BicycleGAN论文解读
BicycleGAN(Toward Multimodal Image-to-Image Translation)是来自伯克利大学的又一图像风格变换生成的作品。 在此之前本篇文章作者朱俊彦是图像处理工具CycleGAN、pix2pix、iGAN的主要开发者。BicycleGAN在图像变换生成的基础上实现了多类风格的生成, 比如给出一张鞋的草图在保持确定的前提下,生成出各式各样不同纹理风格的图像。
我们先来看看文章最终实现的实验结果,我们再向下分析:

正如我们看到的实验结果,在输入固定的情况下,BicycleGAN可以实现多种风格图片的一次性生成出来。实验结果看起来还是满炫酷的, 不知这些实验结果会不会给设计师在一些设计作品中提供一些灵感。
引入
图像到图像的多风格的生成的意义是可以想象的,我们直接利用文章的摘要来引入这篇文章。
很多图像到图像的转换方法是带有歧义的,因为单个输入图像可能对应于多个可能的输出。BicycleGAN的目标是在条件生成建模设置下对可能的输出分布进行建模。 映射的模糊性是在潜在的低维向量中进行的,因此可以在测试时随机抽样。在生成器学习时,将给定的输入与隐编码结合起来并映射到输出,且输出和隐编码之间的联系是可逆的。 这有助于防止在训练期间从隐编码到输出之间形成多对一映射(也称为模式崩溃问题),导致产生更多不同的结果。文章通过利用不同的训练目标、不同的网络结构和不同的隐编码注入方式, 来探索这种方法的几种不同的变体。文章提出的方法激励隐编码和输出模式之间的双射一致性(bijective consistency),所以文章称之为BicycleGAN。
文章结合了VAE—GAN的思想,我之前也有介绍过VAE-GAN可以移至这里详细查看。 文章创新在于提出了cLR-GAN(Conditional Latent Regressor GAN),我们看看文章是如何描述的。
-cVAE-GAN(条件变分自编码GAN):是一种通过VAEs学习输出的隐编码分布,进而建模多模式输出分布的方法。在条件设置(类似于无条件模拟)中, 通过强制将期望输出图像的隐编码分布反映射到条件生成器得到的输出上。利用KL散度对潜在分布进行正则化,使其接近标准正态分布,从而在推理过程中对随机编码进行采样。 然后将这个变分目标与判别器损失一起优化。
-cLR-GAN(条件潜在回归GAN):在隐编码中进行模式捕获的另一种方法是显式建模逆映射。从随机抽样的隐编码开始,条件生成器应该产生一个输出, 当它作为输入给编码器时,它应该返回相同的隐编码,从而实现自我一致性。这种方法可以看作是“latent regressor”模型的条件表达形式,也与InfoGAN相关。
-BicycleGAN:最后,结合这两种方法来联合执行隐编码和双向输出之间的连接,并实现性能的改进。文中的方法可以在很多图像到图像的转换问题上产生多样的和视觉上吸引人的结果, 比其他基准方法更多样化,包括在pix2pix框架中增加噪声的任务。除了损失函数之外,文中还研究了几种网络编码器的性能,以及将隐编码注入生成器网络的不同方式。
到这里是不是对BicycleGAN有了初步的了解,其实文章最关键的就是在latent z的控制,接下来我们一起来看看模型的实现。
BicycleGAN模型介绍
我们还是通过网络模型结构来分析模型的整体吧。
上图就是网络的模型整体,其中A是指我们的输入图片,对应到鞋子的那个例子的话,A就是我们输入的鞋子的草图,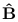 就是网络的输出图,
也就是由鞋子草图生成出来的各种不同纹理的鞋子图片,B就是真实训练中的鞋子纹理图。其中KL,L1,D是各类损失函数,KL指的就是KL损失函数,其他两个类似。
N(z)是指我们指定的数据分布,可以是高斯分布或者均匀分布,其他的结果我相信大家都是理解的,我就不啰嗦重复了。
就是网络的输出图,
也就是由鞋子草图生成出来的各种不同纹理的鞋子图片,B就是真实训练中的鞋子纹理图。其中KL,L1,D是各类损失函数,KL指的就是KL损失函数,其他两个类似。
N(z)是指我们指定的数据分布,可以是高斯分布或者均匀分布,其他的结果我相信大家都是理解的,我就不啰嗦重复了。
对于BicycleGAN的训练上,网络的整体结构是这样的:
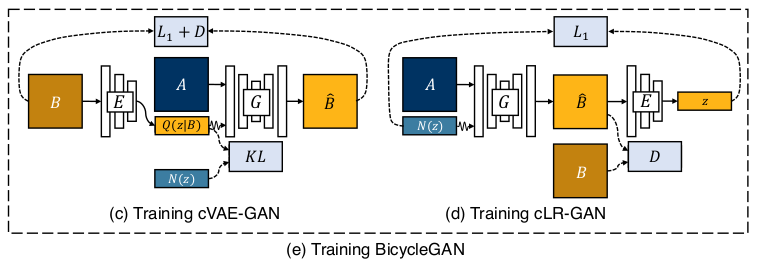
可以分为两块来理解,第一块就是cVAE-GAN的训练,我们分析的基础就是鞋子纹理风格生成为例。
