深度学习下人脸属性编辑
人脸属性编辑是建立在人脸识别和人脸生成基础上的应用技术,本博客将对人脸属性编辑在深度学习环境下应用做梳理。
人脸属性的基本介绍
人脸是识别和验证人物身份的重要标识,一张标准人脸包含了68个关键点,表情,年龄(年龄段),性别,种族。其中68个关键点,主要集中在人脸的中心,如下图所示:

人脸的属性在celebA的数据集下一共分为了40种属性,其中包括:
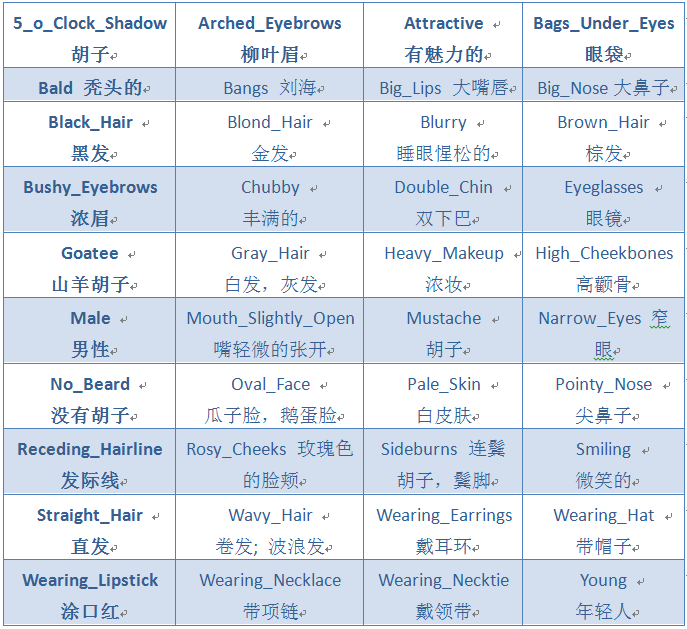
通过人脸可以得到人脸属性、判断估计年龄、性别和种族,同时人脸是代表一个人身份的最直接证明。
人脸识别和人脸增强的发展
人脸增强主要是对人脸的特征属性进行放大,使得系统对人物的分辨力得到提升,常用的人脸数据增强包括:旋转、缩放、镜像、平移、调色、噪声。人脸增强被广泛应用于人脸研究上,目前对人脸最为深入的研究是人脸识别,所谓的人脸识别就是通过对人脸的特征分析和判断从而确定人物身份信息的技术。人脸识别问题宏观上分为两类:1)人脸验证(又叫人脸比对)2)人脸识别。
人脸验证做的是 1 比 1 的比对,即判断两张图片里的人是否为同一人。最常见的应用场景便是人脸解锁,终端设备(如手机)只需将用户事先注册的照片与临场采集的照片做对比,判断是否为同一人,即可完成身份验证。人脸识别做的是 1 比 N 的比对,即判断系统当前见到的人,为事先见过的众多人中的哪一个。比如疑犯追踪,小区门禁,会场签到,以及新零售概念里的客户识别。这些应用场景的共同特点是:人脸识别系统都事先存储了大量的不同人脸和身份信息,系统运行时需要将见到的人脸与之前存储的大量人脸做比对,找出匹配的人脸。
深度学习未发展之前,人脸识别的技术主要通过分析人脸的68个关键点达到人物身份的确认。常用的方法:1)基于几何特征的人脸识别方法2)基于相关匹配的方法3)基于子空间方法4)基于统计的识别方法5)弹性图匹配方法6)K-L投影和奇异值分解(SVD)相融合的分类判别方法7)HMM和奇异值分解相融合的分类判别方法8)基于三维模型的方法。
随着深度神经网络的发展,深度学习的方法被广泛应用到人脸识别上,这也是人脸增强和人脸属性编辑的发展基础和具有借鉴意义的发展:
face++从网络上搜集了5million张人脸图片用于训练深度卷积神经网络模型,该篇文章的网路模型很常规(常规深度卷积神经网络模型)。DeepFace通过额外的3d模型改进了人脸对齐的方法。然后,通过基于4million人脸图像(4000个个体)训练的一个9层的人工神经网络来进行人脸特征表达。FR+FCN这篇文章在人脸增强做了研究,自然条件下,因为角度,光线,occlusions(咬合/张口闭口),低分辨率等原因,使人脸图像在个体之间有很大的差异,影响到人脸识别的广泛应用。作者开发了一种从个体照片中自动选择/合成canonical-view的方法。按照以下三个标准来采集个体人脸图片:1)人脸对称性(左右脸的差异)进行升序排列;2)图像锐度进行降序排列;3)将1)和2)组合。通过人脸的重建,实现了人脸增强的效果,在深度神经网络训练下得到了识别上的提高。DeepID使用了两种深度神经网络框架(VGG net 和GoogleLeNet)来进行人脸识别。FaceNet可以直接将人脸图像映射到欧几里得空间,空间的距离代表了人脸图像的相似性。只要该映射空间生成,人脸识别,验证和聚类等任务就可以轻松完成。