SSD简析(转)
SSD是YOLO之后又一个引人注目的目标检测结构,它沿用了YOLO中直接回归 bbox和分类概率的方法,同时又参考了Faster R-CNN,大量使用anchor来提升识别准确度。 通过把这两种结构相结合,SSD保持了很高的识别速度,还能把mAP提升到较高的水平。原博客在这里。
一、基本结构与原理
原作者给了两种SSD结构,SSD 300和SSD 512,用于不同输入尺寸的图像识别。本文中以SSD 300为例,图1上半部分就是SSD 300,下半部分是YOLO, 可以对比来看。SSD 300中输入图像的大小是300x300,特征提取部分使用了VGG16的卷积层,并将VGG16的两个全连接层转换成了普通的卷积层(图中conv6和conv7), 之后又接了多个卷积(conv8_1,conv8_2,conv9_1,conv9_2,conv10_1,conv10_2),最后用一个Global Average Pool来变成1x1的输出(conv11_2)。
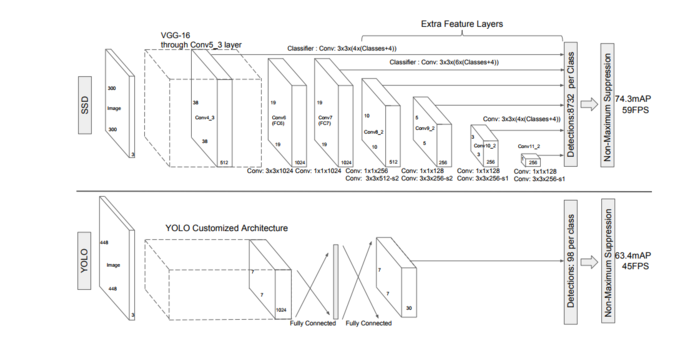
图1.SSD 300和YOLO的结构对比
1、SSD同时使用多个卷积层的输出来做分类和位置回归:
从图1可以看到YOLO只使用了最后一层的7x7数据来做回归,而SSD将conv4_3、conv7、conv8_2、conv9_2、conv10_2、conv11_2都连接到了最后的检测、分类层做回归。SSD这么做有什么好处呢? 要回答这个问题得先回顾下YOLO的结构,YOLO在训练时ground truth和bbox是一一对应的关系(ground truth对应到其中心位置所在区域中IOU最大的那个bbox来计算loss), 如果有两个ground truth的尺寸和位置都比较相近,就很有可能对应到同一个区域的同一个bbox,这种场景下必然会有一个目标无法识别。为了解决这个问题SSD的作者把YOLO的结构做了如下优化:
a、重新启用了Faster R-CNN中anchor的结构
在SSD中如果有多个ground truth,每个anchor(原文中称作default box,取名不同而已)会选择对应到IOU最大的那个ground truth。一个anchor只会对应一个ground truth, 但一个ground truth都可以对应到大量anchor,这样无论两个ground truth靠的有多近,都不会出现YOLO中bbox冲突的情况。
b、同时使用多个层级上的anchor来进行回归
作者认为仅仅靠同一层上的多个anchor来回归,还远远不够。因为有很大可能这层上所有anchor的IOU都比较小,就是说所有anchor离ground truth都比较远, 用这种anchor来训练误差会很大。例如图2中,左边较低的层级因为feature map尺寸比较大,anchor覆盖的范围就比较小,远小于ground truth的尺寸, 所以这层上所有anchor对应的IOU都比较小;右边较高的层级因为feature map尺寸比较小,anchor覆盖的范围就比较大,远超过ground truth的尺寸, 所以IOU也同样比较小;只有图2中间的anchor才有较大的IOU。通过同时对多个层级上的anchor计算IOU,就能找到与ground truth的尺寸、 位置最接近(即IOU最大)的一批anchor,在训练时也就能达到最好的准确度。
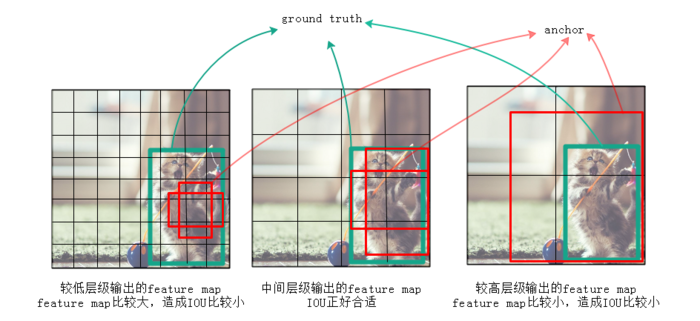
图2.不同层级输出的feature map上anchor的IOU差异会比较大
2、anchor尺寸的选择:
下面来看下SSD选择anchor的方法。首先每个点都会有一大一小两个正方形的anchor,小方形的边长用min_size来表示, 大方形的边长用sqrt(min_size*max_size)来表示(min_size与max_size的值每一层都不同)。同时还有多个长方形的anchor,长方形anchor的数目在不同层级会有差异, 他们的长宽可以用下面的公式来表达,ratio的数目就决定了某层上每一个点对应的长方形anchor的数目:
