SAGAN论文解读
Attention首次引入GAN是在AttnGAN论文中,主要是增强了文本到图像的细粒度生成上。AttnGAN的网络搭建相对庞大, 但是将Attention引入到GAN网络中已经是相当有开创意义的了。最近一篇基于Self-Attention在GAN中应用的论文将Self-Attention作为一个网络模块在GAN中使用, 大大缩小了网络复杂度,并且取得了不俗的效果。在ImageNet上实现了一个突破,这篇文章就是Self-Attention Generative Adversarial Networks 简称为SAGAN,这篇文章GAN的原作者Ian Goodfellow作为第二作者。
论文引入
图像的生成一直是计算机视觉中一个很重要的方向,近期GAN和VAE的发展大大加速了图像生成的步伐。尤其是GAN利用对抗的思想并且通过深度卷积网络的实现, 可以在图像生成上得到不错的效果。但是在一些自然图像的生成效果上不尽如人意,例如我们熟悉的ImageNet数据集,如果放在GAN中去训练让其生成对应的图像, 我们试验后会发现生成的图像质量并不高,图像往往是“扭曲变形”的,例如我们生成ImageNet中狗这一类的图像,得到的结果是这样的。

SAGAN论文中给出的解释是GAN擅长合成几乎没有结构约束的图像类别,例如海洋、天空和景观类别。但是无法捕获在某些类别中始终如一地出现的几何或结构模式, 例如狗的毛皮。这种原因并不是GAN自身带来的,而是以前的GAN模型在很大程度上依赖于卷积来模拟不同图像区域之间的依赖关系。由于卷积运算过程中, 是基于一个局部感受域,所以只能在经过几个卷积层之后才能处理图像中远距离的相关性。这种学习长期相关性问题上,在卷积网络下可能无法表示它们, 因为在模型优化阶段捕获多个层相关性参数是不容易的,并且这些参数化可能是统计学上的,这就带来了一定的问题。增加卷积核的大小可以增加网络的表示能力, 但这样做也会失去使用本地卷积结构获得的计算和统计效率。
Self-Attention的概念在Attention is All You Need中提出,只是文章的应用是在机器翻译上, 文中指出引入自我注意机制可以很好的学习到序列的依赖关系,从全局上去分析序列。Non-local Neureal Networks 一文将Self-Attention应用在了视频分类上,但是是在图像的基础上展开的,文章通过实验和推导说明了Self-Attention对于图像前后依赖关系上是有很大意义的。 同时在单幅图像中可以很好地学习到图像的全局特征。这一点就是SAGAN作者将Self-Attention应用在GAN的意义,文中指出Self-Attention在模拟远距离依赖的能力与计算和统计效率之间表现出更好的平衡。 同时Self-Attention计算一个位置处的响应作为所有位置上的特征加权,大大缩小了计算成本。我们从下图看看Self-Attention的作用:

上图中在每一行的第一图像显示具有彩色编码点的五个代表性查询位置。其他五个图像是针对这些查询位置的关注图,其中对应的颜色编码的箭头总结了最多处理的区域。 这说明SAGAN通过利用图像的远距离部分中的互补特征而不是固定形状的局部区域来生成图像以生成一致的对象/场景。