Face Recognition via Deep Embedding提出了一种两步学习方法,结合mutil-patch deep CNN和deep metric learning,实现脸部特征提取和识别。pose+shape+expression augmentation该文章的主要思路是对数据集进行扩增,pose(姿态,文章中为人脸角度,即通过3d人脸模型数据库合成图像看不见的角度,生成新的角度的人脸)。首先,通过人脸特征点检测(facial landmark detector),获取人脸特征点。根据人脸特征点和开放的Basel 3D face set数据库的人脸模板合成3d人脸。shape(脸型)。首先,通过Basel 3D face获取10种高质量3d面部扫描数据。再将图像数据与不同3d脸型数据结合,生成同一个人不同脸型的图像。expression(表情,本文中,将图像的张嘴表情替换为闭口表情)。采用中性嘴型将图像中的开口表情换位闭口表情。这是人脸增强的新阶段的方法。CNN-3DMM estimation当在真实场景中应用3d模拟来增加人脸识别精度,存在两类问题:要么3d模拟不稳定,导致同一个个体的3d模拟差异较大;要么过于泛化,导致大部分合成的图片都类似。因此,作者研究了一种鲁棒的三维可变人脸模型(3D morphable face models (3DMM))生成方法。他们采用了卷积神经网络(CNN)来根据输入照片来调节三维人脸模型的脸型和纹理参数。该方法可以用来生成大量的标记样本。
随着深度神经网络的发展,目前比较好的人脸识别方法,都是以人脸增强为基础进行模型训练,往往需要对人脸进行3D生成,增强模型的鲁棒性。
人脸属性编辑
人脸属性编辑旨在操纵面部图像的单个或多个属性,即生成具有所需属性的新面部,同时保留其他细节。人脸属性编辑是建立在人脸生成上展开的,当然利用人脸关键点去控制人脸也是可以实现人脸的属性编辑,但那样往往会带来人脸的扭曲和不对称出现。随着生成模型的发展,人脸属性编辑得到了长足的发展,生成对抗网络更是实现了图像在一个域中映射到另一个域中,以此带来了人脸属性编辑优质论文的涌现,接下来将对近几年人脸属性编辑主流方法进行介绍。
AttGAN不是对潜在表示施加约束,而是对生成的图像应用属性分类约束,以保证所需属性的正确变化。同时,引入重建学习以保留属性排除细节。
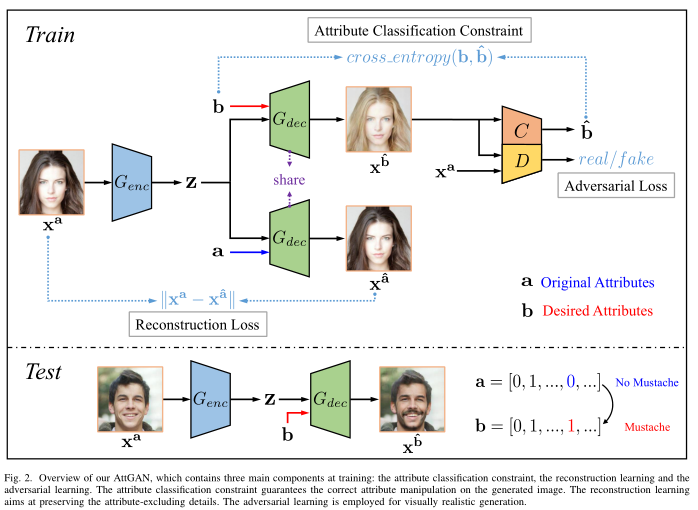
模型通过控制属性标签,利用属性标签去监督性的去编辑人脸,在训练阶段利用重构误差、标签分类误差、对抗损失实现了标签对应人脸属性的人脸编辑。类似这个思想,CycleGAN可固定实现A-B的模态转换,但是不能解决多领域迁移的问题。StarGAN只用一个generator网络,处理多个domain之间互相generate图像的问题,这是比AttGAN更深一步的人脸属性迁移。
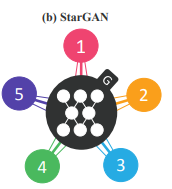
对于StarGAN的生成器G的输入除了图片,还有domain的label,对应的生成图片变到指定的domain,这很像是在CycleGAN上加了conditional 的输入。StarGAN的结构就可以理解成在CycleGAN的基础上添加了条件(模态的信息),整体的训练结构也是如此:
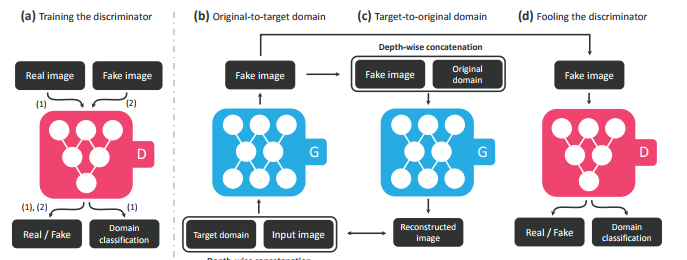
当然,这里的条件是可以叠加输入的,对应在人脸属性编辑上就是可以同时控制几个属性的编辑效果:

利用属性标签对人脸属性编辑是该方法的一种实现,RSGAN提出称为区域分离生成对抗网络,通过独立地处理潜在空间中的面部和头发外观,然后,通过替换面部的潜在空间表示来实现面部交换,并且用它们重建整个面部图像。文章的一大手段就是将面部和头发进行分离:
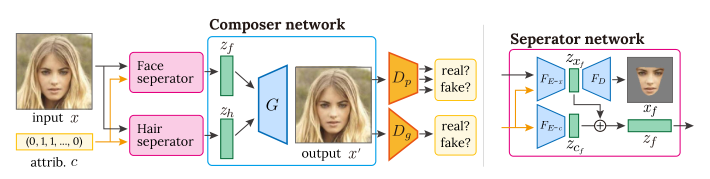
通过面部和头发的分离,再通过属性条件的控制,Zf和Zh分别为面部和头发的潜在空间,这也提供给网络更多的能力去实现类似于换脸和换头发的操作从而实现了人脸属性编辑。
SGGAN提出了一种新颖的分段引导生成对抗网络,它利用语义分割来进一步提高生成性能并提供空间映射。特别地,分段器网络被设计为对生成的图像施加语义信息。

通过输入图像,结合语义分割的目标,比如是微笑和大笑的目标,在网络中再次加入属性标签生成出指定的图像,整个过程可由下图分析:
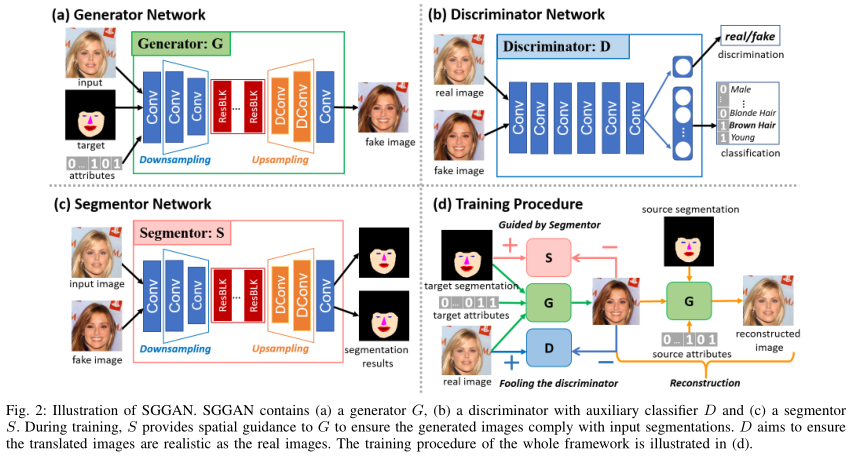
最终控制人脸编辑的输入有3个,原始人脸、语义分割的目标表情和属性的标签信息,最终生成出目标人脸。通过语义分割的分割图为人脸编辑提供了更加自由的人为操作,可以进一步的刻画人物的面部,而不是死板的在属性标签上实现人脸属性编辑。
SC-FEGAN在人脸编辑上又进了一步,通过自由形式的原始图片、草图、掩码图、颜色图、噪声的共同输入网络实现了人脸自由的编辑。这样实现的人脸属性编辑将不再局限于属性标签,而是将人脸编辑的自由权交由使用者,通过联合输入和SN-patchGAN的作用,最终实现人脸属性编辑。详细解读可参看此篇博客。

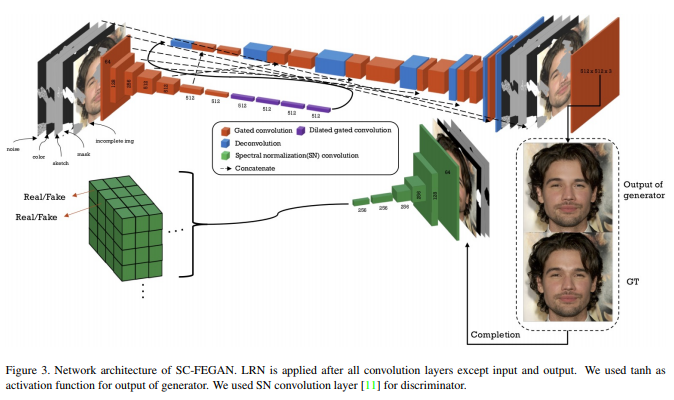
正是草图、颜色图和掩码图的作用才可以指导人脸按照使用者的绘制来实现人脸面部编辑的效果。

总结
面部增强和属性编辑是人脸识别和人脸特征提取下发展产物,通过人脸增强可以提高模型的鲁棒性以及因数据集自身的问题导致的人脸识别和编辑任务的不完善。人脸属性编辑往往是建立在人脸生成上,可以提供人脸的自由化属性变换,随着人脸属性编辑的发展,使用者可以更加自由的控制面部编辑。
实现面部编辑的方法由单纯的属性标签控制,到面部头发分离下的人脸和头发的变换,再到语义分割下更加自由的人脸生成,最后是草图作用下人脸的任意编辑的实现。

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