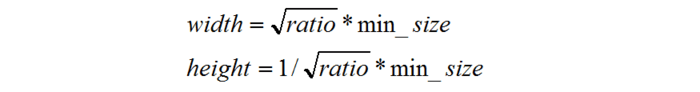
公式1
上面的min_size和max_size由公式2计算得到,Smin=0.2,Smax=0.95,m代表全部用于回归的层数,比如在SSD 300中m就是6。第k层的min_size=Sk,第k层的max_size=Sk+1
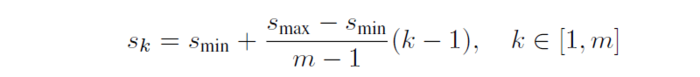
公式2
注:以上是作者论文中给的计算各层anchor尺寸的方法,但在作者源码中给的计算anchor方法有点差异,没有和论文的方法完全对应上。
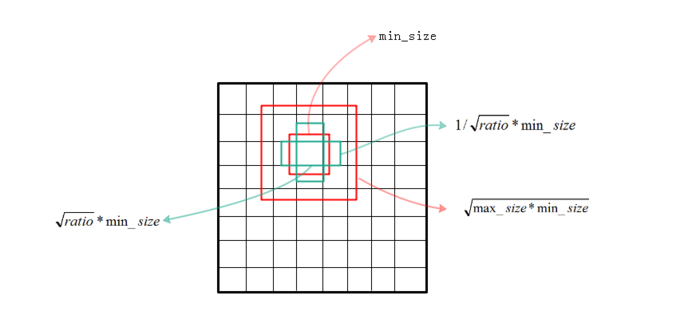
图3.anchor的尺寸的选择
3、loss的计算:
SSD包含三部分的loss:前景分类的loss、背景分类的loss、位置回归的loss。计算公式如下:
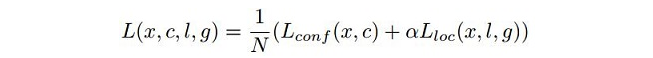
公式3
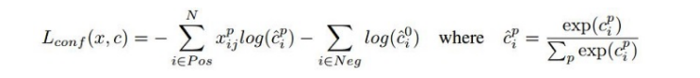
公式4
公式3中Lconf (x,c)是前景的分类loss和背景的分类loss的和,Lloc (x,l,g)是所有用于前景分类的anchor的位置坐标的回归loss。
公式里的N表示被选择用作前景分类的anchor的数目,在源码中把IOU>0.5的anchor都用于前景分类,在IOU<0.5的anchor中选择部分用作背景分类。
只选择部分的原因是背景anchor的数目一般远远大于前景anchor,如果都选为背景,就会弱化前景loss的值,造成定位不准确。
在作者源码中背景分类的anchor数目定为前景分类anchor数的三倍来保持它们的平衡。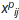 是第i个anchor对第j个ground truth的分类值,
不是1就是0。Lloc (x,l,g)位置回归仍采用Smooth L1方法, 有不了解的可以去百度下,其中的α是前景loss和背景loss的调节比例,论文中α=1。
整个loss的选取如下图,这只是个示意图,每个点的anchor被定死成了6个来方便演示,实际应用时不同层级是不一样的:
是第i个anchor对第j个ground truth的分类值,
不是1就是0。Lloc (x,l,g)位置回归仍采用Smooth L1方法, 有不了解的可以去百度下,其中的α是前景loss和背景loss的调节比例,论文中α=1。
整个loss的选取如下图,这只是个示意图,每个点的anchor被定死成了6个来方便演示,实际应用时不同层级是不一样的:
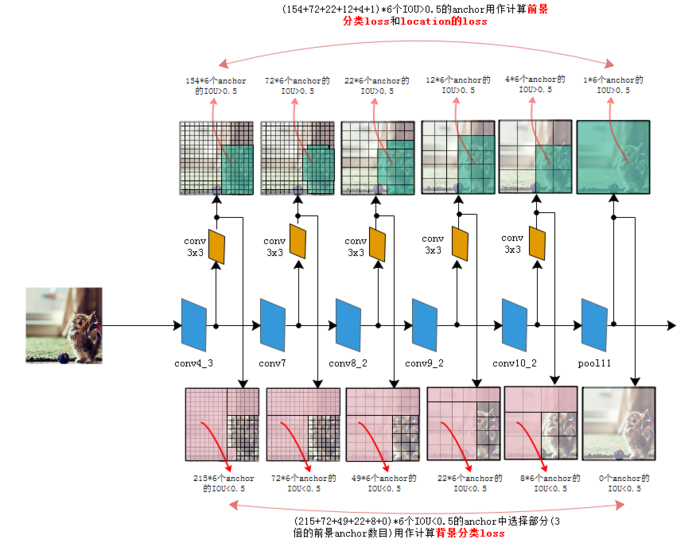
图4.SSD在6个层级上进行回归
二、优缺点
SSD的优点在前面章节已经说了:通过在不同层级选用不同尺寸、不同比例的anchor,能够找到与ground truth匹配最好的anchor来进行训练,从而使整个结构的精确度更高。
SSD的缺点是对小尺寸的目标识别仍比较差,还达不到Faster R-CNN的水准。这主要是因为小尺寸的目标多用较低层级的anchor来训练(因为小尺寸目标在较低层级IOU较大), 较低层级的特征非线性程度不够,无法训练到足够的精确度。
下图是各种目标识别结构在mAP和训练速度上的比较,可以看到SSD在其中的位置:
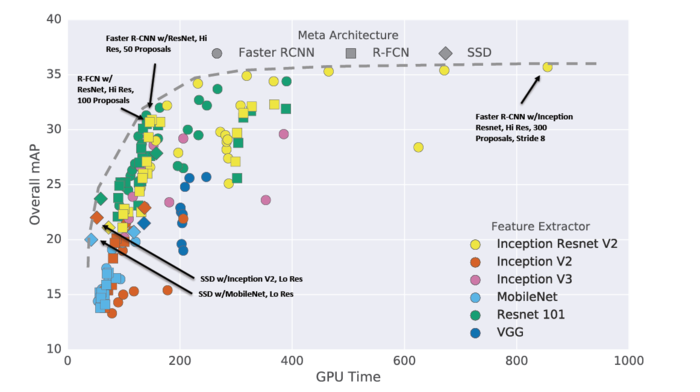
图5.各种目标检测结构的比较
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