自我注意(Self-Attention)引入到卷积GAN中是对卷积的补充,有助于模拟跨越图像区域的长距离,多级别依赖关系。在Self-Attention作用下发生器在生成图像过程中, 可以对每个位置的精细细节都与图像远处的精细细节进行仔细协调。此外,判别器还可以更准确地对全局图像结构执行复杂的几何约束。SAGAN论文中还将2018年新提出的谱归一化 (spectral normalization)应用在图像生成过程中,对生成过程做良性调节。 SAGAN在ImageNet实验结果上Inception scroe从36.8提高到52.52,这是个很大的提高了。
总结一下SAGAN的贡献:
- 将Self-Attention引入到GAN中,提高了图像生成过程中远距离依赖和几何特性的描述。
- 将spectral normalization补充到实验中实现了更好的生成效果。
SAGAN模型介绍
SAGAN模型的整体框架和GAN是一样的,仅仅是由一个生成器和一个判别器组成,只是在生成器和判别器网络设计的内部加入了Self-Attention层, 如果对Non-local Neureal Networks一文很熟悉的话,SAGAN中的Self-Attention层可以说就是将Non-local Neureal Networks一文中的Self-Attention 实现过程中的Dot product直接拿过来的,实现框架如下图。
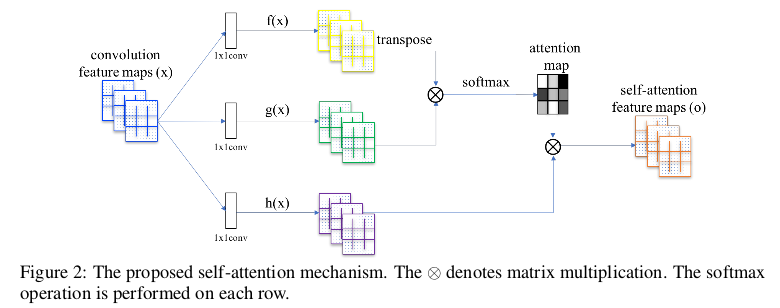
我们可以用下图来真正的理解Self-Attention的实现。
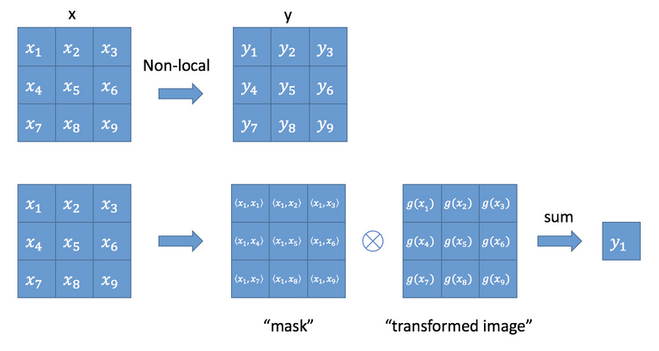
其中\(y_i\)可以表示为\(y_i = \frac{1}{C(x)} \sum_{\forall j}f(x_i,x_j)g(x_j)\),\(i\)为输出位置,\(j\)为参与运算位置,\(C(x)\)为归一化参量, \(f(x_i,x_j)\)表示向量\(x_i\)与\(x_j\)的相似关系函数,\(g(x_j)\)为\(x_j\)处的特征,这里的\(y_i\)就是上述图像表达的含义。以\(y_1\) 为例,\(y_1\)就是\(x_1\)与\(x_j\)遍历求得相似性后得到的全局输出。Non-local Neureal Networks一文给出了好几种相似性度量函数\(f(x_i,x_j)\) 如Gaussian,Embededed Gaussian,Dot product, Concatenation。
为了实现这个过程,简单的for循环处理肯定是效率很低的,可以将整个non-local化为矩阵乘法运算+卷积运算这个就是上面我们给出的SAGAN中Self-Attention 的实现框架。下面是Non-local Neureal Networks一文中给出的实现框架,是不是感觉和SAGAN中给出的是差不多的。
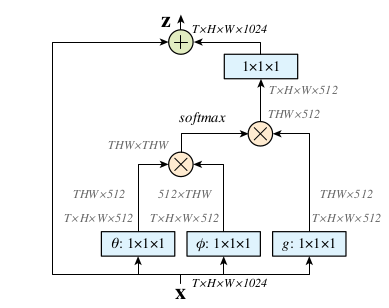
SAGAN中将\(\theta ,\phi, g\)换成了\(f(x),g(x)和h(x)\)。
损失函数和模型训练
SAGAN模型完全可以用最传统的GAN的损失函数来训练,但是文中使用了hinge损失函数作为GAN的优化损失, 损失函数为:
\[L_D = -E_{(x,y)\sim p_{data}}[min(0, -1+D(x,y))] - E_{z\sim p_{z},y\sim p_{data}}[min(0, -1-D(G(z),y))]\] \[L_G = -E_{z\sim p_{z},y\sim p_{data}}D(G(z),y)\]在模型训练的技巧上,文中主要突出两点说明:
1.谱归一化的使用,谱归一化限制了每个曾的谱范数来约束判别器的Lipschitz常数,详细请参见spectral normalization一文。
2.不平衡学习率的设定,对于G和D的训练稳定性一直是GAN训练需要考虑的,不平衡的学习率往往可以是训练更加的稳定。
SAGAN实验
为了说明使用这两个技巧带来的作用,文中以实验结果加以说明:
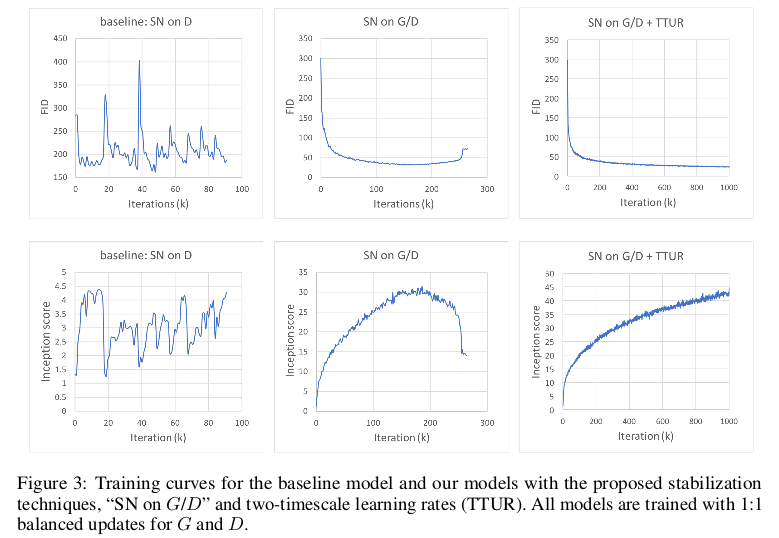
实验结果表明,使用了谱归一化和不平衡学习率在实验的收敛和稳定性以及实验结果上都有所提高。
为了进一步说明训练技巧的重要性,文中又从实验生成的图像质量上展示:

最后就是引入Self-Attention后的实验提升:
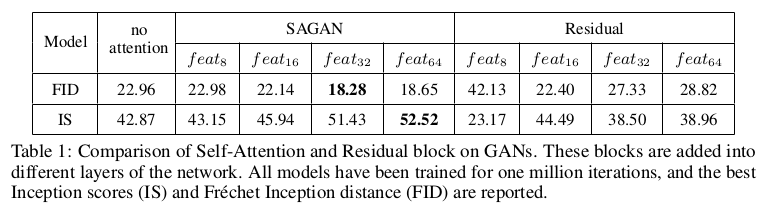
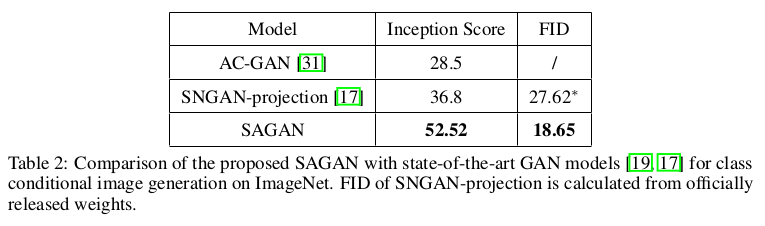
在实验结果可以看出,SAGAN在Inception score和FID上都达到了目前最好的水平,并且大大提升一个层次。
最后看一下SAGAN生成的炫酷图像:

总结
SAGAN将Self-Attention引入到GAN中,在图像生成的全局性上和图像的几何结构上更加的合理,大大提升了GAN图像生成的能力。利用谱归一化和不平衡学习率的训练技巧, 使得GAN的训练更加地稳定生成质量更加好,在ImageNet数据集上的生成有了很大的提高。SAGAN的作者也公布了实验代码,下文将附出。 代码我是有亲自跑过,在ImageNet数据集上挑选了几个类别来实验,确实比之前的GAN模型的效果要好,但是还有很大的提升空间。
参考文献
[1] Zhang H, Goodfellow I, Metaxas D, et al. Self-Attention Generative Adversarial Networks[J]. arXiv preprint arXiv:1805.08318, 2018.
[2] T. Miyato, T. Kataoka, M. Koyama, and Y. Yoshida. Spectral normalization for generative adversarial networks. In ICLR, 2018.
[3] X. Wang, R. Girshick, A. Gupta, and K. He. Non-local neural networks. In CVPR, 2018.
[4] J. H. Lim and J. C. Ye. Geometric gan. arXiv:1705.02894, 2017.
[5] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need. arXiv:1706.03762, 2017.
[6] Xu T, Zhang P, Huang Q, et al. AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks[J]. 2017.
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







