SC-FEGAN人脸编辑(论文解读)
人脸编辑可以在大多数图像编辑软件上得到实现,但是这都需要专业知识,例如了解在特定情况下使用哪些特定工具,以便按照想要的方式有效地修改图像,同时操作图像编辑软件也是耗时的。基于深度学习下图像编辑得到越来越多的重视和应用,在GAN的推动下,图像风格转换、图像修复、图像翻译等等在近几年有了长足的发展。这篇文章将介绍基于GAN损失的端到端可训练生成网络,在人脸修复上取得了很棒的结果,同时该模型也适用于有趣的人脸编辑。
论文引入
提到图像编辑,一定要说的就是Photoshop这款软件,近乎可以处理日常所有的照片,但是PS不是这么容易操作的,精通PS更是需要专业知识了。如何让小白完成在图像上勾勾画画就能实现图像的编辑?这个任务当然可以交给深度学习来实现了。
生成对抗网络(GAN)的发展,促进了图像生成下一系列研究的发展。图像编辑下图像修复是一个难点,这对于图像编辑软件来说也是很困难的。近几年在深度学习发展下,图像修复在不断进步,最典型的方法是使用普通(方形)掩模,然后用编码器-解码器恢复掩蔽区域,再使用全局和局部判别器来估计结果的真假。然而,该系统限于低分辨率图像,并且所生成的图像在掩蔽区域的边缘不能很好的与原图衔接。尽管Deepfillv2[1]、GuidedInpating[2]、Ideepcolor[3]、FaceShop[4]在不断改进实现结果,但是对于深度学习处理图像修复上的难点还是依旧存在,总的来说主要的挑战有两个。1.图像在恢复的部分上具有不和谐的边缘 2.如果图像太多区域被覆盖,修复的图像将会不合理。
