BLEU、新颖性和相关性,然后在标准化后根据三种标准计算总分。
BLEU:首先使用双语互译质量评估辅助工具(BLEU) 基于分数的评价来检查生成的诗歌与真实诗歌有多近似,正如图像标题技术和图像生成短文研究通常所做的那样。它还被用于一些其他的诗歌生成研究中, 对于每张图片,仅使用人类创作的诗歌作为真实诗歌。
新颖性(Novelty):通过引入判别器$D_p$,生成器应从单模态诗歌数据集中引入单词或短语,并生成MultiM-Poem(EX)中不常出现的单词或短语。 使用文章提出的新颖性来计算生成诗歌中观察到的低频词语或短语。研究新颖性-2和新颖性-3这两种N-gram尺度(例如,二元模子和三元模子)。 首先对MultiM-Poem(EX)训练数据集中出现的n-gram进行排序,将前2,000作为高频。新颖性根据训练数据集中出现的n-grams比例进行计算(生成的诗歌中的高频n-grams除外)。
相关性(Relevance):不同于那些对诗歌内容无约束或约束较弱的诗歌生成研究,在本研究中将生成诗歌与给定图像之间的相关性视为一个重要标准。生成说明文字更关注对图像的事实描述, 与此不同的是,不同的诗歌可以在各种方面与同一幅图像相关。因此,没有计算生成诗歌与真实诗歌之间的相关性,使用经过学习的深度耦合的视觉诗意嵌入模型来确定诗歌和图像之间的相关性。 通过嵌入模型将图像和诗歌映射到相同空间后,使用余弦相似性来测量它们的相关性。尽管嵌入模型能够大概地量化图像和诗歌之间的相关性,还是使用了主观评价来更好地研究我们生成人类水平诗歌的有效性。
总览(Overall):最后根据以上三个标准来计算总分,对于一个标准a的所有值中的每个值$a_i$,使用以下方法将其归一化:
\[\begin{equation} a_i^, = \frac{a_i - min(a)}{max(a) - min(a)} \end{equation}\]看一下实验的对比结果:
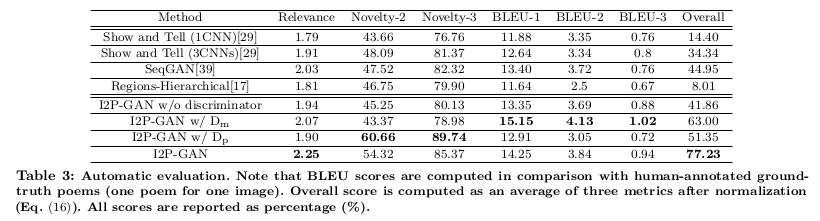
可以看到I2P-GAN的效果都在各个标准下取得了不错的效果。
为了进一步说明实验的效果,通过人工打分来评价诗歌的生成效果,在专业人士的打分下:

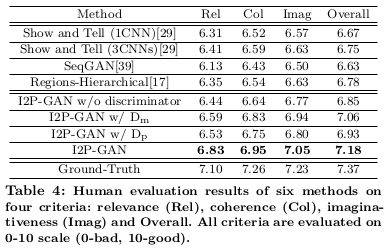
实验还将真假诗歌混合在一起,用人工做图灵测试:
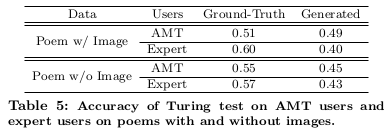
最后来看一下诗歌的具体生成效果:

总结
img2poem是图像生成诗歌(英文自由诗)的首个研究,文章使用多判别器作为策略梯度的奖励,通过整合深度耦合的视觉诗意嵌入模型和基于RNN的对抗训练, 提出了一种模拟问题的新方法。此外,引入了首个图像-诗歌对的数据集(MultiM-Poem)和大型诗歌语料库(UniM-Poem)来促进关于诗歌生成的研究, 特别是根据图像生成诗歌。大量的实验证明,嵌入模型能够近似地学习一个合理的视觉创意嵌入空间。
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