鞋子纹理图片经过编码器得到编码后的latent z通过KL距离将其拉向我们事先定义好的分布N(z)上,将服从分布的z与鞋子草图A结合后送入生成器G中得到重构的鞋子纹理图。
此时为了衡量重构和真实的误差,这里用了L1损失和GAN的对抗思想实现,我们在后面损失函数分析部分再说。这样cVAE-GAN部分就可以训练了。
另一块就是cLR-GAN的训练,将鞋子草图A和分布N(z)结合经过生成器G得到鞋子纹理图,
再通过对生成的纹理图编码后得到的z去趋近分布N(z)来反向矫正生成图,达到一个变相的循环。
当这两部分训练的很好时,这个就是我们需要的BicycleGAN了,在检验训练效果时我们只需要,输入A加上N(z)就可以生成鞋子的纹理图了, 这个N(z)具体为什么怎么取将决定生成为纹理的风格了。
这里有一个小trike就是z和图片A的结合送入生成器G的结合方法,文中给出了两种方法:一种直接concat在input的channel上,一种Unet在压缩的时候,每次结果都加。 我们通过图解可以更好理解。
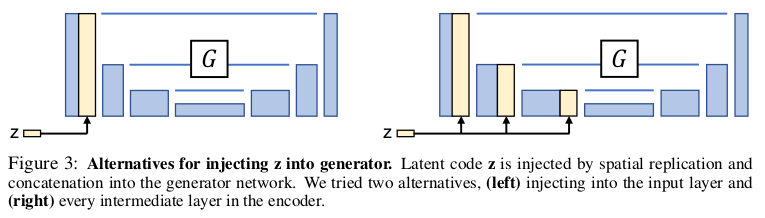
模型损失函数分析
模型搭好了,我们一起来看看具体的损失函数设计吧,文中也是按照分块展示损失函数的,我们按照文章的思路来:
1.首先是最基础的,草图加噪声得到纹理图的损失:
这一部分实现由L1损失和GAN两部分组成,L1损失可以体现重构后的图像轮廓,GAN的引入更好的锐化了图像的清晰度。
GAN这一块是:
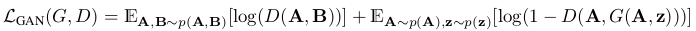
L1损失为:
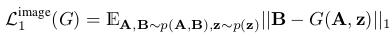
两者结合可以记为:
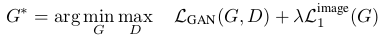
2.Conditional Variational Autoencoder GAN:cVAE-GAN (B → z → )的过程中涉及到的损失设计:
这一块我们紧跟上图模型图提及的几个损失,第一就是KL损失拉近编码后的z与事先准备分布N(z)的距离,重构图像的L1损失和GAN对抗损失。
KL损失:
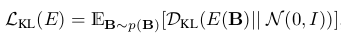
其中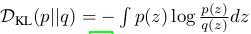
GAN这一部分的损失:
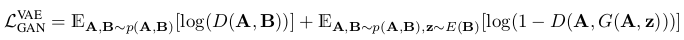
整体的一个损失可以记做:
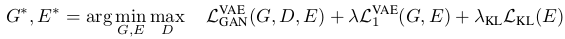
3.Conditional Latent Regressor GAN: cLR-GAN (z → → 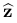 )
)
这一部分就是GAN和z的反向矫正,对于z的矫正采用L1损失:
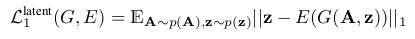
这一块的整合为:
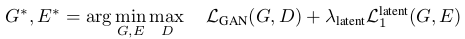
4.最后就是把所有的损失整合起来训练:
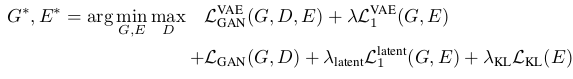
在程序中实现的时候,一个loss就搞定了,只不过各部分的参数更新要对应相应的网络了。
到这里整个模型就交代清楚了,我们一起来看看实验吧。
BicycleGAN实验
这篇文章作者已经公布代码了,原始代码为pytorch版本的,项目地址在这里,我做实验是在tensorflow基础上完成的, 所以我参考的是其他人复现的tensorflow版本的,项目地址在这里。
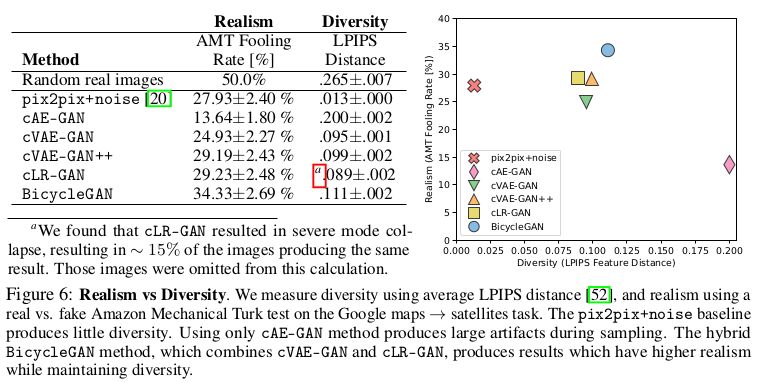
实验的结果我们在开头就已经贴上了一部分了,我们说一下试验中实现的对生成结果的真实度和多样性的衡量,看实验描述:
对于encoder的网络选择,z和A的结合方式的选择,实验也说明了:

最后,对于这个先验分布N(z)的维度选择和效果,实验展示了选择不同带来的实验效果:

在实际的程序运行上我们可以通过控制z的分布形式,生成多风格的图片。
当z为Random情况下:

当z的第一维为线性时候:

总结
文章通过对latent z的控制实现了多风格图片的生成,在图像到图像的转换上又提供了一个不错的指导作用。
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