本文要解读的论文SC-FEGAN: Face Editing Generative Adversarial Network with User’s Sketch and Color[5]为了解决上述限制,提出了SC-FEGAN,它具有完全卷积网络,可以进行端到端的训练。提出的网络使用SN-patchGAN[1]判别器来解决和改善不和谐的边缘。该系统不仅具有一般的GAN损失,而且还具有风格损失,即使在大面积缺失的情况下也可以编辑面部图像的各个部分。这篇论文发布在arxiv不到10天,其源码便已标星破千。文章的人脸编辑效果十分逼真,先一睹为快。
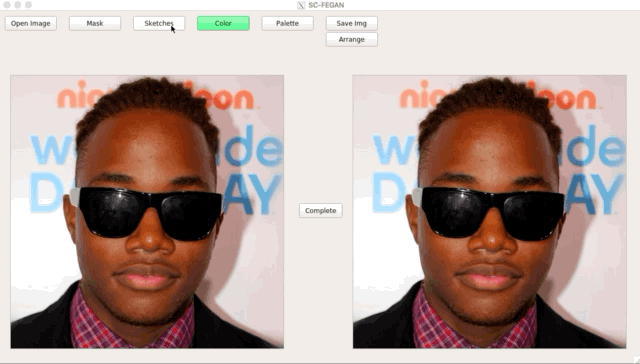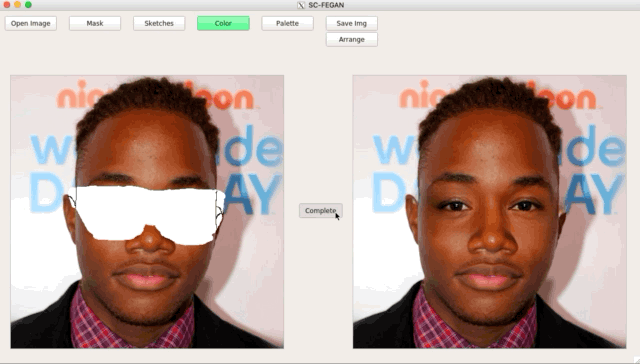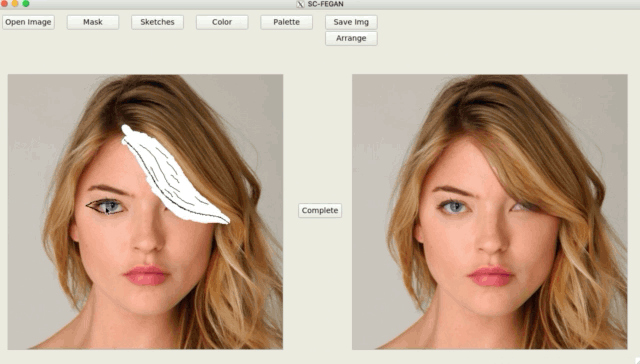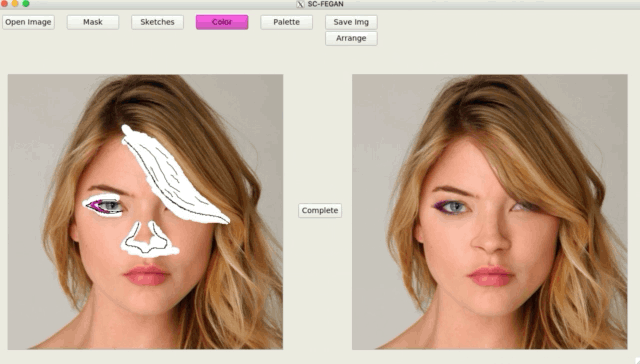
总结一下SC-FEGAN的贡献:
- 使用类似于U-Net[6]的网络体系结构,以及gated convolutional layers[1]。对于训练和测试阶段,这种架构更容易,更快捷,与粗糙网络相比,它产生了优越而细致的结果。
- 创建了解码图,颜色图和草图的自由格式域数据,该数据可以处理不完整图像数据输入而不是刻板形式输入。
- 应用了SN-patchGAN判别器,并对模型进行了额外的风格损失。该模型适应于擦除大部分的情况,并且在管理掩模边缘时表现出稳健性。它还允许生成图像的细节,例如高质量的合成发型和耳环。
训练数据处理
决定模型训练好坏的一个重要因素就是训练数据的处理,SC-FEGAN采用CelebA-HQ[7]数据集,并将图片统一处理为512x512大小。
为了突显面部图像中眼睛的复杂性,文章使用基于眼睛位置掩模来训练网络。这主要用在掩码的提取上,当对面部图像进行训练时,随机应用一个以眼睛位置为起点的free-form mask,以表达眼睛的复杂部分。此外,文章还使用GFC随机添加了人脸头发的轮廓。算法如下:

文章的又一个创新是在提取图像的草图和颜色图,使用HED边缘检测器[8]生成与用户输入相对应的草图数据,之后,平滑曲线并擦除了小边缘。创建颜色域数据,首先通过应用大小为3的中值滤波,然后应用双边滤波器来创建模糊图像。之后,使用GFC[9]对面部进行分割,并将每个分割的部分替换为相应部分的中间颜色。最后还提取噪声表示。最终处理完得到的数据可由下图展示,上面一行作为真实标准,下面一行为处理得到的输入数据。

模型结构
SC-FEGAN采用的网络设计结构与U-Net类似,上采样的思路是U-Net的那一套,通过Concat连接下采样的特征提取完成上采样,整体框架如下所示:
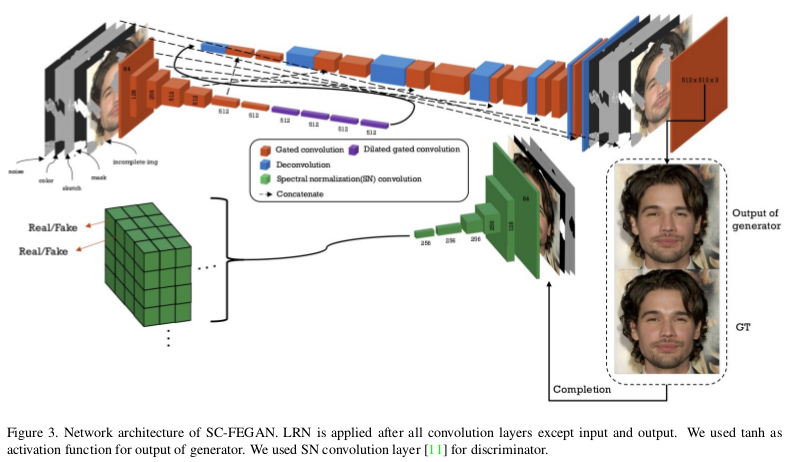
网络的整体很好理解,图示也很清晰,我们强调一下网络的输入。
不像传统的图像到图像的模型输入是512x512x3的RGB输入,这篇论文的输入是尺寸为512×512×9的张量,这个张量是由5张图片图片构成的。首先是被覆盖残缺的RGB图像,也就是我们在图片上勾勾画画的图像,其尺寸为512x512x3;其次是提取得到的草图512x512x1;图像的颜色域RGB图512x512x3;掩码图512x512x1;最后就是噪声对应的512x512x1。按照通道连接的话得到最终的模型输入512x512x9。
卷积层采用的是gated convolution,使用3x3内核,下采样采取2个步幅内核卷积对输入进行7次下采样,上采样通过U-Net思路进行解码得到编辑好的图像。解码得到的图像依旧是5张图片,包括修复的RGB图像、草图、颜色图、掩码图、噪声图。通过判别器和真实的5张图片进行SN-patchGAN结构设计进行真假判断,优化模型。
在整个网络的卷积层后应用局部信号归一化(LRN),生成器采用Leaky Relu,判别器通过SN限制,并且施加梯度惩罚。SC-FEGAN的损失函数由5部分组成,像素损失$L_{per-pixel}、感知损失L_{percept}$、风格损失$L_{style}$、总方差损失$L_{tv}$以及GAN的对抗损失。
先来看一下GAN的对抗损失,文章采用的WGAN的损失设计:
\[L_{G_{SN}} = - \mathbb E[D(I_{comp})]\] \[L_D = \mathbb E[1 - D(I_{gt})] + \mathbb E[1 + D(I_{comp})] + \theta L_{GP}\]其中$I_{comp}$是生成器输出的$I_{gen}$的完成图像(包括草图和颜色图以后的),也就是送入判别器判别的输入,最后判别器加上梯度惩罚项。对于生成器希望判别器判错,故生成器损失最小值为-1,判别器则希望真实判为真,生成判为假,上述损失还是很好理解的。生成器完整的损失为:
\[L_{G} = L_{per-pixel} + \sigma L_{percept} + \beta L_{G_{SN}} + \gamma (L_{style}(I_{gen}) + L_{style}(I_{comp})) + vL_{tv} + \epsilon \mathbb E[D(I_{gt})^2]\]像素损失保证图像编辑生成与真实的一致性:
\[L_{per-pixel} = \frac{1}{N_{I_{gt}}} \Vert M \odot (I_{gen} - I_{gt}) \Vert_1 + \alpha \frac{1}{N_{I_{gt}}} \Vert (1 - M) \odot (I_{gen} - I_{gt}) \Vert_1\]其中$N_a$是特征$a$的数字元素,M是二元掩模图,用于控制修复图像的像素,达到生成与真实的一致性。公式后一项给予擦除部分损失更多的权重。对于大区域下的擦除图像的修复时,风格损失和感知损失是必要的。感知损失在GAN中的应用已经很多了,就是对中间层进行特征差异损失,这里不做赘述。
风格损失使用Gram矩阵比较两个图像的内容,风格损失表示为:
\[L_{style}(I) = \sum_q \frac{1}{C_qC_q} \Vert \frac{G_q(I) - G_q(I_{gt})}{N_q} \Vert_1\]其中,$G_q(x) = (\Theta_q(x))^T(\Theta - q(x))$,$\Theta$为网络的中间层,$G_q(x)$是用于在中间的每个特征图上执行自相关的Gram矩阵,Gram矩阵的形状是$C_q \times C_q$。总方差损失,反应的是相邻像素间是相似的,记为$L_{tv} = L_{tv-col} + L_{tv-row}$。其中:
\[L_{tv-col} = \sum_{(i,j) \in R} \frac{\Vert I_{comp}^{i,j+1} - I_{comp}^{i,j} \Vert_1}{N_{comp}}\]对于列row也是一样,自此整体的损失函数构建完成,在实际实验中参数设置为,$\sigma = 0.05,\beta = 0.001,\gamma = 120,v=0.1,\epsilon = 0.001, \theta = 10$。
实验
实验首先对比了使用U-Net框架设计的优势,对比的框架是Coarse-Refined。论文测试了Coarse-Refined结构网络,并注意在一些需要精确输出的却是模糊的。

FaceShop已经显示出难以修改像整个头发区域那样的巨大擦除图像。由于感知和风格损失的加入,SC-FEGAN在这方面表现更好。下图显示了有和没有VGG损失(感知和风格损失)的结果。

实验还与最近的研究Deepfillv1进行了比较,下图显示模型在使用自由形状的掩模在结构和形状的质量方面产生更好的结果。意味着没有附加信息,如草图和颜色,面部元素的形状和位置具有一定的依赖值。因此,只需提供附加信息即可在所需方向上恢复图像。此外,即使输入图像被完全擦除,我们的SC-FEGAN也可以生成仅具有草图和颜色自由形式输入的人脸图像(感兴趣的可以参看论文中更多结果)。

下图显示了草图和颜色输入的各种结果,它表明模型允许用户直观地编辑脸部图像功能,如发型,脸型,眼睛,嘴巴等。即使整个头发区域被删除,它也能够产生适当的结果。

文章还做了给人物加上耳环的有趣实验,这种人脸编辑确实蛮有意思:

总结
SC-FEGAN提出了一种新颖的图像编辑系统,用于自由形式的蒙版,草图,颜色输入,它基于具有新颖GAN损失的端到端可训练生成网络。与其他研究相比,网络架构和损失功能显着改善了修复效果。论文基于celebA-HQ数据集进行了高分辨率图像的训练,并在许多情况下显示了各种成功和逼真的编辑结果。实验证明了系统能够一次性修改和恢复大区域,并且只需要用户细致的勾画就可以产生高质量和逼真的结果。
模型的框架采用U-Net思想,在Decoder端结合Encoder端特征实现上采样过程下精确图像的生成。引入感知损失和风格损失更是帮助模型实现了大区域擦除的修复。在判别器采用SN-patchGAN思想,使得恢复的图像在边缘上更加和谐,生成器和判别器都结合了图像的草图、颜色图和掩模图进行判断,使得修复的图像更加逼真,同时也是论文的一个创新。实验上的炫彩也是使得源码得到了广泛的关注。
参考文献
[1] J. Yu, Z. Lin, J. Yang, X. Shen, X. Lu, and T. S. Huang.Free-form image inpainting with gated convolution. arXiv preprint arXiv:1806.03589, 2018. 2, 3, 4, 6, 7
[2] Y. Zhao, B. Price, S. Cohen, and D. Gurari. Guided image inpainting: Replacing an image region by pulling content from another image. arXiv preprint arXiv:1803.08435, 2018. 2
[3] R. Zhang, J.-Y. Zhu, P. Isola, X. Geng, A. S. Lin, T. Yu, and A. A. Efros. Real-time user-guided image colorization with learned deep priors. arXiv preprint arXiv:1705.02999, 2017.2, 3
[4] T. Portenier, Q. Hu, A. Szabo, S. Bigdeli, P. Favaro, and M. Zwicker. Faceshop: Deep sketch-based face image editing. arXiv preprint arXiv:1804.08972, 2018. 2, 3, 4, 6, 7
[5] Jo Y, Park J. SC-FEGAN: Face Editing Generative Adversarial Network with User’s Sketch and Color[J]. arXiv preprint arXiv:1902.06838, 2019.
[6] O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing andcomputer-assisted intervention, pages 234–241. Springer,2015. 2, 3, 4
[7] T. Karras, T. Aila, S. Laine, and J. Lehtinen. Progressive growing of gans for improved quality, stability, and variation.arXiv preprint arXiv:1710.10196, 2017. 3, 4
[8] S. ”Xie and Z. Tu. Holistically-nested edge detection. In Proceedings of IEEE International Conference on Computer Vision, 2015. 3
[9] Y. Li, S. Liu, J. Yang, and M.-H. Yang. Generative face completion. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), volume 1, page 3, 2017. 1,3, 4

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







